【小白CV教程】Pytorch训练YOLOv5并量化压缩(VOC格式数据集)
本文禁止转载
前言:
今天有时间,就写一下用yolov5训练自己数据集(自己标注的VOC格式),然后通过pytorch接口进行模型的量化压缩。
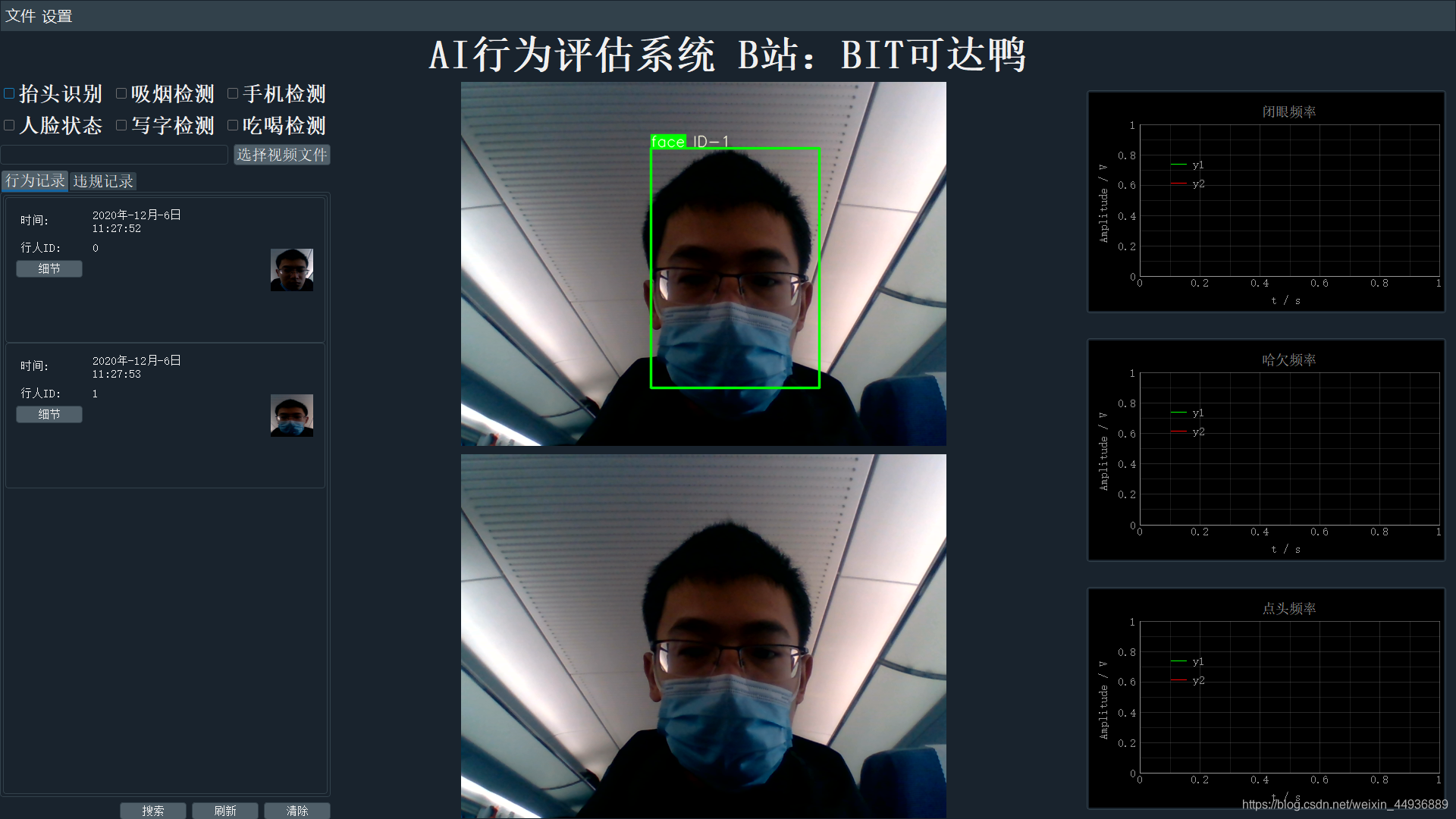
最终效果:
1. 安装Anaconda:
Anaconda官网:https://www.anaconda.com/
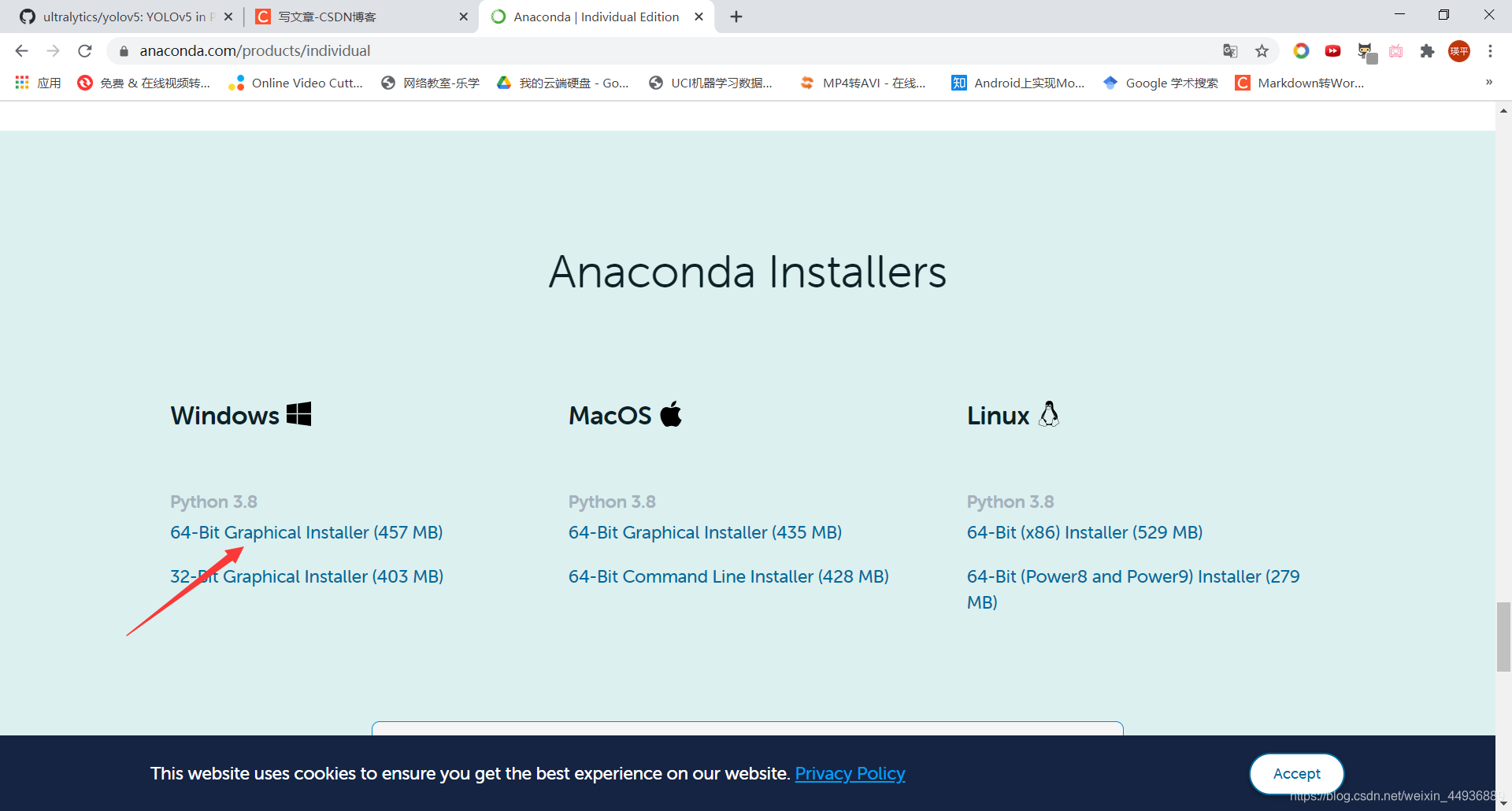
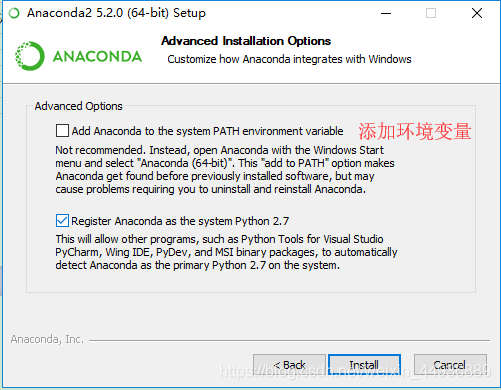
下载完成后打开一路Yes即可,只需要注意这里要将conda添加到PATH:
安装完成后打开cmd:
输入conda -V,查看是否安装成功:
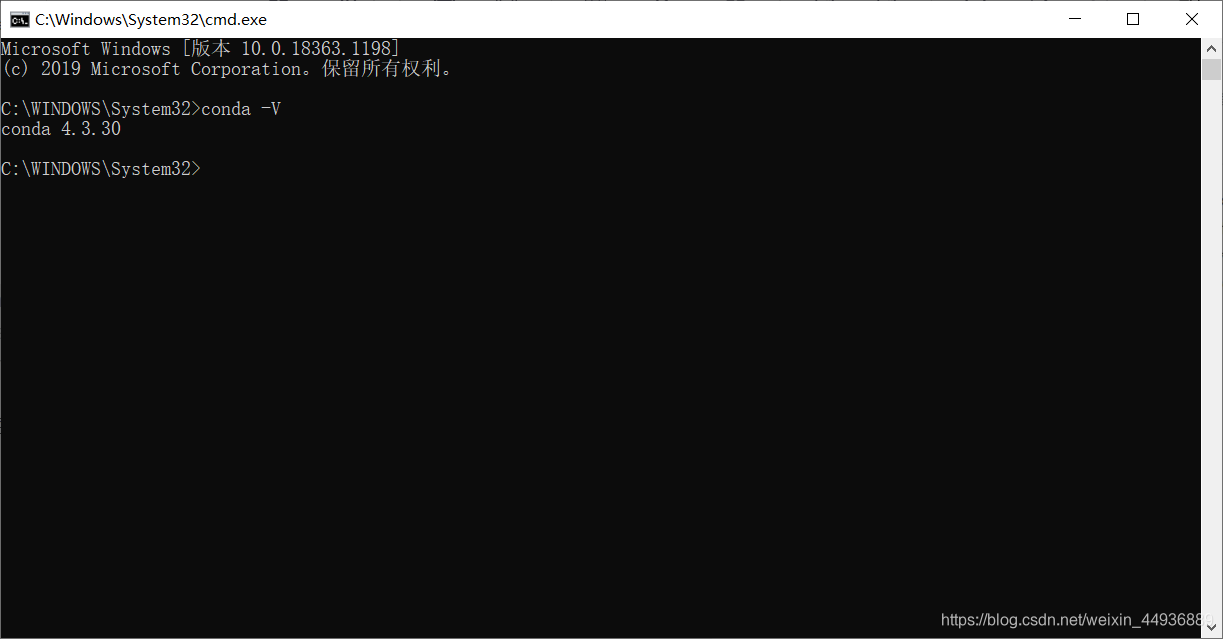
出现版本号即为安装成功。
2. 创建虚拟环境:
这里我们需要为yolov5单独创建一个环境,输入:
conda create -n torch107 python=3.7
选y:
等待相关库安装:
安装完成后,输入:
activate torch107
激活环境:
3. 安装pytorch:
yolov5最新版本需要pytorch1.6版本以上,因此我们安装pytorch1.7版本。由于我事先安装好了CUDA10.1,因此在环境中输入:
pip install torch==1.7.0+cu101 torchvision==0.8.1+cu101 torchaudio===0.7.0 -f https://download.pytorch.org/whl/torch_stable.html
即可安装:
然后查看CUDA是否可用:
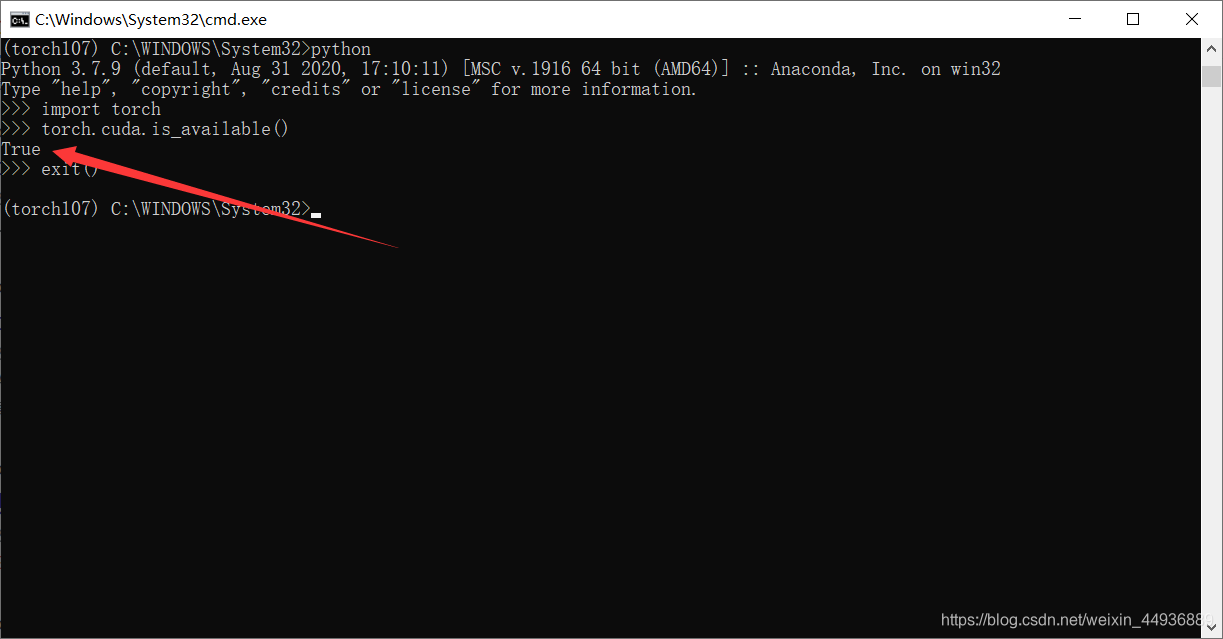
这里显示True表明正常安装。
4. 下载源码和安装依赖库:
源码地址:https://github.com/ultralytics/yolov5
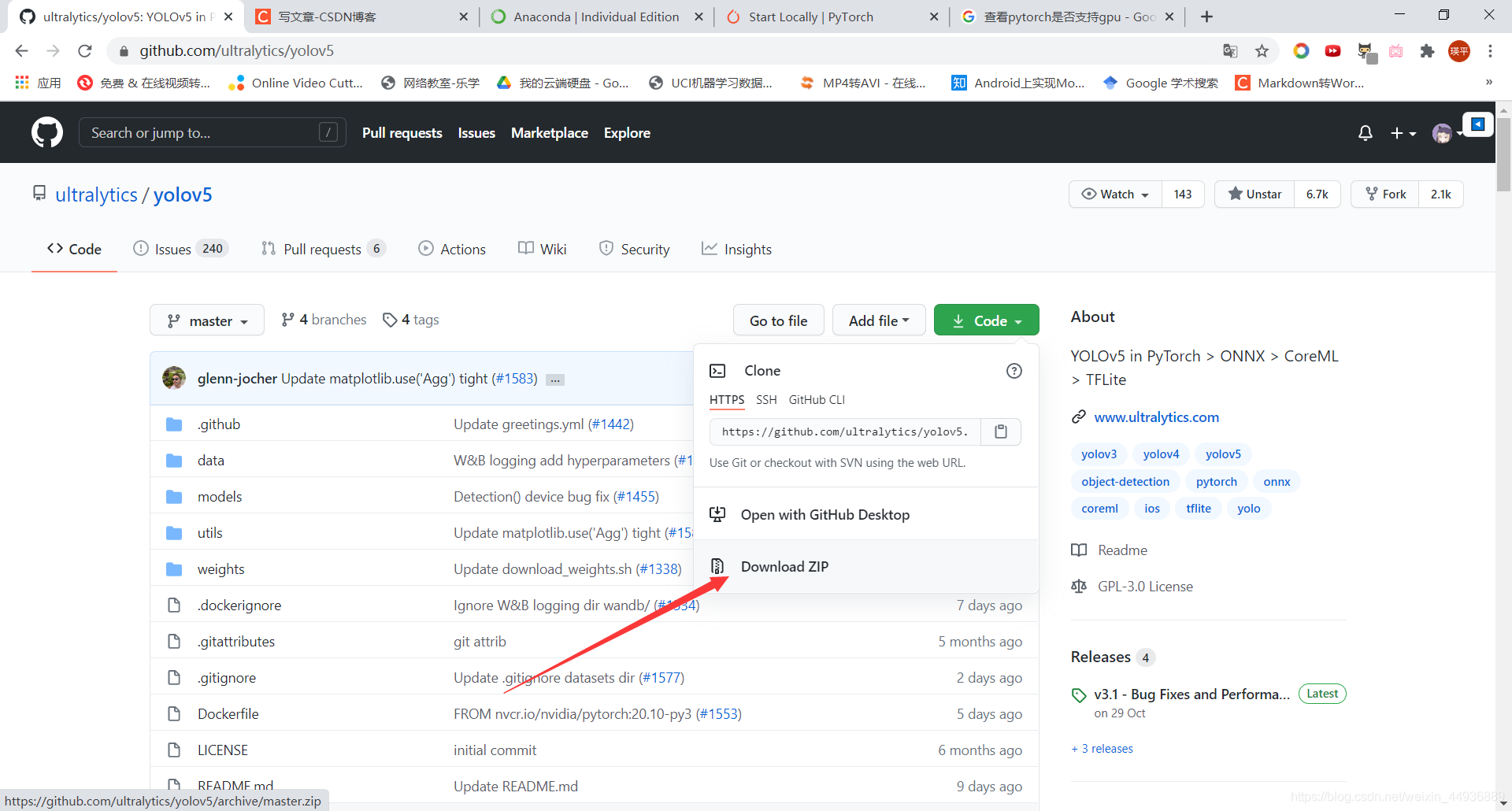
下载后解压,在目录内打开cmd并激活环境:
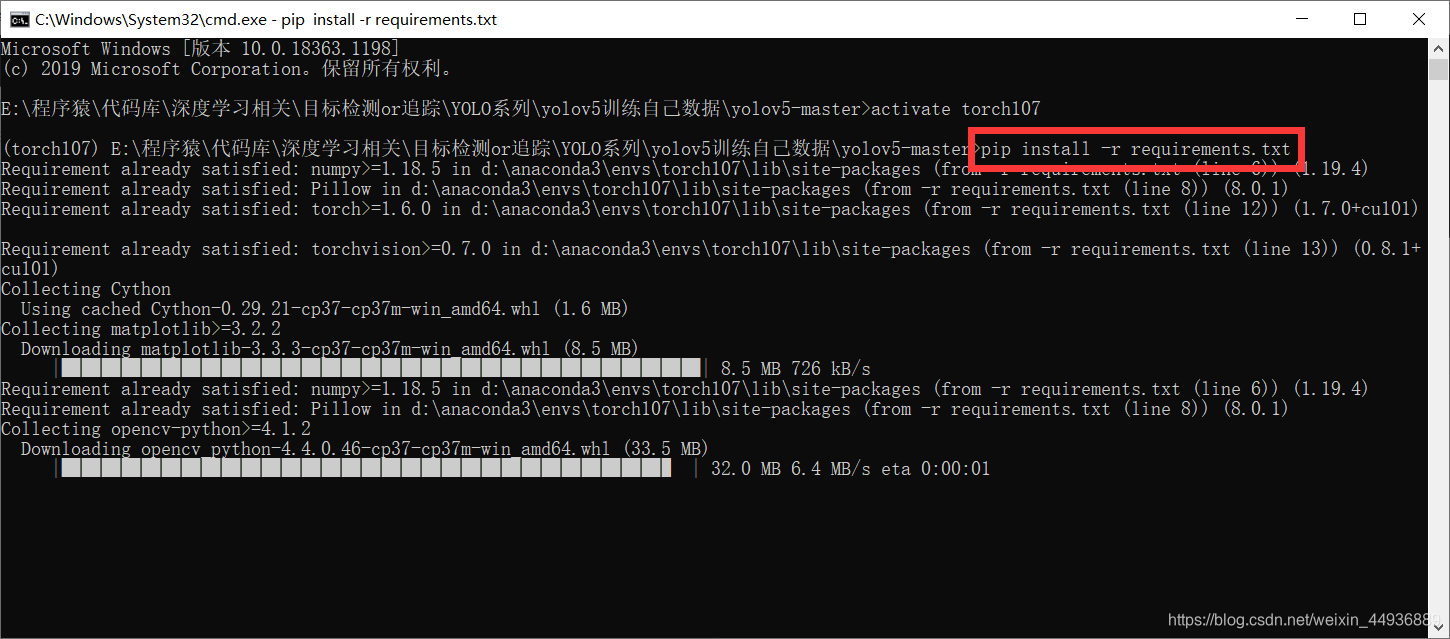
安装依赖库:
pip install -r requirements.txt
5. 数据标注:
数据标注我们要用labelimg,使用pip即可安装:
pip install labelimg
这里我用百度爬虫爬取图像:
代码:
import os
import re
import sys
import urllib
import json
import socket
import urllib.request
import urllib.parse
import urllib.error
# 设置超时
from random import randint
import time
timeout = 5
socket.setdefaulttimeout(timeout)
class Crawler:
# 睡眠时长
__time_sleep = 0.1
__amount = 0
__start_amount = 0
__counter = 0
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
__per_page = 30
# 获取图片url内容等
# t 下载图片时间间隔
def __init__(self, t=0.1):
self.time_sleep = t
# 获取后缀名
@staticmethod
def get_suffix(name):
m = re.search(r'\.[^\.]*$', name)
if m.group(0) and len(m.group(0)) <= 5:
return m.group(0)
else:
return '.jpeg'
# 保存图片
def save_image(self, rsp_data, word):
if not os.path.exists("./" + word):
os.mkdir("./" + word)
# 判断名字是否重复,获取图片长度
self.__counter = len(os.listdir('./' + word)) + 1
for image_info in rsp_data['data']:
try:
if 'replaceUrl' not in image_info or len(image_info['replaceUrl']) < 1:
continue
obj_url = image_info['replaceUrl'][0]['ObjUrl']
thumb_url = image_info['thumbURL']
url = 'https://image.baidu.com/search/down?tn=download&ipn=dwnl&word=download&ie=utf8&fr=result&url=%s&thumburl=%s' % (
urllib.parse.quote(obj_url), urllib.parse.quote(thumb_url))
time.sleep(self.time_sleep)
suffix = self.get_suffix(obj_url)
# 指定UA和referrer,减少403
opener = urllib.request.build_opener()
opener.addheaders = [
('User-agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'),
]
urllib.request.install_opener(opener)
# 保存图片
filepath = './{}/PME_{}_A{}'.format(word, randint(
1000000, 500000000), str(self.__counter) + str(suffix))
for _ in range(5):
urllib.request.urlretrieve(url, filepath)
if os.path.getsize(filepath) >= 5:
break
if os.path.getsize(filepath) < 5:
print("下载到了空文件,跳过!")
os.unlink(filepath)
continue
except urllib.error.HTTPError as urllib_err:
print(urllib_err)
continue
except Exception as err:
time.sleep(1)
print(err)
print("产生未知错误,放弃保存")
continue
else:
print("图+1,已有" + str(self.__counter) + "张图")
self.__counter += 1
return
# 开始获取
def get_images(self, word):
search = urllib.parse.quote(word)
# pn int 图片数
pn = self.__start_amount
while pn < self.__amount:
url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%s&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=&hd=&latest=©right=&word=%s&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=%s&rn=%d&gsm=1e&1594447993172=' % (
search, search, str(pn), self.__per_page)
# 设置header防403
try:
time.sleep(self.time_sleep)
req = urllib.request.Request(url=url, headers=self.headers)
page = urllib.request.urlopen(req)
rsp = page.read()
except UnicodeDecodeError as e:
print(e)
print('-----UnicodeDecodeErrorurl:', url)
except urllib.error.URLError as e:
print(e)
print("-----urlErrorurl:", url)
except socket.timeout as e:
print(e)
print("-----socket timout:", url)
else:
# 解析json
try:
rsp_data = json.loads(rsp)
self.save_image(rsp_data, word)
# 读取下一页
print("下载下一页")
pn += 60
except Exception as e:
continue
finally:
page.close()
print("下载任务结束")
return
def start(self, word, total_page=2, start_page=1, per_page=30):
"""
爬虫入口
:param word: 抓取的关键词
:param total_page: 需要抓取数据页数 总抓取图片数量为 页数 x per_page
:param start_page:起始页码
:param per_page: 每页数量
:return:
"""
self.__per_page = per_page
self.__start_amount = (start_page - 1) * self.__per_page
self.__amount = total_page * self.__per_page + self.__start_amount
self.get_images(word)
if __name__ == '__main__':
crawler = Crawler(0.05) # 抓取延迟为 0.05
crawler.start('玩手机')
cmd输入labelimg打开标注软件:

打开后选取图像所在文件夹,进行标注:
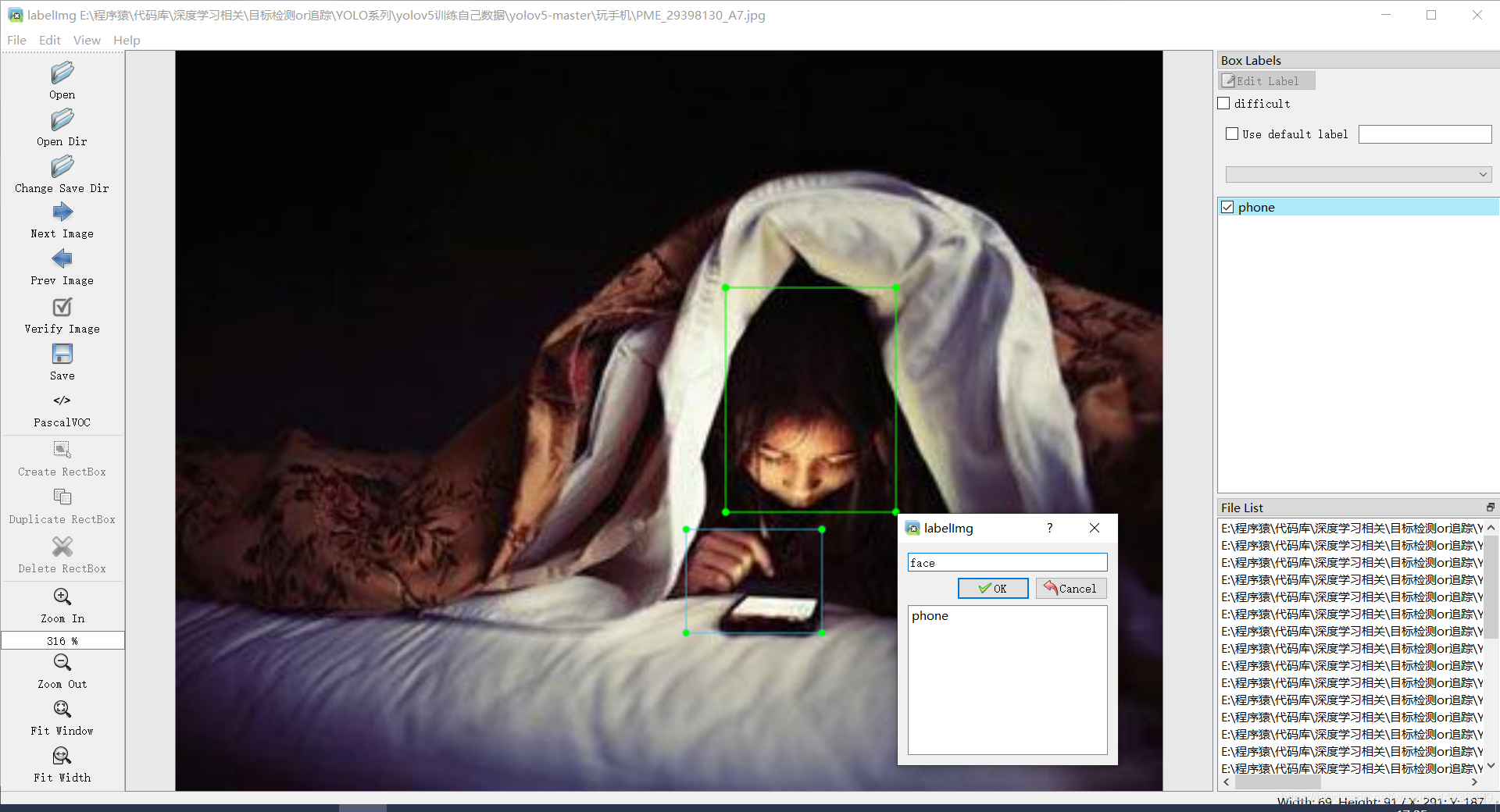
标注完成后,每张图像会生成对应的xml标注文件:
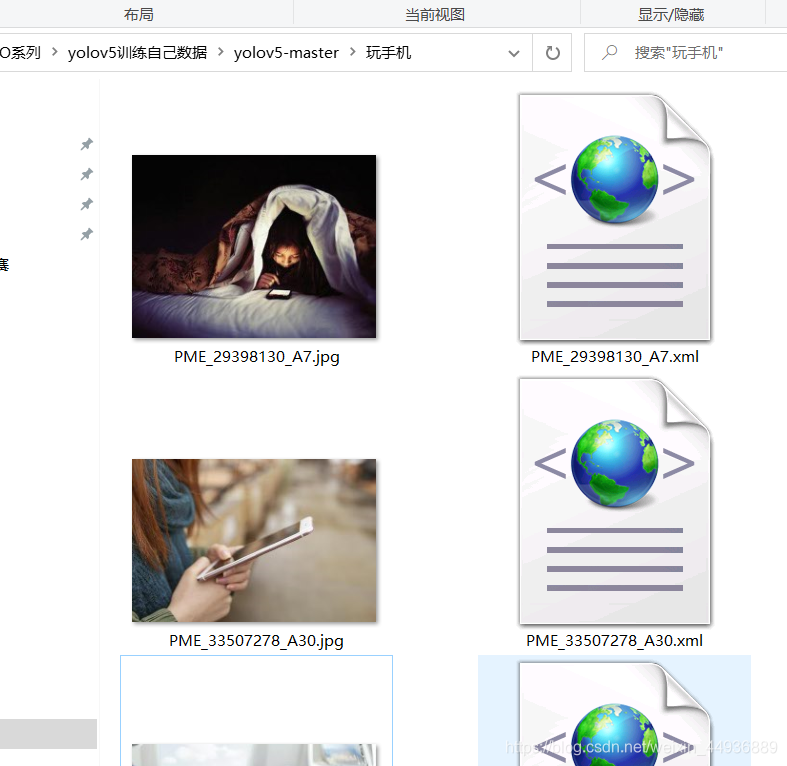
我们将图像和标注文件统一放置到源码目录的VOCData/images文件夹下。
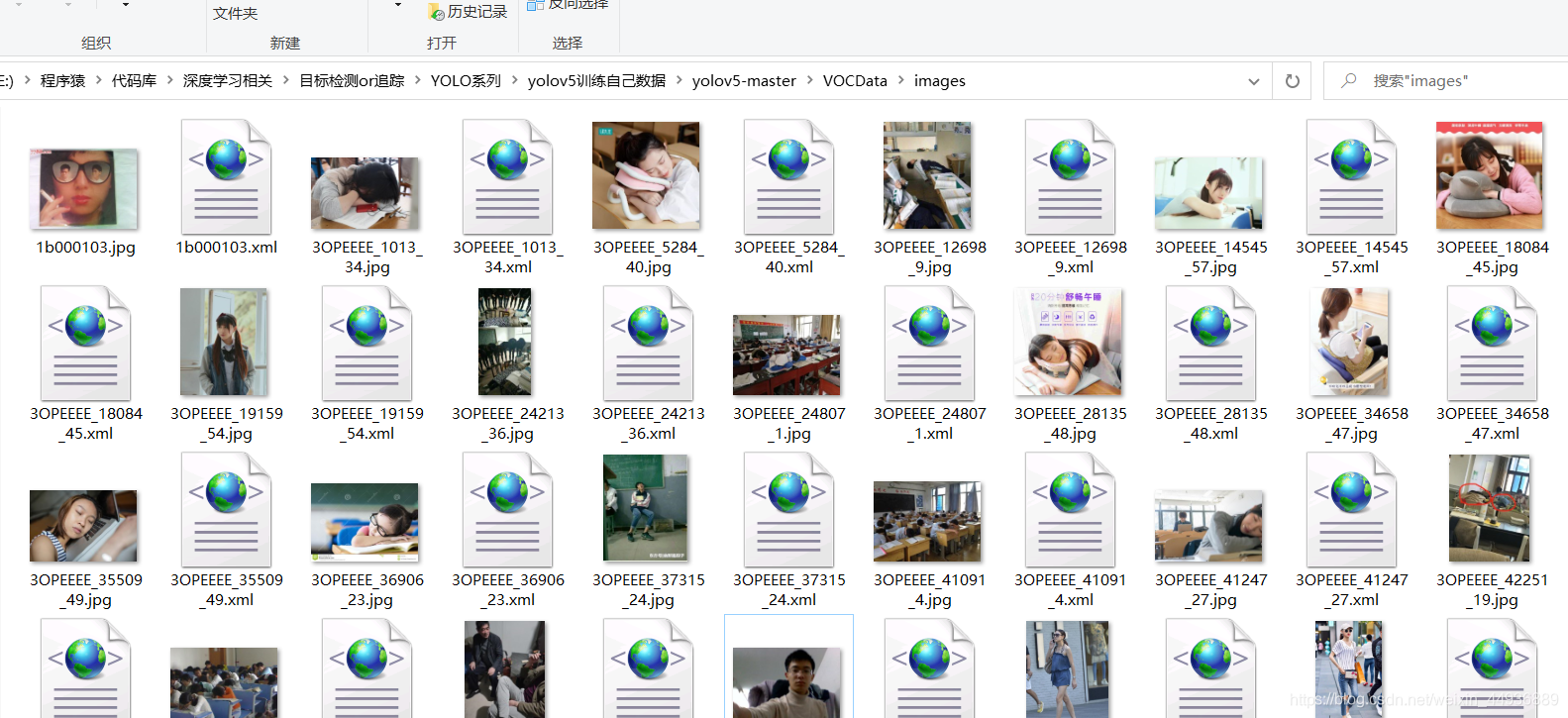
5. 数据预处理:
创建 convert_data.py 文件,内容如下:
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
from tqdm import tqdm
import os
from os import getcwd
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
# try:
in_file = open('VOCData/images/{}.xml'.format(image_id), encoding='utf-8')
out_file = open('VOCData/labels/{}.txt'.format(image_id),
'w', encoding='utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " +
" ".join([str(a) for a in bb]) + '\n')
# except Exception as e:
# print(e, image_id)
if __name__ == '__main__':
sets = ['train', 'val']
image_ids = [v.split('.')[0]
for v in os.listdir('VOCData/images/') if v.endswith('.xml')]
split_num = int(0.95 * len(image_ids))
classes = ['face', 'normal', 'phone', 'write',
'smoke', 'eat', 'computer', 'sleep']
if not os.path.exists('VOCData/labels/'):
os.makedirs('VOCData/labels/')
list_file = open('train.txt', 'w')
for image_id in tqdm(image_ids[:split_num]):
list_file.write('VOCData/images/{}.jpg\n'.format(image_id))
convert_annotation(image_id)
list_file.close()
list_file = open('val.txt', 'w')
for image_id in tqdm(image_ids[split_num:]):
list_file.write('VOCData/images/{}.jpg\n'.format(image_id))
convert_annotation(image_id)
list_file.close()
运行结束后,可以看到VOCData/labels下生成了对应的txt文件:
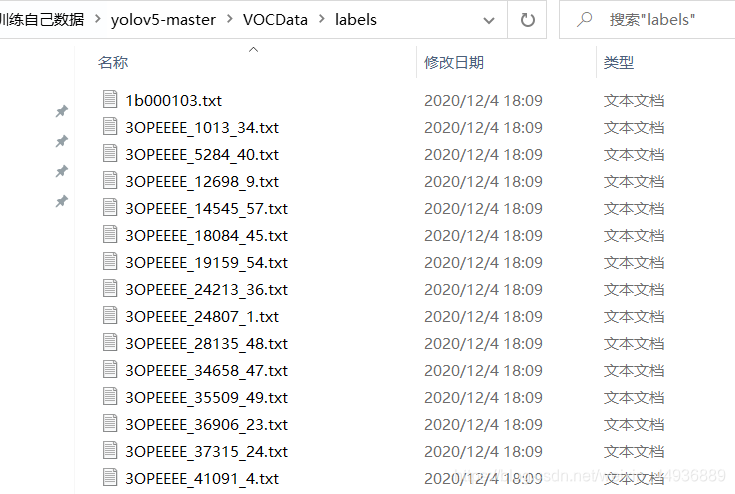
在data文件夹下创建myvoc.yaml文件:
内容如下:
train: train.txt
val: val.txt
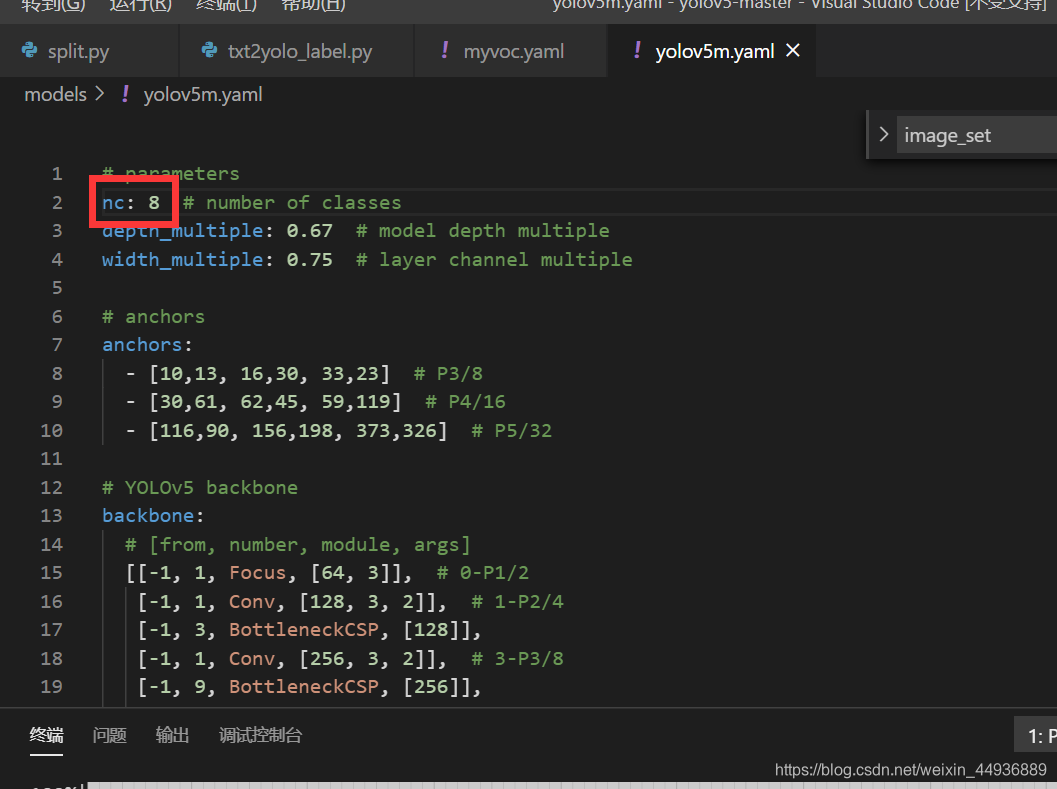
# number of classes
nc: 8
# class names
names: ["face", "normal", "phone", "write", "smoke", "eat", "computer", "sleep"]
6. 下载预训练模型:
我训练yolov5m这个模型,因此将它的预训练模型下载到weights文件夹下:
7. 开始训练:
修改models/yolov5m.yaml下的类别数:
然后在cmd中输入:
python train.py --img 640 --batch 4 --epoch 300 --data ./data/myvoc.yaml --cfg ./models/yolov5m.yaml --weights weights/yolov5m.pt --workers 0
即可开始训练:
8. 模型推理测试:
训练结束后在 run/train/exp/weights 文件夹下会生成训练好的两个模型文件,我们将 last.pt 取出放到根目录下,然后运行:
python detect.py --source data/images --weights last.pt --conf 0.25
其中 data/images 为我们测试图片的路径。
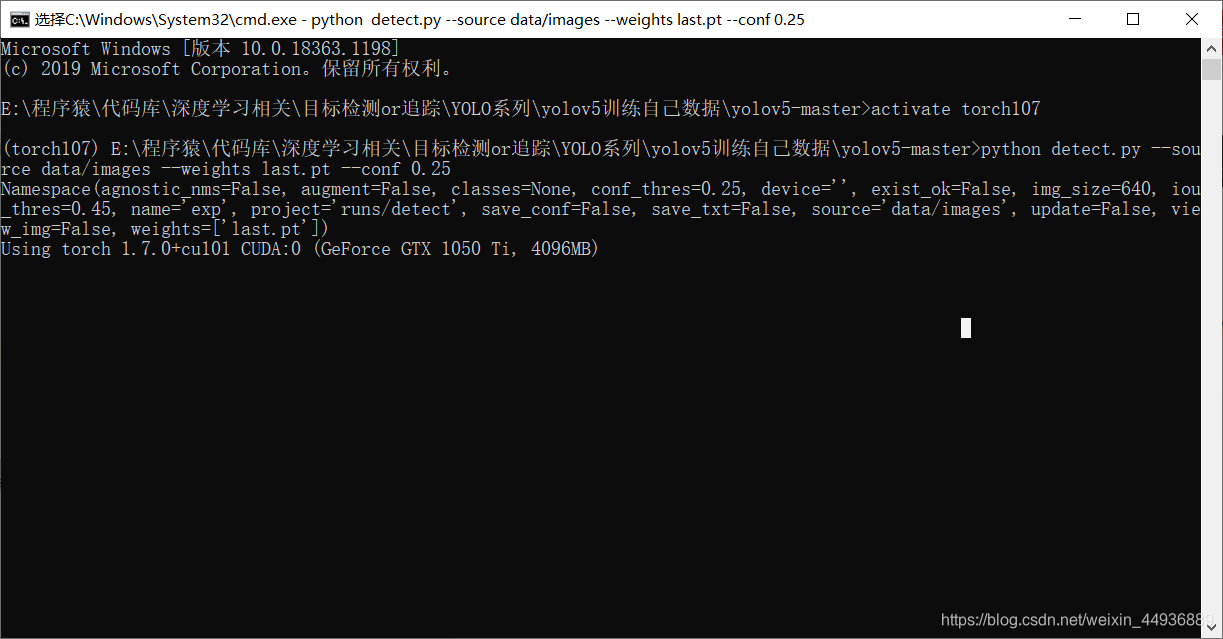
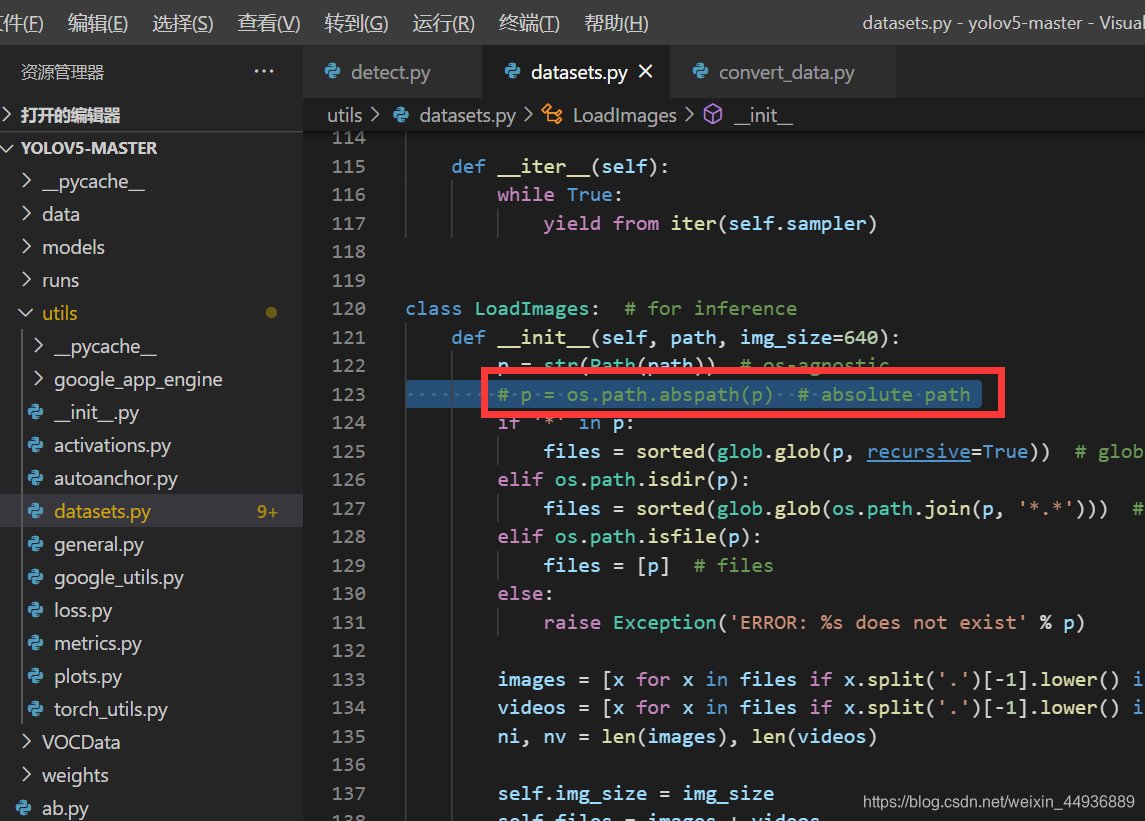
注意如果有中文路径,需要把 utils/datasets.py 的这一句注释掉:
结果如图:

9. 模型量化:
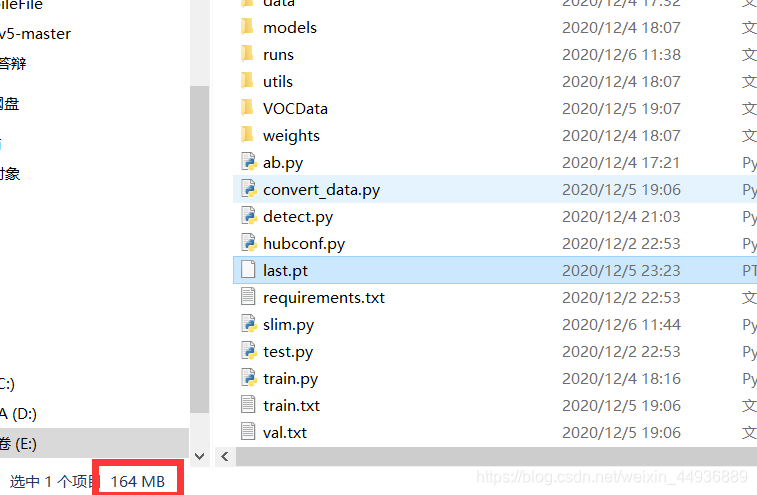
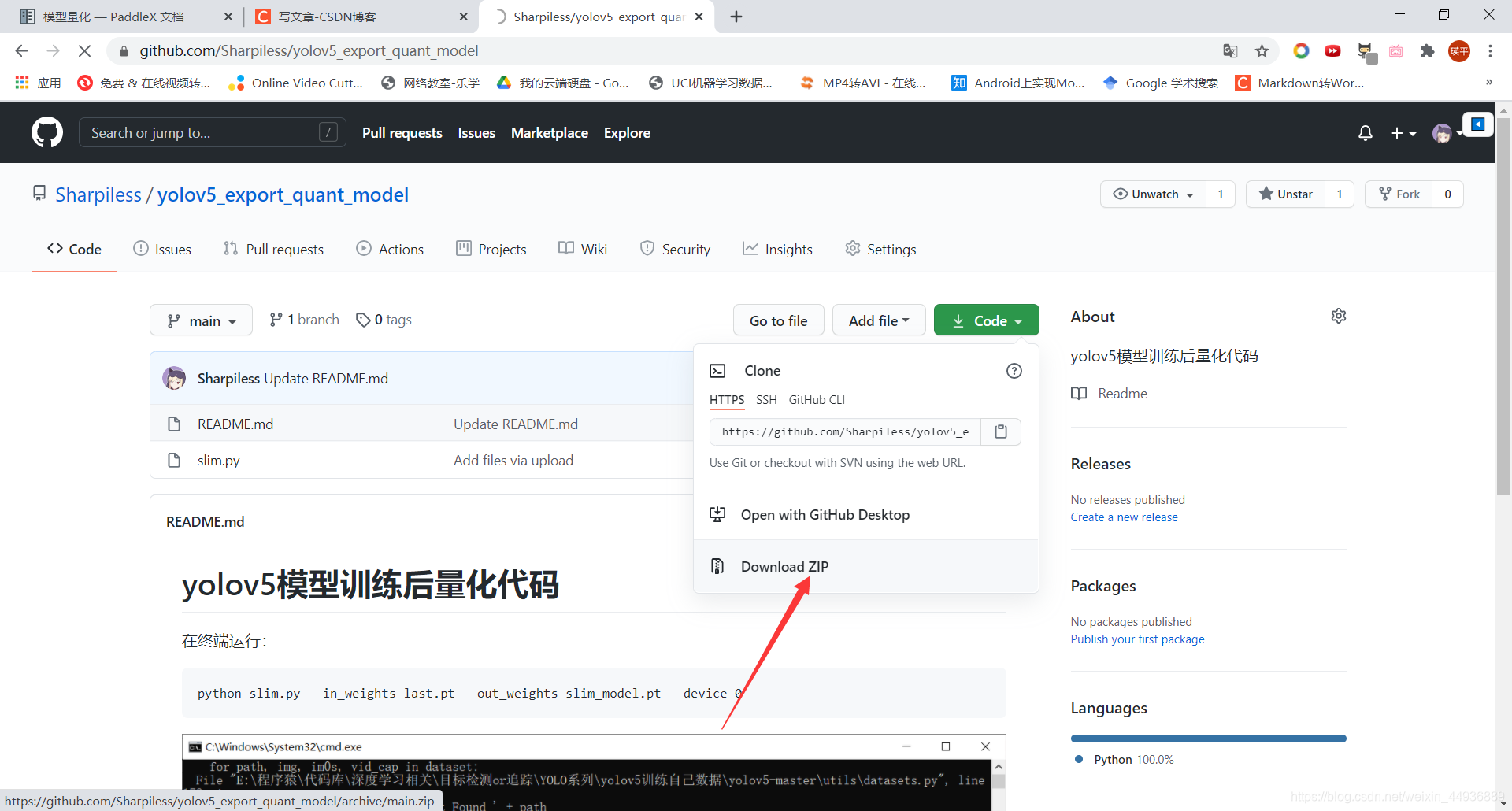
这时我们注意到,训练好的 last.pt 有172MB,而官方给出的 yolov5m.pt 只有 40MB,这时候我们需要导出半精度模型重新保存,转换代码我放到了 Github:
https://github.com/Sharpiless/yolov5_export_quant_model
下载源码:
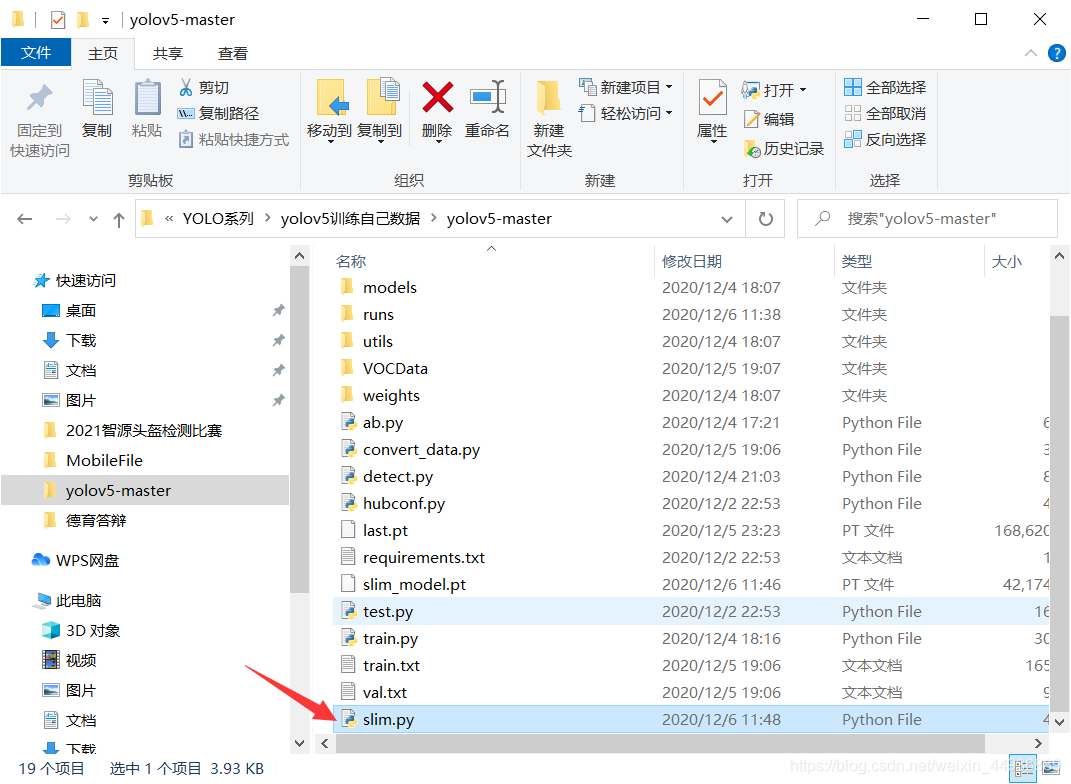
将 slim.py 放到源码根目录:
在终端运行:
python slim.py --in_weights last.pt --out_weights slim_model.pt --device 0
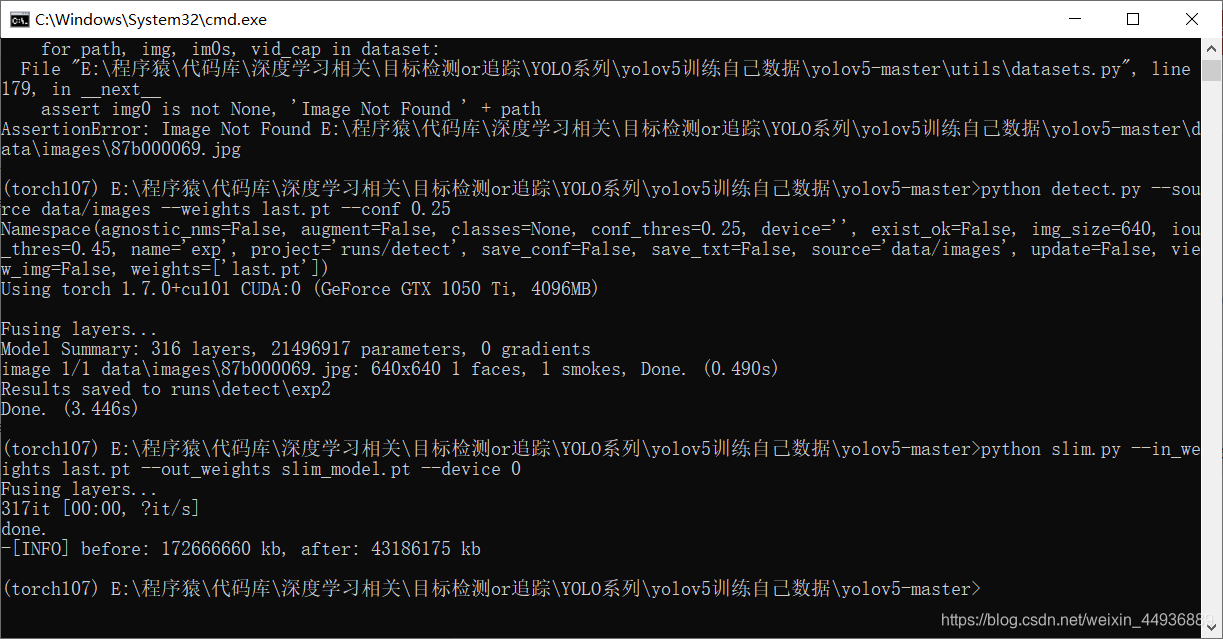
可以看到权重文件压缩到了 43 MB。
关注我的公众号:
感兴趣的同学关注我的公众号——可达鸭的深度学习教程:
