更新提醒
2023.04.01最新更新
1、修改了VOC数据集划分和转YOLO格式处理部分下第2部分数据集划分的split_train_val.py代码,也不算修改,是感觉新的更加方便调节划分比例。
前言
YOLOv5官方使用的数据集是COCO数据集格式,个人准备改用 PASCAL VOC 数据集进行训练测试,以下是VOC数据集划分及格式转换的一些过程记录在此,便日后回顾。
本博文主要适用于 xml格式转txt 并按比例划分训练集、验证集、测试集
VOC数据集介绍
VOC数据集主要分为:VOC2007、VOC2012。
下载地址:
1、Darknet网站的地址:VOC数据集下载地址
2、PASCAL官网的地址:VOC2007、VOC2012
格式介绍:
下载VOC数据集,解压后,文件夹内容如下:
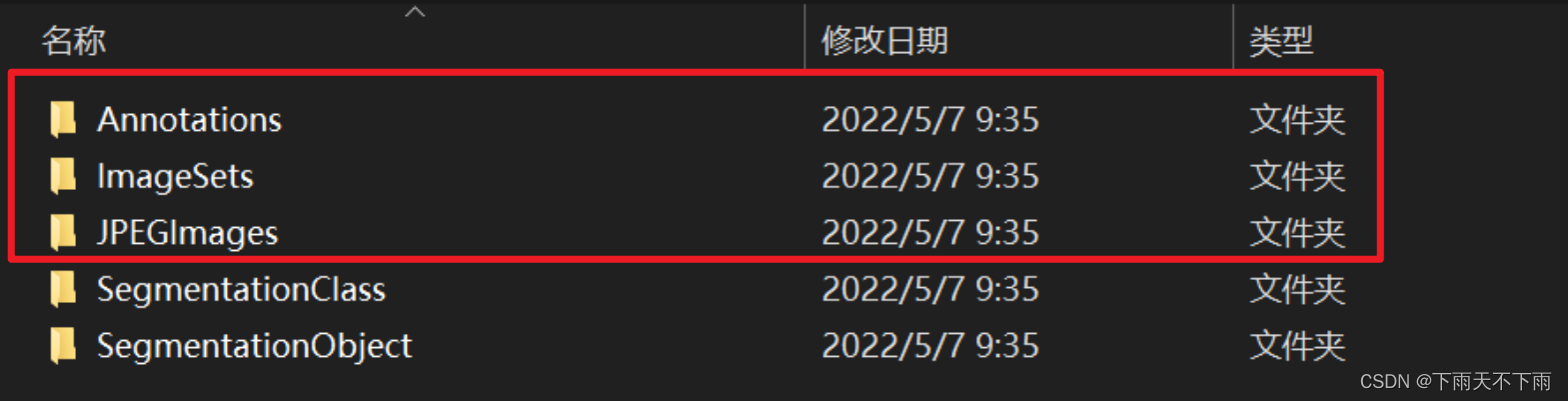
一般目标检测只需用到Annotations、ImageSets、JPEGImages这3个文件夹,剩下的可以删掉。
Annotations:存放所有图片的标注xml文件;
ImageSets:文件夹下有3个子文件夹:Layout、Main、Segmentation,我们只用到Main文件夹,其他可以删掉。下面看一下Main文件夹下的内容:

Main文件夹下有20个类别的×××_train.txt、×××_trainval.txt、×××_val.txt(其实删掉也可以,不影响)。我们只要保留并关注三个文件(黄色框):train.txt、val.txt、trainval.txt (训练集、验证集、训练集+验证集的总和)。其实可以把Main文件夹下内容全删了,只留空文件夹。
JPEGImages:存放所有的图片,图片顺序及名称和xml文件是一一对应的。
以上操作做完之后,文件夹的结构呈下图形式;
VOCdevkit
————VOC2007
————Annotations # 存放图片对应的xml文件,与JPEGImages图片一一对应
————ImageSets
————Main # 存放trainval.txt、train.txt、val.txt、test.txt
————JPEGImages # 存放所有图片文件
VOC数据集划分和转YOLO格式处理
YOLOv5训练用的是COCO数据集,并且YOLO的数据格式和VOC格式有不同。VOC是通过xml文件读取数据,yolo是通过txt文件读取数据(类别和坐标信息)
VOC数据集信息:
VOC2007总共有9963张图片有标注,其中训练集和验证集5011张图片,测试集4952张图片。
VOC2012总共有17125张图片有标注,即训练集+验证集(train+val)一共包含17125张图片。但是!重点,官方划分的能用于目标检测图片的只有11540张图片,其他是没用的。所以我们常说,VOC2012有11540张图片,VOC2012并没有公开测试集标注。
参考顶会论文,通常训练VOC对比,把07和12合成一个数据集,把VOC2012全部图片11540张作为训练集,然后VOC2007的训练集+验证集图片5011张作为验证集,VOC2007的测试集4952张图片作为总的测试集
下面介绍如何将VOC转换为yolo格式,通过python脚本可以很好实现转换。
1、首先,按照上面介绍的,下载数据集,解压数据集,处理文件夹,该留的留,该删的删掉(注意:PASCAL官网上训练集和验证集是一起下载的,但测试集是要单独下载的。如果需要测试集,就单独下载下来,然后手动将测试集下的JPEGImages文件夹(图片)、Annotations文件夹(标注xml文件)和Main文件夹(txt文件)下的所有内容,直接复制剪切到训练集同样目录文件夹下,形成一个完整的数据集)。
2、数据集划分:在 VOCdevkit 所在目录创建split_train_val.py,运行之后会在Main文件夹下生成四个txt文件:train.txt、val.txt、test.txt、trainval.txt
自己处理数据集,自己设置训练集和测试集的比例,先把Main文件夹下的所有内容清空,然后运行split_train_val.py代码,之后就会按照自己设置的比例(代码里有设置比例),在Main下自动生成需要的四个.txt文件。
老版本代码如下:
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='VOCdevkit/VOC2007/Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='VOCdevkit/VOC2007/ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 0.8 # 训练+验证集一共所占的比例为0.8(注意看清楚),剩下的0.2就是测试集
train_percent = 0.8 # 训练集在训练集和验证集总集合中占的比例(注意看清楚是谁占谁的比例),可自己进行调整
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
2022/09/11添加新版本代码如下:
# -*- coding: utf-8 -*-
"""
Author:smile
Date:2022/09/11 10:00
顺序:脚本A1
简介:分训练集、验证集和测试集,按照 8:1:1 的比例来分,训练集8,验证集1,测试集1
"""
import os
import random
import argparse
parser = argparse.ArgumentParser()
# xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='Annotations/', type=str, help='input xml label path')
# 数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='Main/', type=str, help='output txt label path')
opt = parser.parse_args()
train_percent = 0.8 # 训练集所占比例
val_percent = 0.1 # 验证集所占比例
test_persent = 0.1 # 测试集所占比例
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list = list(range(num))
t_train = int(num * train_percent)
t_val = int(num * val_percent)
train = random.sample(list, t_train)
num1 = len(train)
for i in range(num1):
list.remove(train[i])
val_test = [i for i in list if not i in train]
val = random.sample(val_test, t_val)
num2 = len(val)
for i in range(num2):
list.remove(val[i])
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
for i in train:
name = total_xml[i][:-4] + '\n'
file_train.write(name)
for i in val:
name = total_xml[i][:-4] + '\n'
file_val.write(name)
for i in list:
name = total_xml[i][:-4] + '\n'
file_test.write(name)
file_train.close()
file_val.close()
file_test.close()
3、VOC转YOLO格式:第2步只是把数据集划分了比例,想训练,还要进行这一步。在VOCdevkit目录下创建voc_label.py,点击运行,会在目录下生成新的labels文件夹,把数据集路径导入txt文件,将每个xml标注信息提取转换为了txt格式,每个图像对应一个txt文件。(代码都是测试过很多遍,可以保证没有问题!注意一点的是,VOC存放图片的文件夹是JPEGImages,但是YOLO中读取图片是到 images 中读取的,所以,这里要把JPEGImages改为images(或者你在YOLO代码里面改,下面有示范,这样比较麻烦,不太友好)再运行代码。我演示的时候,并没有修改,我是在YOLO里面改的,不建议,看到这的小伙伴记得修改!!!)
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
sets = ['train', 'val', 'test'] # 如果你的Main文件夹没有test.txt,就删掉'test'
# classes = ["a", "b"] # 改成自己的类别,VOC数据集有以下20类别
classes = ["aeroplane", 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog',
'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'] # class names
abs_path = os.getcwd()
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open(abs_path + '/VOCdevkit/VOC2007/Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open(abs_path + '/VOCdevkit/VOC2007/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
# difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
for image_set in sets:
if not os.path.exists(abs_path + '/VOCdevkit/VOC2007/labels/'):
os.makedirs(abs_path + '/VOCdevkit/VOC2007/labels/')
image_ids = open(abs_path + '/VOCdevkit/VOC2007/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open(abs_path + '/VOCdevkit/VOC2007/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '/VOCdevkit/VOC2007/JPEGImages/%s.jpg\n' % (image_id)) # 要么自己补全路径,只写一半可能会报错
convert_annotation(image_id)
list_file.close()
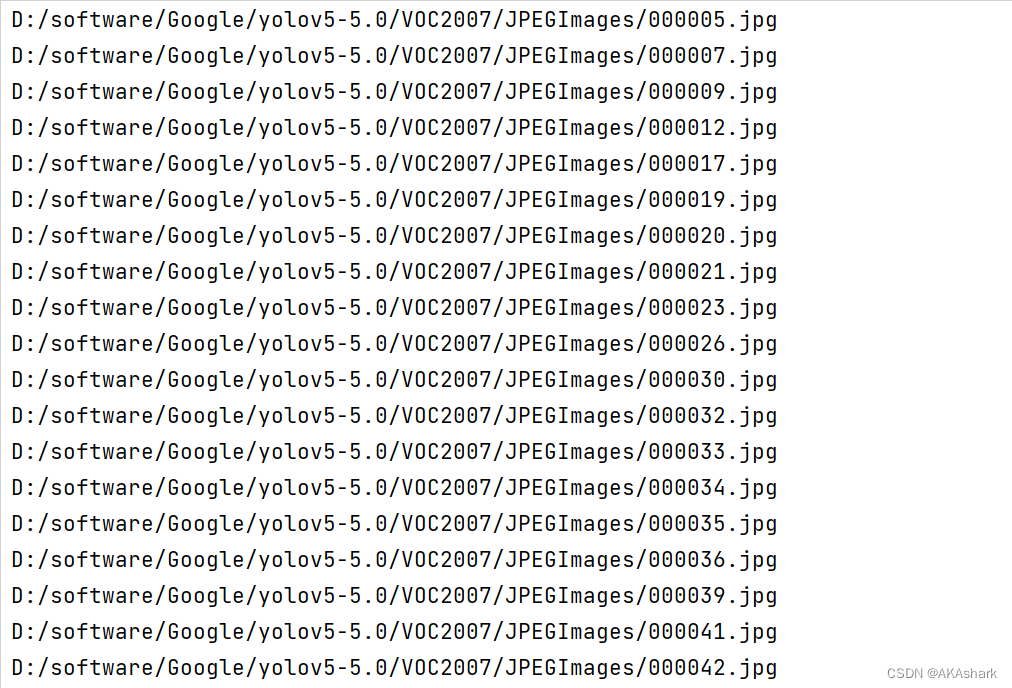
运行之后,会在VOC2007目录下生成labels文件夹和3个新的.txt文件:

其中,新生成的3个的train.txt、val.txt、test.txt,这正是后面训练需要用的文件。每个txt文件里面存放的图片的文件名全路径:
训练前准备
以上操作成功将VOC数据集格式转换成yolo格式后,在正式开始训练之前,还需要修改一些地方。
1、修改voc.yaml文件:yolov5下 train.py 默认使用的是coco.yaml训练的,自己新建一个适用VOC数据集训练的voc.yaml。
首先,修改nc和names的内容,nc:代表自己数据集有多少类,names:代表自己数据集的类的名字;
然后,修改在新建voc.yaml下修改 train 和 val 后面的路径(我这里没用test测试集),改成新生成的 train.txt 和 val.txt 路径地址(注意:不是Main文件夹下的,是上面第3步新生成的!别搞错了!!! 还有一点,下图红色框部分,改路径地址的时候,两个冒号后面跟路径地址之间要有一个空格!)

2、修改yolov5s.yaml文件:修改models目录下的yolov5s.yaml文件内容,就一处,把nc = 80修改为nc = 20即可。这里我用的是yolov5s.yaml。
3、修改datasets.py文件:做完以上步骤,若直接开始训练,会报错:
AssertionError: train: No labels in 2007_train.cache. Can not train without labels
解决方法:
找到utils/dataset.py文件,ctrl+f 搜索框搜索Define label,将下图红色框中内容修改为’JPEGImages’。原本yolov5代码这里是’images’,但VOC是把图片保存在JPEGImages下的,所以需要修改方能正确读取图片。

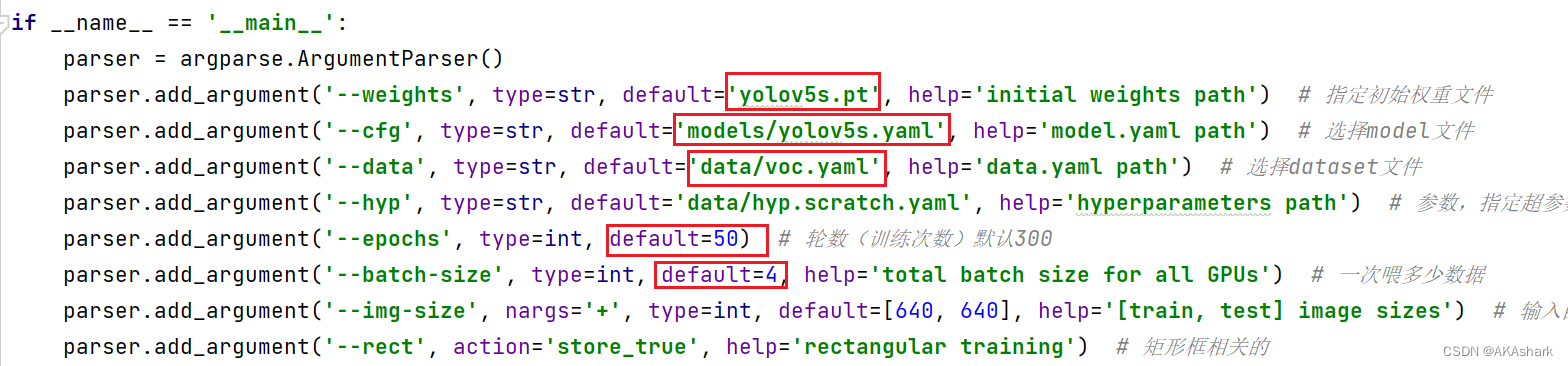
开始训练
对train.py进行修改,选择预训练权重,epochs根据自己情况设置;batch-size需要显存,显存小就设置低点。
参考
2022.5.25之前参考链接:
YOLOv5训练自数据集(VOC格式)
VOC格式数据集转yolo(darknet)格式
YOLOv5训练自己的数据集(超详细完整版)
YOLOv5(ultralytics) 训练自己的数据集,VOC2007为例
2022.5.25之后参考链接
主要是不同的数据格式处理脚本,用得到,本人亲测有效