一、前言
前面两篇文章已经讲解了darknet版本的yolov3和yolov4的训练过程,是时候轮到yolov5了。我个人还是比较喜欢yolov5的,因为它提供了四种不同大小的模型结构供选择,如下图所示:
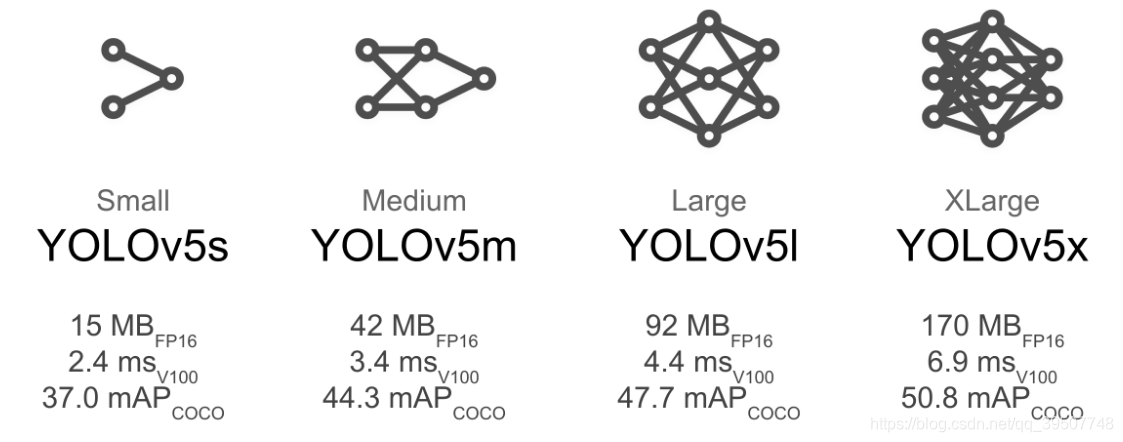
yolov5的训练过程还是比较简单的,而且也方便在windows上进行,毕竟使用的是pytorch框架,下面就来简单说一下如何训练!!!
二、获取并组织数据集
1、如果可以下载好标注好的数据集,那就直接使用即可,注意查看一下数据集的组织格式是否和VOC的格式相同。
2、如果没有现成的数据集,那么可能需要自己去标注,这个以后有机会再细说吧。需要使用一些标注工具,如labelImg,具体使用方法可以参考以下两篇文章!!!
3、数据集的组织格式
根据官方的训练教程,我们需要将数据集变成yolo格式,那么我们就需要借助一个脚本来帮助我们完成转换,不过在此之前,你需要保证你的数据集组织结构是voc的格式。关于voc数据集的组织结构,请移步我的另一篇文章:VOC数据集组织结构详解!!!
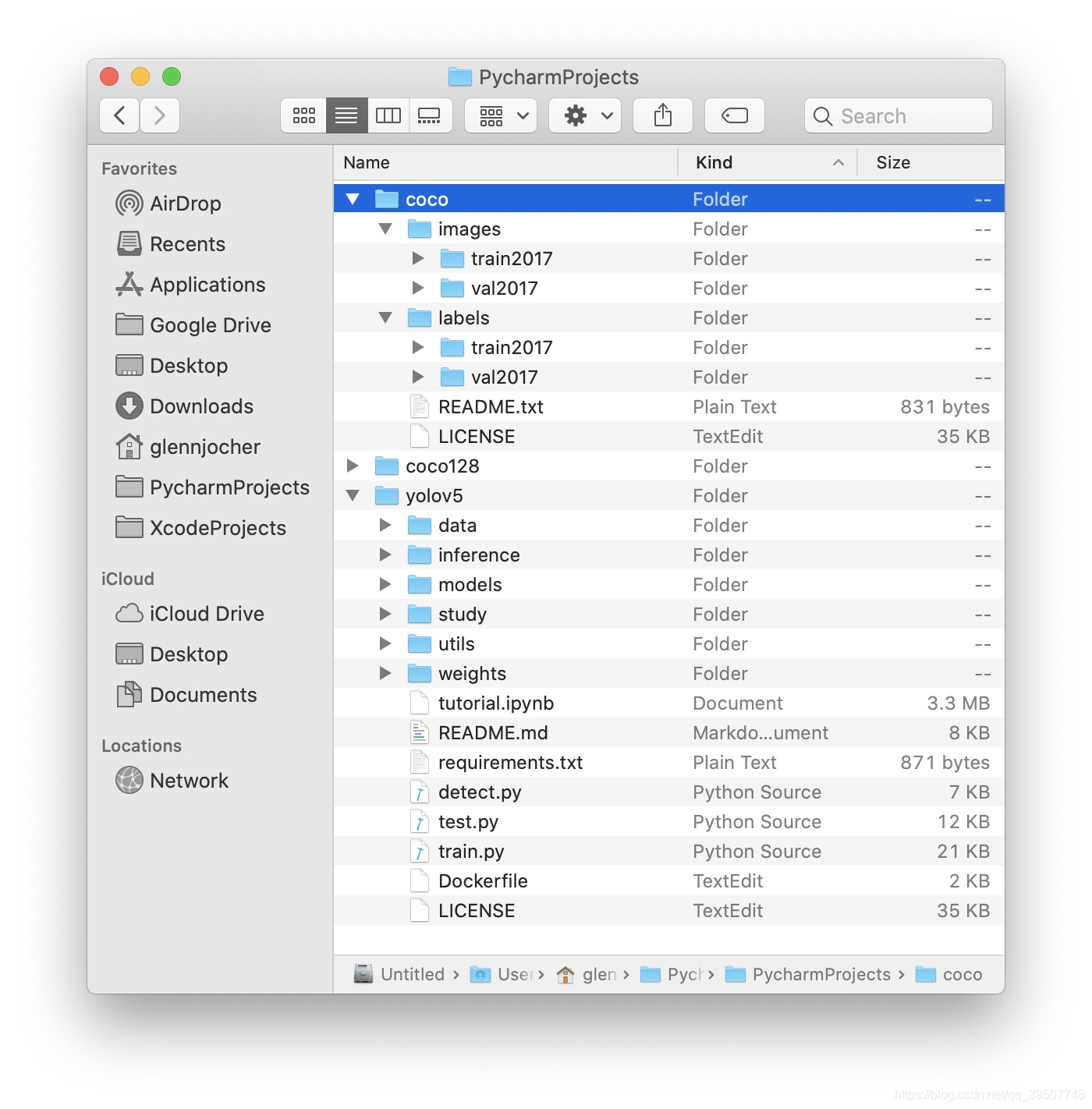
如下图所示,这是官方训练教程中的数据集组织结构,我们最终也需要和这个是一样的,只是结构一样,不一定要名字完全一样。我们只需要保证有images、labels文件夹,以及这两个文件夹下面又有train、val两个子文件夹就可以了。images存放的是图片,labels存放的是yolo格式的标签。
注意: images、labels这两个文件夹下的train/val子文件夹的名字需要保持一致。
4、格式转换
这里,可以移步我的另一篇文章:VOC格式数据集转yolo(darknet)格式。这篇文章中的内容你需要了解,否则下面所说的一些东西你可能看不懂,emmm!!!
我是将训练验证数据集和测试数据集分开转换的,这样也方便分开保存,然后分别放入到指定的文件夹下,具体操作如下:
- 将生成的
2007_train.txt、2007_val.txt合并为2007_train.txt,因为训练验证的图片在一块,不好分开,所以干脆就都作为训练数据,那么我们就需要将这两个文件合并成一个,也就是直接将2007_val.txt的内容复制粘贴到2007_train.txt文件中,然后删掉2007_val.txt文件。 - 然后我们将测试数据集作为验证数据,所以将
2007_test.txt修改为2007_val.txt。最后,2007_train.txt、2007_val.txt文件放入到images同级路径下,这个不是必须的,你只要记住这两个文件的路径,然后在后面设置voc.yaml的时候正确指定即可。 - 通过上述操作,我们得到了
2007_train.txt、2007_val.txt两个文件,但是还需要进行一些修改。因为这两个文件的内容是训练和验证图片的全路径,但是在我们后续组织数据集的时候,图片的路径已经发生了改变,此时图片都在images文件夹下,所以,你需要将这两个文件里面的图片名称前的路径全都换成此时实际所处的路径。这个可以通过批量替换快速完成。 - 将两次转换各生成的一个存放标签的
labels文件夹里内容,分别放到labels/train和labels/val下。 - 将训练数据集和验证数据集两者各自的
JPEGImages文件夹的图片分别移动到images/train和images/val下。
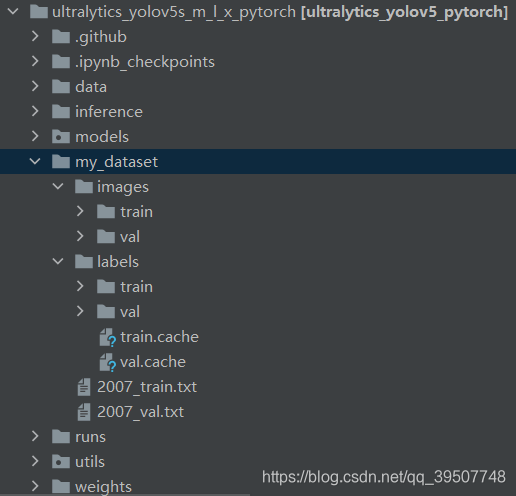
这样,数据集的组织就算完成了。但是,其实你不一定需要按照我上面说的做,因为重点在于你要知道每个文件夹下面存放的啥,然后根据你自己转换之后(即使都使用voc_label.py进行转换,但是可能操作有所不同)所生成的各种文件,最终使得images存放图片,labels存放yolo格式的标签,并且训练验证图片、训练验证标签又分别在train和val子文件夹下即可。
例如,你可以在看懂以下代码后,直接修改voc_label.py中的代码,来更加快速的生成所需的文件。voc_label.py内容如下:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
#转换最初的训练验证数据集的时候,使用以下sets
#转换最初的测试数据集的时候,可以将其改为sets=[('2007', 'test')]
sets=[('2007', 'train'), ('2007', 'val')]
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus",
"car", "cat", "chair", "cow", "diningtable", "dog", "horse",
"motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text),
float(xmlbox.find('xmax').text),
float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'
%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'
%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
三、搭建工程
1、下载源码
https://github.com/ultralytics/yolov5
2、环境配置
pip install -U -r requirements.txt
四、修改相关文件
1、data/voc.yaml 文件
如下所示,我们需要将train、val的值设置为之前说的2007_train.txt、2007_val.txt文件的存放路径。nc和names也需要根据自己的实际情况去修改,分别表示的是类别数目和种类的名字。
# PASCAL VOC dataset http://host.robots.ox.ac.uk/pascal/VOC/
# Train command: python train.py --data voc.yaml
# Default dataset location is next to /yolov5:
# /parent_folder
# /VOC
# /yolov5
# download command/URL (optional)
download: bash data/scripts/get_voc.sh
# train and val data as
# 1) directory: path/images/,
# 2) file: path/images.txt, or
# 3) list: [path1/images/, path2/images/]
train: F:\0-My_projects\My_AI_Prj\0_PyTorch_projects\ultralytics_yolov5s_m_l_x_pytorch
\my_dataset\2007_train.txt # 16551 images
val: F:\0-My_projects\My_AI_Prj\0_PyTorch_projects\ultralytics_yolov5s_m_l_x_pytorch
\my_dataset\2007_val.txt # 4952 images
# number of classes
nc: 20
# class names
names: ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car',
'cat', 'chair', 'cow', 'diningtable', 'dog','horse', 'motorbike',
'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor']
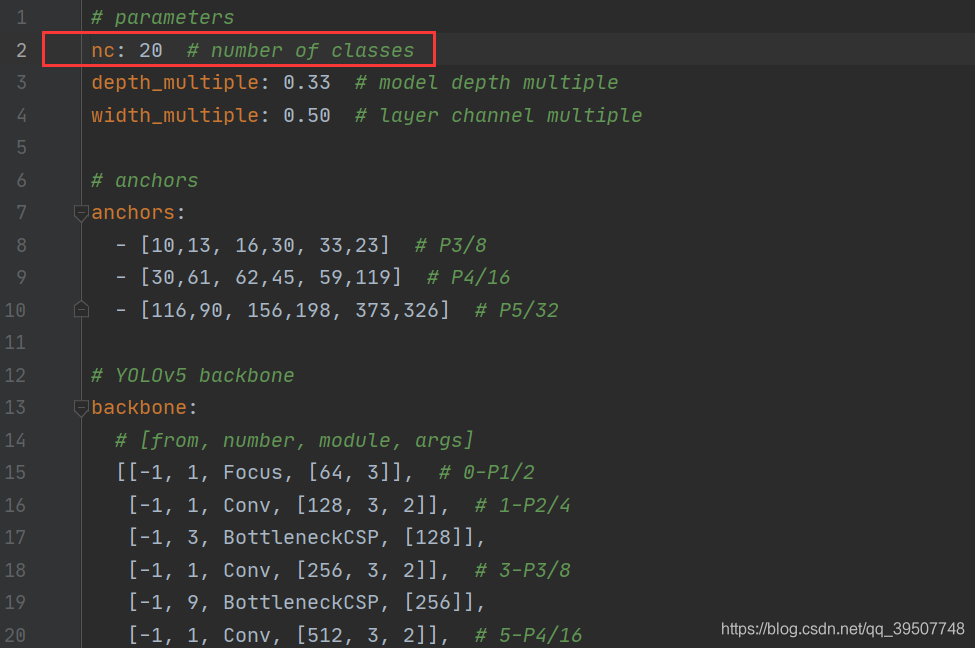
2、models/yolov5s.yaml 文件
这里我是准备训练yolov5s,如果你想要训练其他三个模型,选择对应的配置文件即可。我们一般只需要修改第一行的nc为自己的数据集的种类数即可。
3、训练参数
为了方便,我们可以直接在train.py文件中进行参数修改,然后直接运行train.py即可,如下所示:
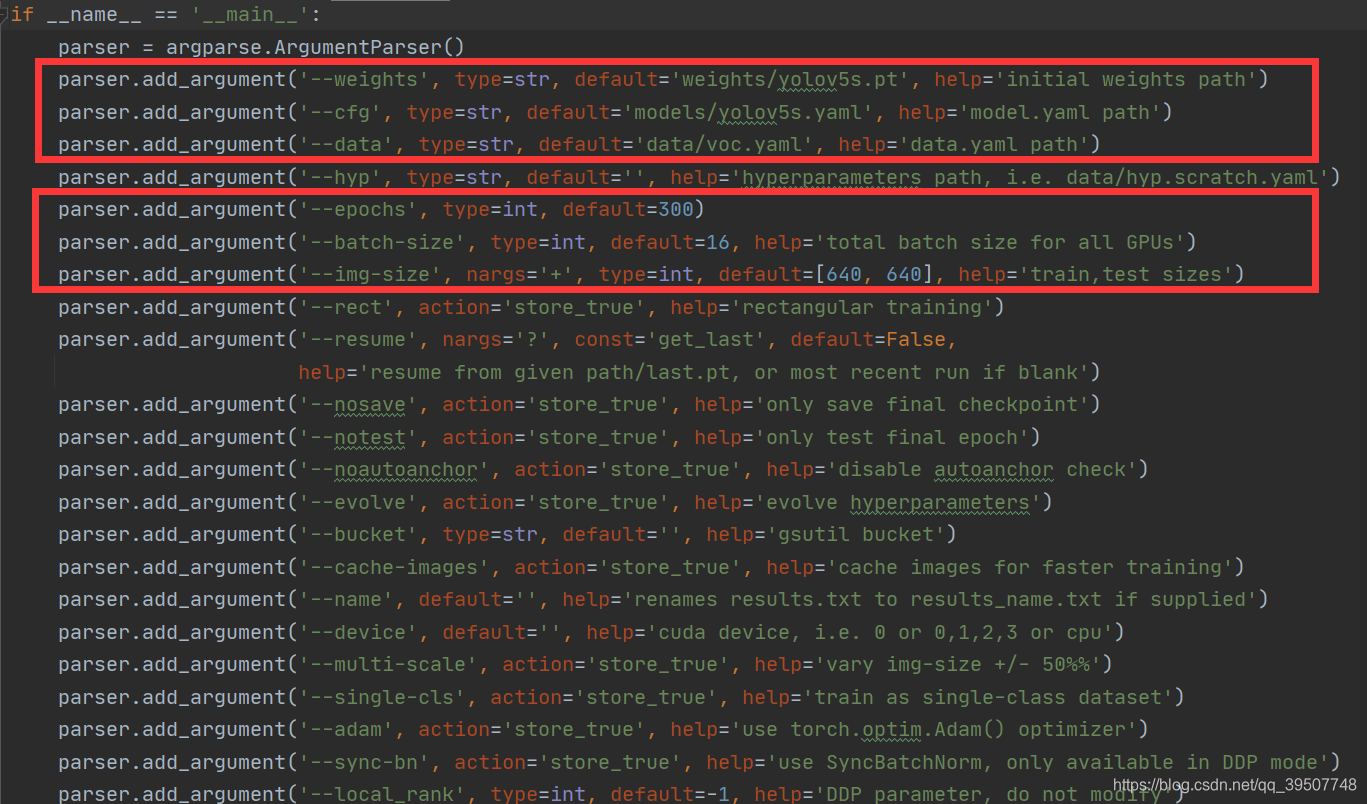
需要注意的是:如果你指定的weights的路径,也即第一个参数,如果不存在,那么它会自己去下载。如果下载失败,那么你可以自己去下载初始权重文件,然后放到这个路径下即可。
五、开始训练
直接运行train.py文件即可。