全部笔记的汇总贴:《百面机器学习》-读书笔记汇总
对于这一部分不太熟悉的,可以看看这篇文章里的视频学习一下:白板推导系列笔记(九)-概率图模型
对于一个实际问题,我们希望能够挖掘隐含在数据中的知识。概率图模型构建了这样一幅图,用观测结点表示观测到的数据,用隐含结点表示潜在的知识,用边来描述知识与数据的相互关系,最后基于这样的关系图获得一个概率分布,非常“优雅”地解决了问题。
概率图中的节点分为隐含节点和观测节点,边分为有向边和无向边。从概率论的角度,节点对应于随机变量,边对应于随机变量的依赖或相关关系,其中有向边表示单向的依赖,无向边表示相互依赖关系。
概率图模型分为贝叶斯网络(Bayesian Network)和马尔可夫网络(Markov Network)两大类。贝叶斯网络可以用一个有向图结构表示,马尔可夫网络可以表示成一个无向图的网络结构。更详细地说,概率图模型包括了朴素贝叶斯模型、最大熵模型、隐马尔可夫模型、条件随机场、主题模型等,在机器学习的诸多场景中都有着广泛的应用。
一、概率图模型的联合概率分布
概率图模型最为“精彩”的部分就是能够用简洁清晰的图示形式表达概率生成的关系。而通过概率图还原其概率分布不仅是概率图模型最重要的功能,也是掌握概率图模型最重要的标准。
- ★☆☆☆☆ 能否写出图中贝叶斯网络的联合概率分布?
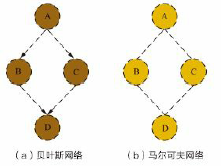
由图可见,在给定A的条件下B和C是条件独立的,基于条件概率的定义可得 P ( C ∣ A , B ) = P ( B , C ∣ A ) P ( B ∣ A ) = P ( B ∣ A ) P ( C ∣ A ) P ( B ∣ A ) = P ( C ∣ A ) P(C|A,B)=\frac{P(B,C|A)}{P(B|A)}=\frac{P(B|A)P(C|A)}{P(B|A)}=P(C|A) P(C∣A,B)=P(B∣A)P(B,C∣A)=P(B∣A)P(B∣A)P(C∣A)=P(C∣A)
同理,在给定B和C的条件下A和D是条件独立的,可得 P ( D ∣ A , B , C ) = P ( A , D ∣ B , C ) P ( A ∣ B , C ) = P ( A ∣ B , C ) P ( D ∣ B , C ) P ( A ∣ B , C ) = P ( D ∣ B , C ) P(D|A,B,C)=\frac{P(A,D|B,C)}{P(A|B,C)}=\frac{P(A|B,C)P(D|B,C)}{P(A|B,C)}=P(D|B,C) P(D∣A,B,C)=P(A∣B,C)P(A,D∣B,C)=P(A∣B,C)P(A∣B,C)P(D∣B,C)=P(D∣B,C)
所以,联合概率 P ( A , B , C , D ) = P ( A ) P ( B ∣ A ) P ( C ∣ A , B ) P ( D ∣ A , B , C ) = P ( A ) P ( B ∣ A ) P ( C ∣ A ) P ( D ∣ B , C ) P(A,B,C,D)=P(A)P(B|A)P(C|A,B)P(D|A,B,C)\\=P(A)P(B|A)P(C|A)P(D|B,C) P(A,B,C,D)=P(A)P(B∣A)P(C∣A,B)P(D∣A,B,C)=P(A)P(B∣A)P(C∣A)P(D∣B,C)
- ★☆☆☆☆ 能否写出上图中马尔可夫网络的联合概率分布?
在马尔可夫网络中,联合概率分布的定义为 P ( x ) = 1 Z ∏ Q ∈ C ψ Q ( x Q ) P(x)=\frac1Z\prod_{Q\in C}\psi_Q(x_Q) P(x)=Z1Q∈C∏ψQ(xQ)其中 C C C为图中最大团所构成的集合, Z = ∑ x ∏ Q ∈ C ψ Q ( x Q ) Z=\sum_x\prod_{Q\in C}\psi_Q(x_Q) Z=∑x∏Q∈CψQ(xQ)为归一化因子,用来保证 P ( x ) P(x) P(x)是被正确定义的概率, ψ Q \psi_Q ψQ是与团 Q Q Q对应的势函数。势函数是非负的,并且应该在概率较大的变量上取得较大的值,例如指数函数 ψ Q ( x Q ) = e − H Q ( x Q ) \psi_Q(x_Q)=e^{-H_Q(x_Q)} ψQ(xQ)=e−HQ(xQ)其中 H Q ( x Q ) = ∑ u , v ∈ Q , u ≠ v α u , v x u x v + ∑ v ∈ Q β v x v H_Q(x_Q)=\sum_{u,v\in Q,u\neq v}\alpha_{u,v}x_ux_v+\sum_{v\in Q}\beta_vx_v HQ(xQ)=u,v∈Q,u=v∑αu,vxuxv+v∈Q∑βvxv对于图中所有节点 x = x 1 , x 2 , . . . , x n x={x_1,x_2,...,x_n} x=x1,x2,...,xn所构成的一个子集,如果在这个子集中,任意两点之间都存在边相连,则这个子集中的所有节点构成了一个团。如果在这个子集中加入任意其他节点,都不能构成一个团,则称这样的子集构成了一个最大团。
在图中所示的网络结构中,可以看到 ( A , B ) 、 ( A , C ) 、 ( B , D ) 、 ( C , D ) (A,B)、(A,C)、(B,D)、(C,D) (A,B)、(A,C)、(B,D)、(C,D)均构成团,同时也是最大团。因此联合概率分布可以表示为 P ( A , B , C , D ) = 1 Z ψ 1 ( A , B ) ψ 2 ( A , C ) ψ 3 ( B , D ) ψ 4 ( C , D ) P(A,B,C,D)=\frac1Z\psi_1(A,B)\psi_2(A,C)\psi_3(B,D)\psi_4(C,D) P(A,B,C,D)=Z1ψ1(A,B)ψ2(A,C)ψ3(B,D)ψ4(C,D)如果采用上面定义的指数函数作为势函数,则有 H ( A , B , C , D ) = α 1 A B + α 2 A C + α 3 B D + α 4 C D + β 1 A + β 2 B + β 3 C + β 4 D H(A,B,C,D)=\alpha_1AB+\alpha_2AC+\alpha_3BD+\alpha_4CD+\beta_1A+\beta_2B+\beta_3C+\beta_4D H(A,B,C,D)=α1AB+α2AC+α3BD+α4CD+β1A+β2B+β3C+β4D于是, P ( A , B , C , D ) = 1 Z e − H ( A , B , C , D ) P(A,B,C,D)=\frac1Ze^{-H(A,B,C,D)} P(A,B,C,D)=Z1e−H(A,B,C,D)
二、概率图表示
- ★★☆☆☆ 解释朴素贝叶斯模型的原理,并给出概率图模型表示。
朴素贝叶斯模型通过预测指定样本属于特定类别的概率 P ( y i ∣ x ) P(y_i|x) P(yi∣x)来预测该样本的所属类别,即 y = max y i P ( y i ∣ x ) y=\max_{y_i}P(y_i|x) y=yimaxP(yi∣x)其中 P ( y i ∣ x ) P(y_i|x) P(yi∣x)可以写成 P ( y i ∣ x ) = P ( x ∣ y i ) P ( y i ) P ( x ) P(y_i|x)=\frac{P(x|y_i)P(y_i)}{P(x)} P(yi∣x)=P(x)P(x∣yi)P(yi)
其中 x = ( x 1 , x 2 , . . . , x n ) x=(x_1,x_2,...,x_n) x=(x1,x2,...,xn)为样本对应的特征向量, P ( x ) P(x) P(x)为样本的先验概率。对于特定的样本 x x x和任意类别 y i y_i yi, P ( x ) P(x) P(x)的取值均相同,并不会影响 P ( y i ∣ x ) P(y_i|x) P(yi∣x)取值的相对大小,因此在计算中可以被忽略。假设特征 x 1 , x 2 , . . . , x n x_1,x_2,...,x_n x1,x2,...,xn相互独立,可以得到: P ( y i ∣ x ) ∝ P ( x ∣ y i ) P ( y i ) = P ( x 1 ∣ y i ) P ( x 2 ∣ y i ) ⋯ P ( x n ∣ y i ) P ( y i ) P(y_i|x)\propto P(x|y_i)P(y_i)=P(x_1|y_i)P(x_2|y_i)\cdots P(x_n|y_i)P(y_i) P(yi∣x)∝P(x∣yi)P(yi)=P(x1∣yi)P(x2∣yi)⋯P(xn∣yi)P(yi)
其中 P ( x 1 ∣ y i ) , P ( x 2 ∣ y i ) , . . . , P ( x n ∣ y i ) P(x_1|y_i),P(x_2|y_i),...,P(x_n|y_i) P(x1∣yi),P(x2∣yi),...,P(xn∣yi),以及 P ( y i ) P(y_i) P(yi)可以通过训练样本统计得到。可以看到后验概率 P ( x j ∣ y i ) P(x_j|y_i) P(xj∣yi)的取值决定了分类的结果,并且任意特征 x j x_j xj都由 y i y_i yi的取值所影响。
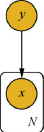
- ★★☆☆☆ 解释最大熵模型的原理,并给出概率图模型表示。
信息是指人们对事物理解的不确定性的降低或消除,而熵就是不确定性的度量,熵越大,不确定性也就越大。最大熵原理是概率模型学习的一个准则,指导思想是在满足约束条件的模型集合中选取熵最大的模型,即不确定性最大的模型。在平时生活中,我们也会有意无意地使用最大熵的准则,例如人们常说的鸡蛋不能放在一个篮子里,就是指在事情具有不确定性的时候,我们倾向于尝试它的多种可能性,从而降低结果的风险。同时,在摸清了事情背后的某种规律之后,可以加入一个约束,将不符合规律约束的情况排除,在剩下的可能性中去寻找使得熵最大的决策。
最大熵模型就是要学习到合适的分布P(y|x),使得条件熵H§的取值最大。在对训练数据集一无所知的情况下,最大熵模型认为P(y|x)是符合均匀分布的。那么当我们有了训练数据集之后呢?我们希望从中找到一些规律,从而消除一些不确定性。
三、生成式模型与判别式模型
- ★★★☆☆ 常见的概率图模型中,哪些是生成式模型,哪些是判别式模型?
常见的概率图模型有朴素贝叶斯、最大熵模型、贝叶斯网络、隐马尔可夫模型、条件随机场、pLSA、LDA等。
朴素贝叶斯、贝叶斯网络、pLSA、LDA等模型都是先对联合概率分布进行建模,然后再通过计算边缘分布得到对变量的预测,所以它们都属于生成式模型;
而最大熵模型是直接对条件概率分布进行建模,因此属于判别式模型。
隐马尔可夫模型和条件随机场模型是对序列数据进行建模的方法,其中隐马尔可夫模型属于生成式模型,条件随机场属于判别式模型。
四、马尔可夫模型
- ★★★☆☆ 如何对中文分词问题用隐马尔可夫模型进行建模和训练?
隐马尔可夫模型包括概率计算问题、预测问题、学习问题三个基本问题。
- 概率计算问题:已知模型的所有参数,计算观测序列Y出现的概率,可使用前向和后向算法求解。
- 预测问题:已知模型所有参数和观测序列 Y Y Y,计算最可能的隐状态序列 X X X,可使用经典的动态规划算法——维特比算法来求解最可能的状态序列。
- 学习问题:已知观测序列 Y Y Y,求解使得该观测序列概率最大的模型参数,包括隐状态序列、隐状态之间的转移概率分布以及从隐状态到观测状态的概率分布,可使用Baum-Welch算法进行参数的学习,Baum-Welch算法是最大期望算法的一个特例。
- ★★★★☆ 最大熵马尔可夫模型为什么会产生标注偏置问题?如何解决?
隐马尔可夫模型等用于解决序列标注问题的模型中,常常对标注进行了独立性假设。以隐马尔可夫模型为例介绍标注偏置问题(Label Bias Problem)。
实际上,在序列标注问题中,隐状态(标注)不仅和单个观测状态相关,还和观察序列的长度、上下文等信息相关。例如词性标注问题中,一个词被标注为动词还是名词,不仅与它本身以及它前一个词的标注有关,还依赖于上下文中的其他词,于是引出了最大熵马尔可夫模型(Maximum Entropy Markov Model, MEMM)。
最大熵马尔可夫模型在建模时,去除了隐马尔可夫模型中观测状态相互独立的假设,考虑了整个观测序列,因此获得了更强的表达能力。同时,隐马尔可夫模型是一种对隐状态序列和观测状态序列的联合概率 P ( x , y ) P(x,y) P(x,y)进行建模的生成式模型,而最大熵马尔可夫模型是直接对标注的后验概率 P ( y ∣ x ) P(y|x) P(y∣x)进行建模的判别式模型。
条件随机场(Conditional Random Field,CRF)在最大熵马尔可夫模型的基础上,进行了全局归一化,从而解决了局部归一化带来的标注偏置问题。
五、主题模型
基于词袋模型或N-gram模型的文本表示模型有一个明显的缺陷,就是无法识别出两个不同的词或词组具有相同的主题。因此,需要一种技术能够将具有相同主题的词或词组映射到同一维度上去,于是产生了主题模型。主题模型是一种特殊的概率图模型。
- ★★☆☆☆ 常见的主题模型有哪些?试介绍其原理。
- pLSA
pLSA是用一个生成模型来建模文章的生成过程。假设有 K K K个主题, M M M篇文章;对语料库中的任意文章 d d d,假设该文章有 N N N个词,则对于其中的每一个词,我们首先选择一个主题 z z z,然后在当前主题的基础上生成一个词 w w w。- LDA
LDA可以看作是pLSA的贝叶斯版本,其文本生成过程与pLSA基本相同,不同的是为主题分布和词分布分别加了两个狄利克雷(Dirichlet)先验。LDA采用的是贝叶斯学派的思想,认为待估计的参数(主题分布和词分布)不再是一个固定的常数,而是服从一定分布的随机变量。这个分布符合一定的先验概率分布(即狄利克雷分布),并且在观察到样本信息之后,可以对先验分布进行修正,从而得到后验分布。LDA之所以选择狄利克雷分布作为先验分布,是因为它为多项式分布的共轭先验概率分布,后验概率依然服从狄利克雷分布,这样做可以为计算带来便利。
- ★★☆☆☆ 如何确定LDA模型中的主题个数?
在LDA中,主题的个数K是一个预先指定的超参数。对于模型超参数的选择,实践中的做法一般是将全部数据集分成训练集、验证集、和测试集3部分,然后利用验证集对超参数进行选择。
另外一种方法是在LDA基础之上融入分层狄利克雷过程(Hierarchical Dirichlet Process,HDP),构成一种非参数主题模型HDP-LDA。非参数主题模型的好处是不需要预先指定主题的个数,模型可以随着文档数目的变化而自动对主题个数进行调整;它的缺点是在LDA基础上融入HDP之后使得整个概率图模型更加复杂,训练速度也更加缓慢,因此在实际应用中还是经常采用第一种方法确定合适的主题数目。
- ★★★☆☆ 如何用主题模型解决推荐系统中的冷启动问题?
推荐系统中的冷启动问题是指在没有大量用户数据的情况下如何给用户进行个性化推荐,目的是最优化点击率、转化率或用户体验(用户停留时间、留存率等)。冷启动问题一般分为用户冷启动、物品冷启动和系统冷启动三大类。用户冷启动是指对一个之前没有行为或行为极少的新用户进行推荐;物品冷启动是指为一个新上市的商品或电影(这时没有与之相关的评分或用户行为数据)寻找到具有潜在兴趣的用户;系统冷启动是指如何为一个新开发的网站设计个性化推荐系统。
解决冷启动问题的方法一般是基于内容的推荐。那么如何解决系统冷启动问题呢?首先可以得到每个用户和电影对应的主题向量,除此之外,还需要知道用户主题和电影主题之间的偏好程度,也就是哪些主题的用户可能喜欢哪些主题的电影。当系统中没有任何数据时,我们需要一些先验知识来指定,并且由于主题的数目通常比较小,随着系统的上线,收集到少量的数据之后我们就可以对主题之间的偏好程度得到一个比较准确的估计。
下一章传送门:《百面机器学习》读书笔记(七)-优化算法