全部笔记的汇总贴:《百面机器学习》-读书笔记汇总
深度前馈网络(Deep Feedforward Networks)是一种典型的深度学习模型。其目标为拟合某个函数 f f f,即定义映射 y = f ( x ; θ ) y=f (x;θ) y=f(x;θ)将输入 x x x转化为某种预测的输出 y y y,并同时学习网络参数 θ θ θ的值,使模型得到最优的函数近似。由于从输入到输出的过程中不存在与模型自身的反馈连接,此类模型被称为“前馈”。
一、多层感知机与布尔函数
- ★★☆☆☆ 多层感知机表示异或逻辑时最少需要几个隐含层(仅考虑二元输入)?
事实上,通用近似定理告诉我们,一个前馈神经网络如果具有线性输出层和至少一层具有任何一种“挤压”性质的激活函数的隐藏层,当给予网络足够数量的隐藏单元时,可以以任意精度近似任何从一个有限维空间到另一个有限维空间的波莱尔可测函数。对通用近似定理的证明并不在面试的要求范围,不过可以简单认为我们常用的激活函数和目标函数是通用近似定理适用的一个子集,因此多层感知机的表达能力是非常强的,关键在于我们是否能够学习到对应此表达的模型参数。
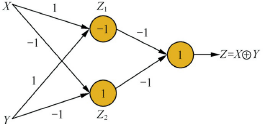
- ★★★☆☆ 如果只使用一个隐层,需要多少隐节点能够实现包含n元输入的任意布尔函数?
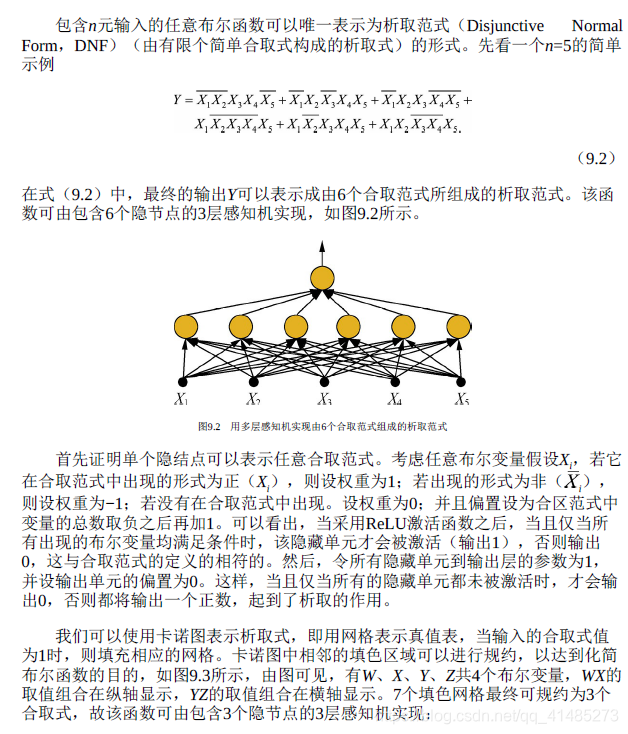
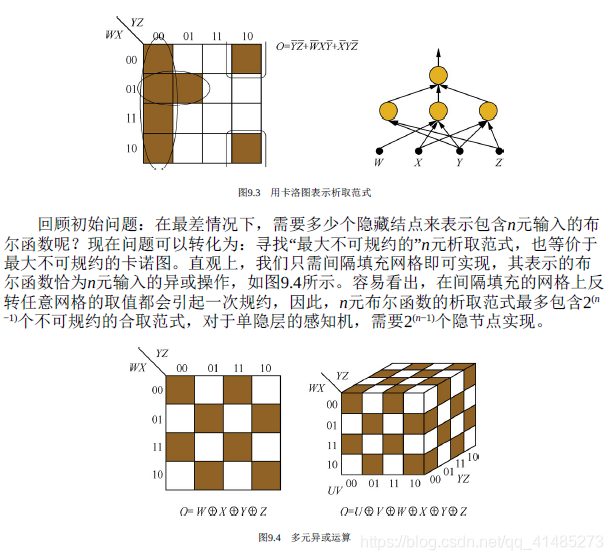
- ★★★☆☆ 考虑多隐层的情况,实现包含n元输入的任意布尔函数最少需要多少个网络节点和网络层?

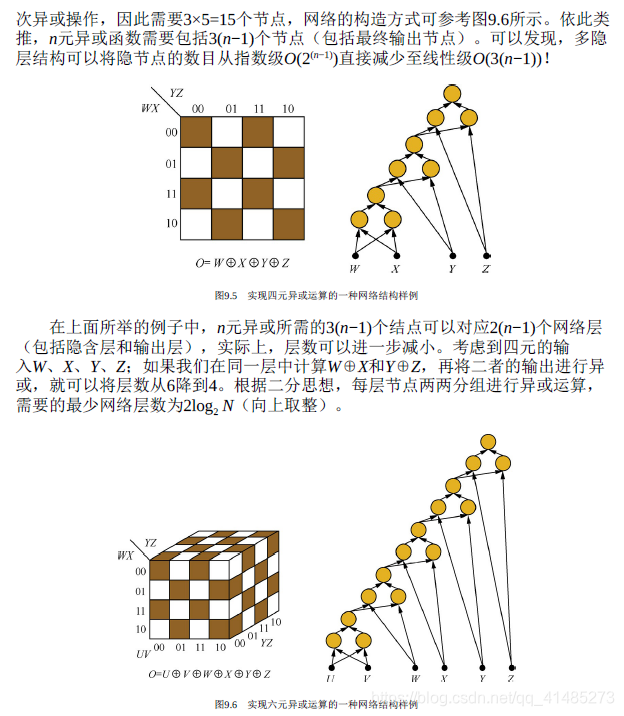
二、深度神经网络中的激活函数
线性模型是机器学习领域中最基本也是最重要的工具,以逻辑回归和线性回归为例,无论通过闭解形式还是使用凸优化,它们都能高效且可靠地拟合数据。然而真实情况中,我们往往会遇到线性不可分问题(如XOR异或函数),需要非线性变换对数据的分布进行重新映射。对于深度神经网络,我们在每一层线性变换后叠加一个非线性激活函数,以避免多层网络等效于单层线性函数,从而获得更强大的学习与拟合能力。
- ★☆☆☆☆ 写出常用激活函数及其导数。
- Sigmoid激活函数的形式及其对应的导函数为 f ( z ) = 1 1 + exp ( − z ) f ′ ( z ) = f ( z ) ( 1 − f ( z ) ) f(z)=\frac1{1+\exp(-z)}\;\;\;\;\;\;f'(z)=f(z)(1-f(z)) f(z)=1+exp(−z)1f′(z)=f(z)(1−f(z))
- Tanh激活函数的形式及其对应的导函数为 f ( z ) = t a n h ( z ) = e z − e − z e z + e − z f ′ ( z ) = 1 − ( f ( z ) ) 2 f(z)=tanh(z)=\frac{e^z-e^{-z}}{e^z+e^{-z}}\;\;\;\;\;\;\;\;f'(z)=1-(f(z))^2 f(z)=tanh(z)=ez+e−zez−e−zf′(z)=1−(f(z))2
- ReLU激活函数的形式及其对应的导函数为 f ( z ) = max { 0 , z } f ′ ( z ) = { 1 , z > 0 0 , z ≤ 0 f(z)=\max\{0,z\}\;\;\;\;\;\;\;f'(z)=\left\{ \begin{array}{l} 1,\;\;\;z>0\\ \\0,\;\;\;z\le0 \end{array} \right. f(z)=max{ 0,z}f′(z)=⎩⎨⎧1,z>00,z≤0
- ★★☆☆☆ 为什么Sigmoid和Tanh激活函数会导致梯度消失的现象?

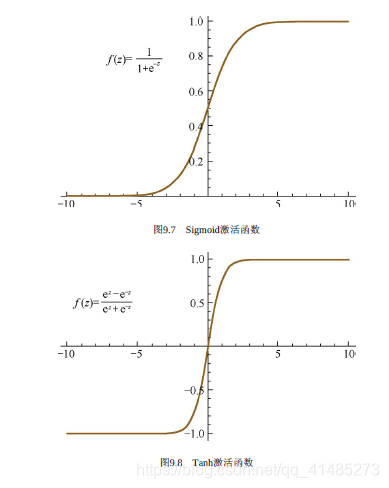
- ★★★☆☆ ReLU系列的激活函数相对于Sigmoid和Tanh激活函数的优点是什么?它们有什么局限性以及如何改进?
优点:
- 从计算的角度上,Sigmoid和Tanh激活函数均需要计算指数,复杂度高,而ReLU只需要一个阈值即可得到激活值。
- ReLU的非饱和性可以有效地解决梯度消失的问题,提供相对宽的激活边界。
- ReLU的单侧抑制提供了网络的稀疏表达能力。
局限性:

三、多层感知机的反向传播算法
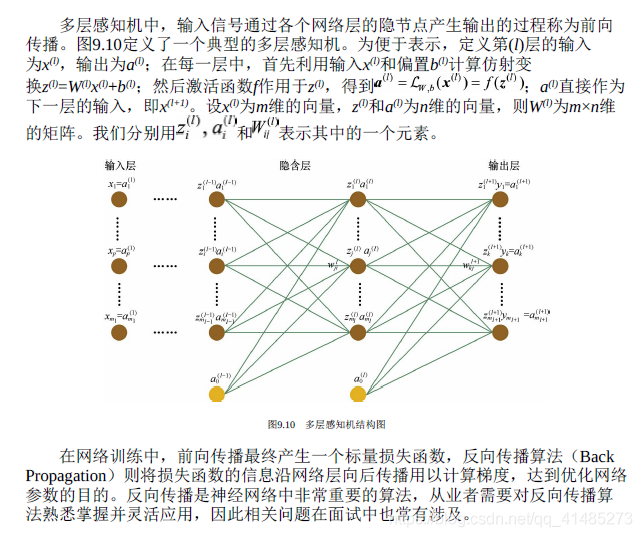
- ★★☆☆☆ 写出多层感知机的平方误差和交叉熵损失函数。

- ★★★★☆ 根据问题1中定义的损失函数,推导各层参数更新的梯度计算公式。


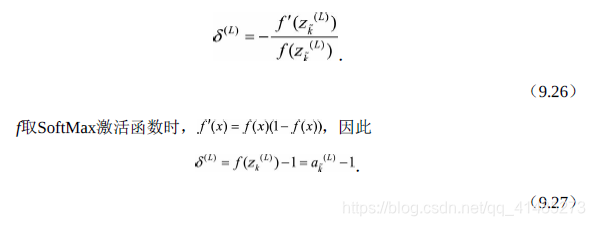
- ★★★☆☆ 平方误差损失函数和交叉熵损失函数分别适合什么场景?

四、神经网络训练技巧
在大规模神经网络的训练过程中,我们常常会面临“过拟合”的问题,即当参数数目过于庞大而相应的训练数据短缺时,模型在训练集上损失值很小,但在测试集上损失较大,泛化能力很差。解决“过拟合”的方法有很多,包括数据集增强(Data Augmentation)、参数范数惩罚/正则化(Regularization)、模型集成(Model Ensemble)等;其中Dropout是模型集成方法中最高效与常用的技巧。同时,深度神经网络的训练中涉及诸多手调参数,如学习率、权重衰减系数、Dropout比例等,这些参数的选择会显著影响模型最终的训练效果。批量归一化(Batch Normalization,BN)方法有效规避了这些复杂参数对网络训练产生的影响,在加速训练收敛的同时也提升了网络的泛化能力。
- ★☆☆☆☆ 神经网络训练时是否可以将全部参数初始化为0?
考虑全连接的深度神经网络,同一层中的任意神经元都是同构的,它们拥有相同的输入和输出,如果再将参数全部初始化为同样的值,那么无论前向传播还是反向传播的取值都是完全相同的。学习过程将永远无法打破这种对称性,最终同一网络层中的各个参数仍然是相同的。
因此,我们需要随机地初始化神经网络参数的值,以打破这种对称性。简单来说,我们可以初始化参数为取值范围 ( − 1 d , 1 d ) (-\frac1{\sqrt{d}},\frac1{\sqrt{d}}) (−d1,d1)的均匀分布,其中 d d d是一个神经元接受的输入维度。偏置可以被简单地设为0,并不会导致参数对称的问题。
- ★★★☆☆ 为什么Dropout可以抑制过拟合?它的工作原理和实现?


- ★★★☆☆ 批量归一化的基本动机与原理是什么?在卷积神经网络中如何使用?


五、深度卷积神经网络
卷积神经网络(Convolutional Neural Networks,CNN)也是一种前馈神经网络,其特点是每层的神经元节点只响应前一层局部区域范围内的神经元(全连接网络中每个神经元节点响应前一层的全部节点)。一个深度卷积神经网络模型通常由若干卷积层叠加若干全连接层组成,中间也包含各种非线性操作以及池化操作。卷积神经网络同样可以使用反向传播算法进行训练,相较于其他网络模型,卷积操作的参数共享特性使得需要优化的参数数目大大缩减,提高了模型的训练效率以及可扩展性。由于卷积运算主要用于处理类网格结构的数据,因此对于时间序列以及图像数据的分析与识别具有显著优势。
- ★★☆☆☆ 卷积操作的本质特性包括稀疏交互和参数共享,具体解释这两种特性及其作用。
- 稀疏交互(Sparse Interaction)
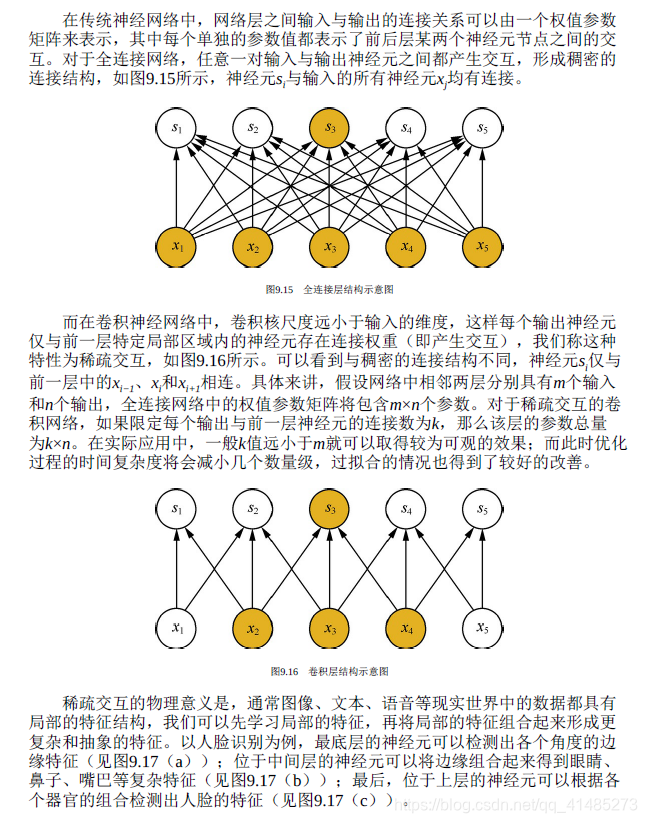

- 参数共享(Parameter Sharing)

- ★★★☆☆ 常用的池化操作有哪些?池化的作用是什么?
常用的池化操作主要针对非重叠区域,包括均值池化(mean pooling)、最大池化(max pooling)等。其中均值池化通过对邻域内特征数值求平均来实现,能够抑制由于邻域大小受限造成估计值方差增大的现象,特点是对背景的保留效果更好。最大池化则通过取邻域内特征的最大值来实现,能够抑制网络参数误差造成估计均值偏移的现象,特点是更好地提取纹理信息。池化操作的本质是降采样。例如,我们可以利用最大池化将4×4的矩阵降采样为2×2的矩阵,如图9.18所示。图中的池化操作窗口大小为2×2,步长为2。每次在2×2大小的窗口上进行计算,均值池化是求窗口中元素的均值,最大池化则求窗口中元素的最大值;然后将窗口向右或向下平移两格,继续操作。

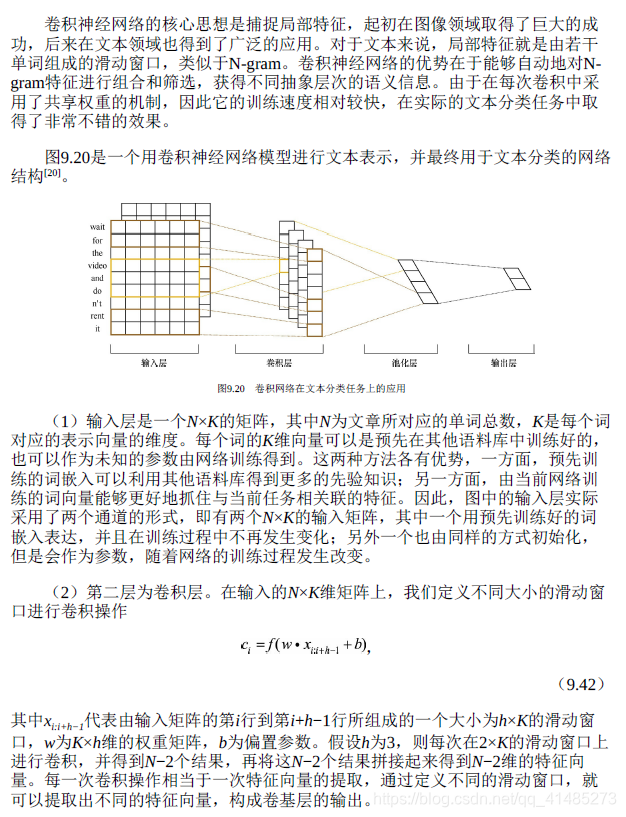
- ★★★☆☆ 卷积神经网络如何用于文本分类任务?

六、深度残差网络
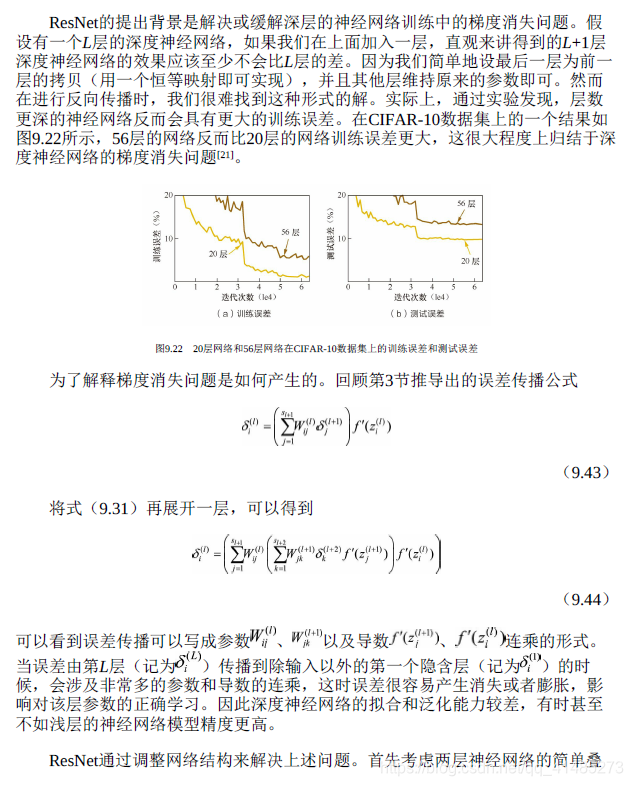
随着大数据时代的到来,数据规模日益增加,这使得我们有可能训练更大容量的模型,不断地提升模型的表示能力和精度。深度神经网络的层数决定了模型的容量,然而随着神经网络层数的加深,优化函数越来越陷入局部最优解。同时,随着网络层数的增加,梯度消失的问题更加严重,这是因为梯度在反向传播时会逐渐衰减。特别是利用Sigmoid激活函数时,使得远离输出层(即接近输入层)的网络层不能够得到有效的学习,影响了模型泛化的效果。为了改善这一问题,深度学习领域的研究员们在过去十几年间尝试了许多方法,包括改进训练算法、利用正则化、设计特殊的网络结构等。其中,深度残差网络(Deep Residual Network,ResNet)是一种非常有效的网络结构改进,极大地提高了可以有效训练的深度神经网络层数。
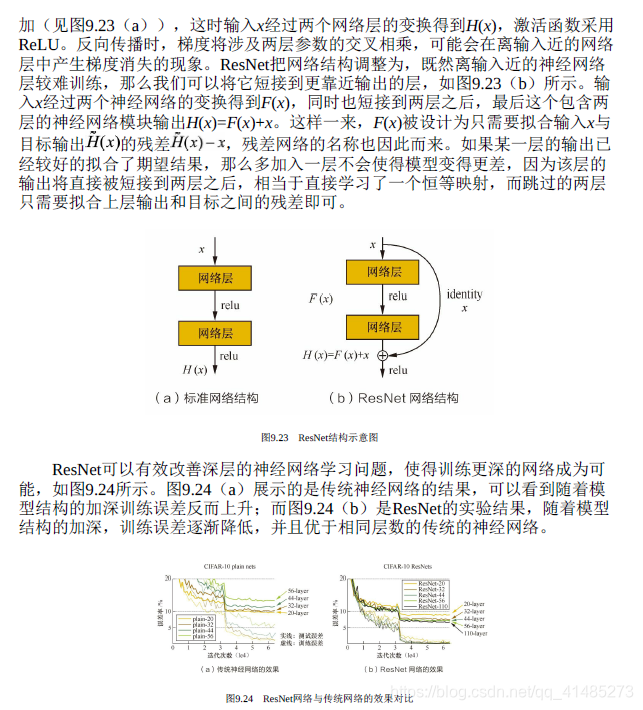
- ★★★☆☆ ResNet的提出背景和核心理论是什么?
下一章传送门:《百面机器学习》读书笔记(十)-循环神经网络