一、 实验目的
设计、编制、调试一个词法分析程序,对单词进行识别和编码,加深对词法分析原理的理解。
二、实验内容
1.选定语言,编辑任意的源程序保存在文件中;
2.对文件中的代码预处理,删除制表符、回车符、换行符、注释、多余的空格并将预处理后的代码保存在文件中;
3.扫描处理后的源程序,分离各个单词符号,显示分离的单词类型。
三、实验思路
对于实验内容1,选择编写c语言的源程序存放在code.txt中,设计一个c语言的词法分析器,主要包含三部分,一部分是预处理函数,第二部分是扫描判断单词类型的函数,第三部分是主函数,调用其它函数;
对于实验内容2,主要实现在预处理函数processor()中,使用文档操作函数打开源程序文件(code.txt),去除两种类型(“//”,“/*…*/”)的注释、多余的空格合并为一个、换行符、回车符等,然后将处理后的保存在另一个新的文件(afterdel.txt)中,最后关闭文档。
对于实验内容3,打开处理后的文件,然后调用扫描函数,从文件里读取一个单词调用判断单词类型的函数与之前建立的符号表进行对比判断,最后格式化输出。
四、编码设计
代码参考了两篇博主的,做了部分改动,添加了预处理函数等
1 #include<iostream> 2 #include<fstream> 3 #include<cstdio> 4 #include<cstring> 5 #include<string> 6 #include<cstdlib> 7 8 using namespace std; 9 10 int aa;// fseek的时候用来接着的 11 string word=""; 12 string reserved_word[20];//保留 13 char buffer;//每次读进来的一个字符 14 int num=0;//每个单词中当前字符的位置 15 int line=1; //行数 16 int row=1; //列数,就是每行的第几个 17 bool flag; //文件是否结束了 18 int flag2;//单词的类型 19 20 21 //预处理函数 22 int processor(){//预处理函数 23 FILE *p; 24 int falg = 0,len,i=0,j=0; 25 char str[1000],str1[1000],c; 26 if((p=fopen("code.txt","rt"))==NULL){ 27 printf("无法打开要编译的源程序"); 28 return 0; 29 } 30 else{ 31 //fgets(str,1000,p); 32 while((c=getc(p))!=EOF){ 33 str[i++] = c; 34 } 35 fclose(p); 36 str[i] = '\0'; 37 for(i=0;i<strlen(str);i++){ 38 if(str[i]=='/'&&str[i+1]=='/'){ 39 while(str[i++]!='\n'){} 40 }//单行注释 41 else if(str[i]=='/'&&str[i+1]=='*'){ 42 while(!(str[i]=='*'&&str[i+1]=='/')){i++;} 43 i+=2; 44 }//多行注释 45 else if(str[i]==' '&&str[i+1]==' '){ 46 while(str[i]==' '){i++;} 47 i--; 48 if(str1[j-1]!=' ') 49 str1[j++]=' '; 50 }//多个空格,去除空格 51 else if(str[i]=='\n') { 52 if(str1[j-1]!=' ') 53 str1[j++]=' '; 54 }//换行处理, 55 else if(str[i]==9){ 56 while(str[i]==9){ 57 i++; 58 } 59 if(str1[j-1]!=' ') 60 str1[j++]=' '; 61 i--; 62 }//tab键处理 63 else str1[j++] = str[i];//其他字符处理 64 } 65 str1[j] = '\0'; 66 if((p = fopen("afterdel.txt","w"))==NULL){ 67 printf("can not find it!"); 68 return 0; 69 } 70 else{ 71 if(fputs(str1,p)!=0){ 72 printf("预处理失败!"); 73 } 74 else printf("预处理成功!"); 75 } 76 fclose(p); 77 } 78 return 0; 79 } 80 81 //设置保留字 82 void set_reserve() 83 { 84 reserved_word[1]="return"; 85 reserved_word[2]="def"; 86 reserved_word[3]="if"; 87 reserved_word[4]="else"; 88 reserved_word[5]="while"; 89 reserved_word[6]="return"; 90 reserved_word[7]="char"; 91 reserved_word[8]="for"; 92 reserved_word[9]="and"; 93 reserved_word[10]="or"; 94 reserved_word[11]="int"; 95 reserved_word[12]="bool"; 96 } 97 98 //看这个字是不是字母 99 bool judge_word(char x) 100 { 101 if(x>='a' && x<='z' || x>='A' && x<='Z' ){ 102 return true; 103 } 104 else return false; 105 } 106 107 //看这个字是不是数字 108 bool judge_number(char x) 109 { 110 if(x>='0' && x<='9'){ 111 return true; 112 } 113 else return false; 114 } 115 116 //看这个字符是不是界符 117 bool judge_jiefu(char x) 118 { 119 if(x=='('||x==')'||x==','||x==';'||x=='{'||x=='}'){ 120 return true; 121 } 122 else return false; 123 } 124 125 126 //加减乘 127 bool judge_yunsuanfu1(char x) 128 { 129 if(x=='+'||x=='-'||x=='*') 130 { 131 return true; 132 } 133 else return false; 134 } 135 136 //等于 赋值,大于小于 大于等于,小于等于,大于小于 137 bool judge_yunsuannfu2(char x) 138 { 139 if(x=='='|| x=='>'||x=='<'||x=='&'||x=='||'){ 140 return true; 141 } 142 else return false; 143 } 144 145 146 //这个最大的函数的总体作用是从文件里读一个单词 147 int scan(FILE *fp) 148 { 149 buffer=fgetc(fp);//读取一个字符 150 if(feof(fp)){//检测结束符 151 flag=0;return 0; 152 } 153 else if(buffer==' ') 154 { 155 row++; 156 return 0; 157 } 158 else if(buffer=='\n') 159 { 160 row=1; 161 return 0; 162 } 163 //如果是字母开头或'_' 看关键字还是普通单词 164 else if(judge_word(buffer) || buffer=='_') 165 { 166 word+=buffer; 167 row++; 168 while((buffer=fgetc(fp)) && (judge_word(buffer) || judge_number(buffer) || buffer=='_')) 169 { 170 word+=buffer; 171 row++; 172 } 173 if(feof(fp)){ 174 flag=0; 175 return 1; 176 } 177 for(int i=1;i<=12;i++){ 178 if(word==reserved_word[i]){ 179 aa=fseek(fp,-1,SEEK_CUR);//如果执行成功,stream将指向以fromwhere为基准,偏移offset(指针偏移量)个字节的位置,函数返回0。 180 return 3; 181 } 182 } 183 aa=fseek(fp,-1,SEEK_CUR); 184 return 1; 185 } 186 187 //开始是加减乘 一定是类型4 188 else if(judge_yunsuanfu1(buffer)) 189 { 190 word+=buffer; 191 row++; 192 return 4; 193 } 194 195 //开始是数字就一定是数字 196 else if(judge_number(buffer)) 197 { 198 word+=buffer; 199 row++; 200 while((buffer=fgetc(fp)) && judge_number(buffer)) 201 { 202 word+=buffer; 203 row++; 204 } 205 if(feof(fp)){ 206 flag=0; 207 return 2; 208 } 209 aa=fseek(fp,-1,SEEK_CUR); 210 return 2; 211 } 212 213 //检验界符 214 else if(judge_jiefu(buffer)) 215 { 216 word+=buffer; 217 row++; 218 return 6; 219 } 220 221 //检验 <=、 >=、 <>、 == =、 <、> 222 else if(judge_yunsuannfu2(buffer)) 223 { 224 row++; 225 word+=buffer; 226 if(buffer=='<') //为了检验题目中的<> <= 227 { 228 buffer=fgetc(fp); 229 if(buffer=='>' || buffer=='=') 230 { 231 word+=buffer; 232 row++; 233 return 5; 234 } 235 } 236 //检验 >= == 237 else{ 238 buffer=fgetc(fp); 239 if(buffer=='=') 240 { 241 word+=buffer; 242 row++; 243 return 5; 244 } 245 } 246 if(feof(fp)){ 247 flag=0; 248 } 249 aa=fseek(fp,-1,SEEK_CUR); 250 return 4; 251 } 252 253 //首字符是/ 有可能是除号 也有可能是注释 254 else if(buffer=='/') 255 { 256 row++; 257 word+=buffer; 258 buffer=fgetc(fp); 259 aa=fseek(fp,-1,SEEK_CUR); 260 return 4; 261 } 262 263 else { 264 word+=buffer; 265 row++; 266 return -1; 267 } 268 } 269 270 int main() 271 { 272 set_reserve();//设置保留字 273 processor(); 274 cout<<"open "<<"afterdel.txt"<<endl; 275 flag=1; 276 FILE *fp; 277 if(!(fp=fopen("afterdel.txt","r"))) 278 { 279 cout<<"not found the file or other error "<<endl; 280 flag=0; 281 } 282 283 while(flag==1) 284 { 285 //flag2 返回的类型 286 flag2=scan(fp);//反复调用函数提取单词 287 288 if(flag2==1) 289 { 290 cout<<"type:1 identifier "<<word<<endl; 291 if(word.length()>20) 292 cout<<"ERROR Identifier length cannot exceed 20 characters"<<endl; 293 word.erase(word.begin(),word.end()); 294 } 295 else if(flag2==3) 296 { 297 cout<<"type:3 reserved word "<<word<<endl; 298 word.erase(word.begin(),word.end()); 299 } 300 else if(flag2==4) 301 { 302 cout<<"type:4 unary_operator "<<word<<endl; 303 word.erase(word.begin(),word.end()); 304 } 305 else if(flag2==2) 306 { 307 cout<<"type:2 positive number "<<word<<endl; 308 //if(word[0]=='0') 309 //cout<<"ERROR: The first digit cannot be 0!"<<endl; 310 word.erase(word.begin(),word.end()); 311 } 312 else if(flag2==6) 313 { 314 cout<<"type:6 Separator "<<word<<endl; 315 word.erase(word.begin(),word.end()); 316 } 317 else if(flag2==5) 318 { 319 cout<<"type:5 double_operator "<<word<<endl; 320 word.erase(word.begin(),word.end()); 321 } 322 //非法字符 323 else if(flag2==-1) 324 { 325 cout<<"Illegal character "<<word<<endl; 326 word.erase(word.begin(),word.end()); 327 } 328 } 329 330 int a=fclose(fp); 331 cout<<"press e to close"<<endl; 332 char end; 333 while(cin>>end && end!='e'){ 334 cout<<"只有e可以关闭"<<endl; 335 } 336 return 0; 337 }
五、实验结果
1.下面是编写的一段源程序,命名为code.txt

2.经过程序执行后,在项目目录下生成了一个新的名为afterdel.txt文件

3.afterdel.txt文件内容如下,经过预处理后去除了多于内容

4.下面是程序词法分析后得到的结果
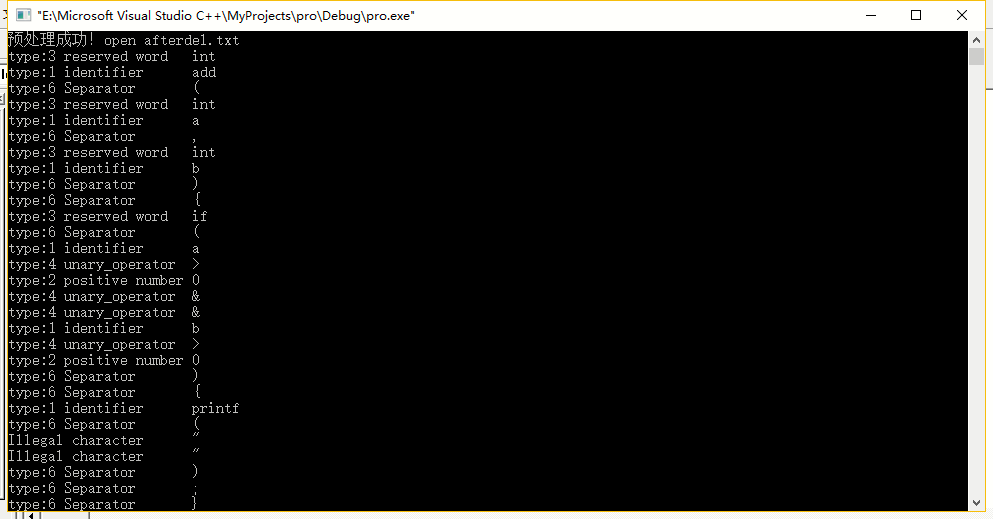
六、实验总结
该词法分析器功能基本具备,能够实现预定要求,本次实验让我了解如何设计编制并调试词法分析程序,加深了我对词法分析器原理的理解。词法分析是编译的第一阶段。词法分析器的主要任务是读入源程序的输入字符,将它们组成词素,生成并输出一个词法单元序列,这个词法单元序列被输出到语法分析器进行语法分析。另外,由于词法分析器在编译器中负责读取源程序,因此除了识别词素之外,它还会完成一些其他任务,比如过滤掉源程序中的注释和空白,将编译器生成的错误消息与源程序的位置关联起来等。