多变量线性回归(Linear Regression with Multiple Variables)
4.1 多维特征
目前为止,我们探讨了单变量/特征的回归模型,现在我们对房价模型增加更多的特征,例如房间数楼层等,构成一个含有多个变量的模型,模型中的特征为 ( x 1 , x 2 , . . . , x n ) \left( {x_{1}},{x_{2}},...,{x_{n}} \right) (x1,x2,...,xn)。
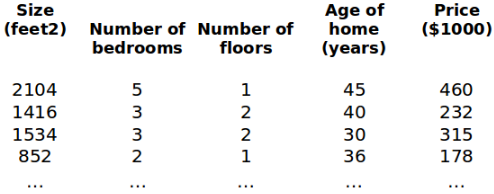
增添更多特征后,我们引入一系列新的注释:
n n n 代表特征的数量
x ( i ) {x^{\left( i \right)}} x(i)代表第 i i i 个训练实例,是特征矩阵中的第 i i i行,是一个向量(vector)。
比方说,上图的
x ( 2 ) = [ 1416 3 2 40 ] {x}^{(2)}\text{=}\begin{bmatrix} 1416\\ 3\\ 2\\ 40 \end{bmatrix} x(2)=⎣⎢⎢⎡14163240⎦⎥⎥⎤,
x j ( i ) {x}_{j}^{\left( i \right)} xj(i)代表特征矩阵中第 i i i 行的第 j j j 个特征,也就是第 i i i 个训练实例的第 j j j 个特征。
如上图的 x 2 ( 2 ) = 3 , x 3 ( 2 ) = 2 x_{2}^{\left( 2 \right)}=3,x_{3}^{\left( 2 \right)}=2 x2(2)=3,x3(2)=2,
支持多变量的假设 h h h 表示为: h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ n x n h_{\theta}\left( x \right)={\theta_{0}}+{\theta_{1}}{x_{1}}+{\theta_{2}}{x_{2}}+...+{\theta_{n}}{x_{n}} hθ(x)=θ0+θ1x1+θ2x2+...+θnxn,
这个公式中有 n + 1 n+1 n+1个参数和 n n n个变量,为了使得公式能够简化一些,引入 x 0 = 1 x_{0}=1 x0=1,则公式转化为: h θ ( x ) = θ 0 x 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ n x n h_{\theta} \left( x \right)={\theta_{0}}{x_{0}}+{\theta_{1}}{x_{1}}+{\theta_{2}}{x_{2}}+...+{\theta_{n}}{x_{n}} hθ(x)=θ0x0+θ1x1+θ2x2+...+θnxn
此时模型中的参数是一个 n + 1 n+1 n+1维的向量,任何一个训练实例也都是 n + 1 n+1 n+1维的向量,特征矩阵 X X X的维度是 m ∗ ( n + 1 ) m*(n+1) m∗(n+1)。 因此公式可以简化为: h θ ( x ) = θ T X h_{\theta} \left( x \right)={\theta^{T}}X hθ(x)=θTX,其中上标 T T T代表矩阵转置。
4.2 多变量梯度下降
与单变量线性回归类似,在多变量线性回归中,我们也构建一个代价函数,则这个代价函数是所有建模误差的平方和,即: J ( θ 0 , θ 1 . . . θ n ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 J\left( {\theta_{0}},{\theta_{1}}...{\theta_{n}} \right)=\frac{1}{2m}\sum\limits_{i=1}^{m}{ { {\left( h_{\theta} \left({x}^{\left( i \right)} \right)-{y}^{\left( i \right)} \right)}^{2}}} J(θ0,θ1...θn)=2m1i=1∑m(hθ(x(i))−y(i))2 ,
其中: h θ ( x ) = θ T X = θ 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ n x n h_{\theta}\left( x \right)=\theta^{T}X={\theta_{0}}+{\theta_{1}}{x_{1}}+{\theta_{2}}{x_{2}}+...+{\theta_{n}}{x_{n}} hθ(x)=θTX=θ0+θ1x1+θ2x2+...+θnxn ,
我们的目标和单变量线性回归问题中一样,是要找出使得代价函数最小的一系列参数。 多变量线性回归的批量梯度下降算法为:

当 n > = 1 n>=1 n>=1时, θ 0 : = θ 0 − a 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x 0 ( i ) {
{\theta }{0}}:={
{\theta }{0}}-a\frac{1}{m}\sum\limits_{i=1}^{m}{({
{h}{\theta }}({
{x}^{(i)}})-{
{y}^{(i)}})}x{0}^{(i)} θ0:=θ0−am1i=1∑m(hθ(x(i))−y(i))x0(i)
θ 1 : = θ 1 − a 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x 1 ( i ) { {\theta }{1}}:={ {\theta }{1}}-a\frac{1}{m}\sum\limits_{i=1}^{m}{({ {h}{\theta }}({ {x}^{(i)}})-{ {y}^{(i)}})}x{1}^{(i)} θ1:=θ1−am1i=1∑m(hθ(x(i))−y(i))x1(i)
θ 2 : = θ 2 − a 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x 2 ( i ) { {\theta }{2}}:={ {\theta }{2}}-a\frac{1}{m}\sum\limits_{i=1}^{m}{({ {h}{\theta }}({ {x}^{(i)}})-{ {y}^{(i)}})}x{2}^{(i)} θ2:=θ2−am1i=1∑m(hθ(x(i))−y(i))x2(i)
我们开始随机选择一系列的参数值,计算所有的预测结果后,再给所有的参数一个新的值,如此循环直到收敛。
代码示例:
计算代价函数 J ( θ ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 J\left( \theta \right)=\frac{1}{2m}\sum\limits_{i=1}^{m}{ { {\left( {h_{\theta}}\left( {x^{(i)}} \right)-{y^{(i)}} \right)}^{2}}} J(θ)=2m1i=1∑m(hθ(x(i))−y(i))2 其中: h θ ( x ) = θ T X = θ 0 x 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ n x n {h_{\theta}}\left( x \right)={\theta^{T}}X={\theta_{0}}{x_{0}}+{\theta_{1}}{x_{1}}+{\theta_{2}}{x_{2}}+...+{\theta_{n}}{x_{n}} hθ(x)=θTX=θ0x0+θ1x1+θ2x2+...+θnxn
Python 代码:
def computeCost(X, y, theta):
inner = np.power(((X * theta.T) - y), 2)
return np.sum(inner) / (2 * len(X))
4.3 梯度下降法实践1-特征缩放
在我们面对多维特征问题的时候,我们要保证这些特征都具有相近的尺度,这将帮助梯度下降算法更快地收敛。
以房价问题为例,假设我们使用两个特征,房屋的尺寸和房间的数量,尺寸的值为 0-2000平方英尺,而房间数量的值则是0-5,以两个参数分别为横纵坐标,绘制代价函数的等高线图能,看出图像会显得很扁,梯度下降算法需要非常多次的迭代才能收敛。
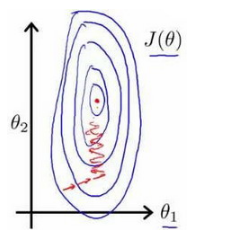
解决的方法是尝试将所有特征的尺度都尽量缩放到-1到1之间。如图:
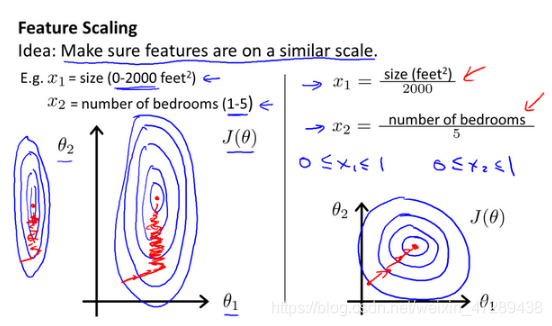
最简单的方法是令: x n = x n − μ n s n {
{x}{n}}=\frac{
{
{x}{n}}-{
{\mu}{n}}}{
{
{s}{n}}} xn=snxn−μn,其中 μ n {\mu_{n}} μn是平均值, s n {s_{n}} sn是标准差。