机器学习-数据科学库:Pandas总结(2)
Pandas数据分析项目练习
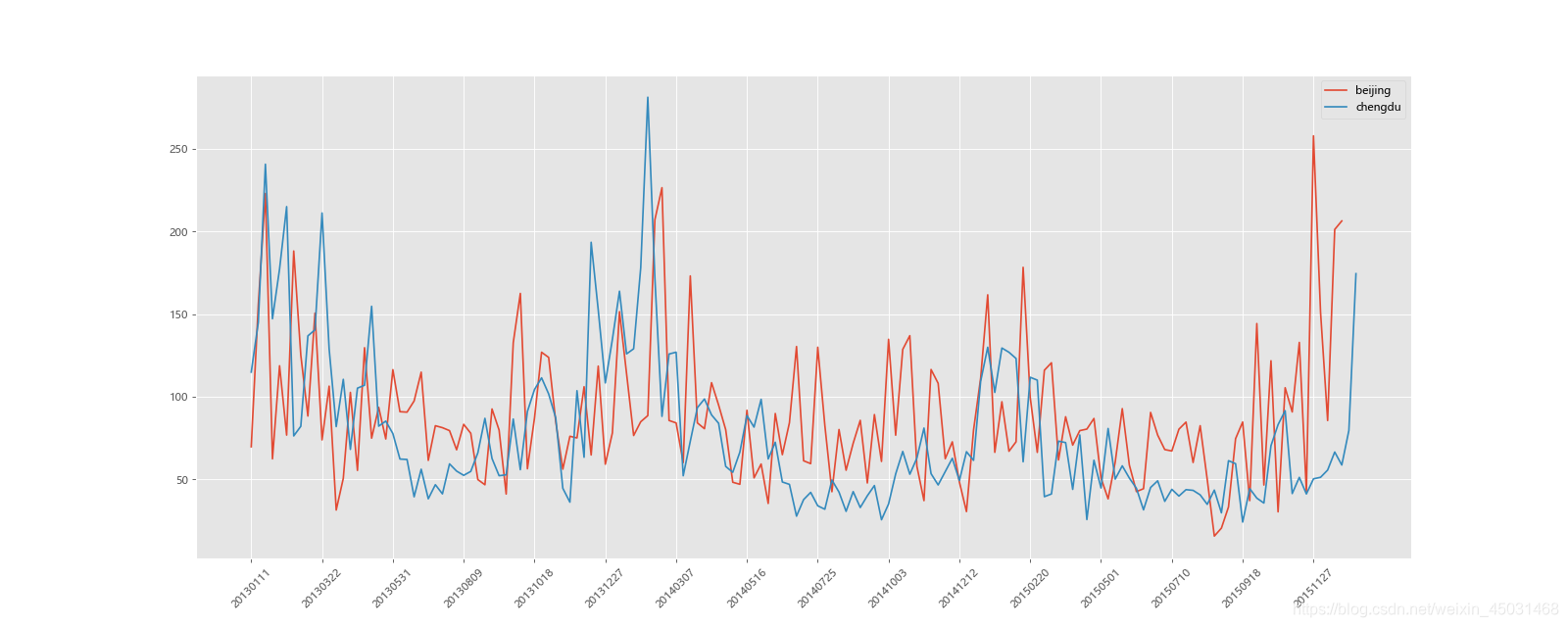
现在我们有北上广、深圳、和沈阳5个城市空气质量数据,请绘制出5个城市的PM2.5随时间的变化情况。
数据来源: https://www.kaggle.com/uciml/pm25-data-for-five-chinese-cities
代码示例:画出北京和成都,其他城市方法相同。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df_beijing = pd.read_csv("./BeijingPM20100101_20151231.csv")
df_chengdu = pd.read_csv("./ChengduPM20100101_20151231.csv")
df_guangzhou = pd.read_csv("./GuangzhouPM20100101_20151231.csv")
df_shanghai = pd.read_csv("./ShanghaiPM20100101_20151231.csv")
df_shenyang = pd.read_csv("./ShenyangPM20100101_20151231.csv")
# print(df_beijing.info())
# print(df_chengdu.info())
df_beijing["timstamp"] = pd.PeriodIndex(year=df_beijing["year"], month=df_beijing["month"], day=df_beijing["day"], hour=df_beijing["hour"], freq="H")
df_chengdu["timstamp"] = pd.PeriodIndex(year=df_beijing["year"], month=df_beijing["month"], day=df_beijing["day"], hour=df_beijing["hour"], freq="H")
# print(df_beijing.info())
df_beijing.set_index("timstamp", inplace=True)
df_chengdu.set_index("timstamp", inplace=True)
_x1 = df_beijing["PM_Dongsi"].resample("7D").mean().dropna().index
_y1 = df_beijing["PM_Dongsi"].resample("7D").mean().dropna()
_x2 = df_chengdu["PM_Caotangsi"].resample("7D").mean().dropna().index
_y2 = df_chengdu["PM_Caotangsi"].resample("7D").mean().dropna()
_x1 = [i.strftime("%Y%m%d") for i in _x1]
_x2 = [i.strftime("%Y%m%d") for i in _x2]
print(len(_x1),len(_y1))
print(len(_x2),len(_y2))
#设置字体和负号的代码
plt.rcParams['font.sans-serif']=['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
#绘图风格
plt.style.use('ggplot')
#图片大小
plt.figure(figsize=(20,8), dpi = 80)
plt.plot(range(len(_x1)), _y1, label="beijing")
plt.plot(range(len(_x2)), _y2, label="chengdu")
plt.xticks(range(0,len(_x1),10), _x1[::10], rotation=45)
plt.legend(loc="best")
plt.show()