(一)什么是pandas
pandas is an open source, BSD-licensed library providing high-performance, easy-to-use data structures and data analysis tools for the Python programming language.
(二) pandas安装
2.1 直接命令安装
pip install pandas
这种安装可能会安装不成功。
2.2 下载pipy文件安装
- 下载链接:https://pypi.org/project/pandas/#files
或百度搜索:pandas pypi - 进入页面点击:
Download file

- 下载对应的文件:
whl文件下载:pandas-1.3.0-cp38-cp38-win_amd64.whl
安装可以参照我之前写的:Python下载并安装第三方库(cvxpy)链接如下:
https://blog.csdn.net/weixin_54546190/article/details/119056938
压缩文件下载:pandas-1.3.0.tar.gz
先把这个安装包解压,在看解压的文件夹中是否有setup.py文件。
法一:
- 打开cmd
- 进入安装目录(这个本人在Windows系统下,也不知如何进入下载setup.py的目录)
- python setup.py build(对setup.py编译)
- python setuo.py install
法二:
5. 直接进入setup.py的下载目录中,在空白处点击Shift键,再右击鼠标,点击进入在此处打开powershell命令(s),这样等于法一的1、2两步。在执行3、4两步即可。
6. python setup.py build(对setup.py编译)
7. python setuo.py install
(三)pandas的常用数据类型
3.1 pandas之Series创建
Series 一维,带标签数组
通过下面的六种代码输出,你就能清楚理解Series
import string
import numpy as np
import pandas as pd
- 一
idex_ar_1 = pd.Series([1,2,31,12,3,4])
print(type(idex_ar_1))
print("*************")
print(idex_ar_1)
OUT:
<class 'pandas.core.series.Series'>
*************
0 1
1 2
2 31
3 12
4 3
5 4
dtype: int64
- 二
idex_ar_2 = pd.Series([1,2,31,12,3,4],index=list('abcdef'))
print('\n')
print(type(idex_ar_2))
print("*************")
print(idex_ar_2)
OUT:
<class 'pandas.core.series.Series'>
*************
a 1
b 2
c 31
d 12
e 3
f 4
dtype: int64
- 三
idex_ar_3 = pd.Series(np.arange(8),index=list(string.ascii_letters[:8]))
## string.ascii_letters[:8]指索引从 a 到 h
print('\n')
print(type(idex_ar_3))
print("*************")
print(idex_ar_3)
OUT:
<class 'pandas.core.series.Series'>
*************
a 0
b 1
c 2
d 3
e 4
f 5
g 6
h 7
dtype: int32
- 四
idex_ar_4 = pd.Series(np.arange(7),index=list(string.ascii_letters[5:12]))
### string.ascii_letters[5:12]指索引从 f 到 l
print('\n')
print(type(idex_ar_4))
print("*************")
print(idex_ar_4)
OUT:
<class 'pandas.core.series.Series'>
*************
f 0
g 1
h 2
i 3
j 4
k 5
l 6
dtype: int32
- 五
idex_ar_5 = pd.Series(idex_ar_3,index=list(string.ascii_letters[5:12]))
## 重新给其 idex_ar_3 定义索引之后,如果能够对应上,就取其值,如果不能,多余的索引就会显示 Nan
print('\n')
print(idex_ar_5)
OUT:
f 5.0
g 6.0
h 7.0
i NaN
j NaN
k NaN
l NaN
dtype: float64
- 六
print("\n我们可以用字典创建Seires")
t1 = {
"name":"源仔","age":24,"tel":1008611}
T1 = pd.Series(t1)
print(T1)
print(type(T1))
OUT:
我们可以用字典创建Seires
name 源仔
age 24
tel 1008611
dtype: object
<class 'pandas.core.series.Series'>
3.2 pandas之Series切片和索引
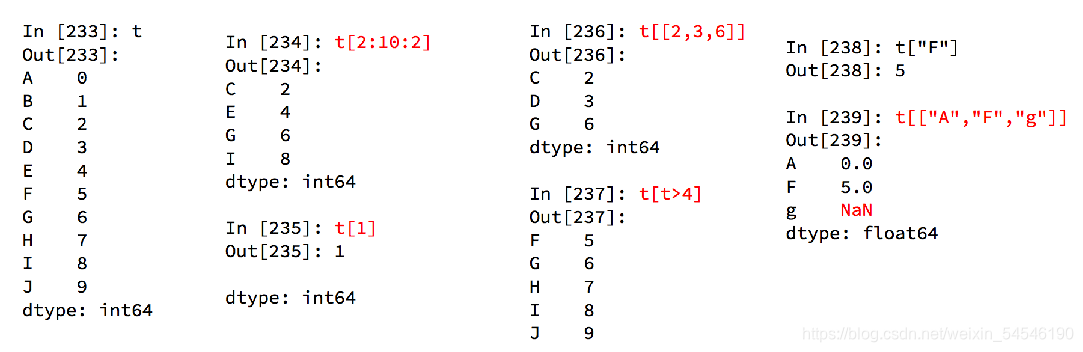


补充:
print("\n补充")
print(T1)
print(len(T1.index))
print('**************************')
print(list(T1.index))
print('**************************')
print(list(T1.index)[:2])
print('**************************')
print(type(T1.values))
OUT:
补充
name 源仔
age 24
tel 1008611
dtype: object
3
**************************
['name', 'age', 'tel']
**************************
['name', 'age']
**************************
<class 'numpy.ndarray'>
3.3 Series的其他方法
我们可以百度查看啊,比如:pandas.Series.where
链接:
https://pandas.pydata.org/pandasdocs/stable/reference/api/pandas.Series.where.html
或直接百度:pandas.Series
链接:
https://pandas.pydata.org/pandasdocs/stable/reference/api/pandas.Series.html

(四)pandas之读取外部数据
4.1 读取csv文件
dogNames2.csv文件 链接:https://pan.baidu.com/s/1M6ETlxqEo2jl3g2wjixm_Q
提取码:qaqx
# coding=utf-8
import pandas as pd
from pymongo import MongoClient
# pandas读取csv中的文件
df = pd.read_csv("D:/拜师教育/课程资料/数据结构基础/第二章:数据科学库基础/14100_HM数据科学库课件/DataAnalysis-master/day04/dogNames2.csv")
print(df)
OUT:
0 RENNY 1
1 DEEDEE 2
2 GLADIATOR 1
3 NESTLE 1
4 NYKE 1
... ... ...
4159 ALEXXEE 1
4160 HOLLYWOOD 1
4161 JANGO 2
4162 SUSHI MAE 1
4163 GHOST 3
[4164 rows x 2 columns]
4.2 读取mysql或者mongodb文件
1.
# 读取mysql文件
pd.read_sql(sql_sentence,connection)
2. 那么,mongodb呢?
# coding=utf-8
import pandas as pd
from pymongo import MongoClient
client = MongoClient()
collection = client["douban"]["tv1"]
data = list(collection.find())
t1 = data[0]
t1 = pd.Series(t1)
print(t1)
OUT:

为什么报错呢!
- 安装pymongo不代表MongoDB数据库安装好了,这两个是分开安装的。
-
pymongo安装
直接在命令提示符窗口输入:pip install pymongo即可. -
MongoDB数据库安装
这里转载别人的链接:https://blog.csdn.net/weixin_43876186/article/details/108702940
4.3 pandas之DataFrame
4.3.1 pd.dataFrame()的用法
- 如何编写
pd.DataFrame(np.arange().reshape(,))
- 代码
import pandas as pd
import numpy as np
t1 = pd.DataFrame(np.arange(12).reshape(3,4))
print(t1)
t2 = pd.DataFrame(np.arange(12).reshape(3,4),index=list("abc"),columns=list("WXYZ"))
print("\n")
print(t2)
OUT:
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
W X Y Z
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
- 如何用字典表示DataFrame
d1 = {
"name":["源仔","总统"],"age":["10086","10010"],}
t3 = pd.DataFrame(d1)
print("\n")
print(d1)
print(t3)
print(type(t3))
d2 = [{
"name":"ziaoming","age":"24","tel":"11000"},{
"name":"源仔","tel":"11070"},{
"name":"ling","age":"4","tel":"4500"}]
t4 = pd.DataFrame(d2)
print("\n")
print(d2)
print(t4)
OUT:`
{'name': ['源仔', '总统'], 'age': ['10086', '10010']}
name age
0 源仔 10086
1 总统 10010
<class 'pandas.core.frame.DataFrame'>
[{'name': 'ziaoming', 'age': '24', 'tel': '11000'}, {'name': '源仔', 'tel': '11070'}, {'name': 'ling', 'age': '4', 'tel': '4500'}]
name age tel
0 ziaoming 24 11000
1 源仔 NaN 11070
2 ling 4 4500
##DataFrame的基础属性
- DataFrame的基础属性
import numpy as np
import pandas as pd
d2 = [{
"name":"ziaoming","age":"24","tel":"11000"},{
"name":"源仔","tel":"11070"},{
"name":"ling","age":"4","tel":"4500"}]
t2 = pd.DataFrame(d2)
print(t2)
print("*************************")
print(t2.index)
print("*************************")
print(t2.columns)
print("*************************")
print(t2.values)
print("*************************")
print(t2.shape)
print("*************************")
print(t2.dtypes)
OUT:
name age tel
0 ziaoming 24 11000
1 源仔 NaN 11070
2 ling 4 4500
*************************
RangeIndex(start=0, stop=3, step=1)
*************************
Index(['name', 'age', 'tel'], dtype='object')
*************************
[['ziaoming' '24' '11000']
['源仔' nan '11070']
['ling' '4' '4500']]
*************************
(3, 3)
*************************
name object
age object
tel object
dtype: object
- DtataFrame整体情况调查
print("\n")
print(t2.head(1)) # 取头一行
print("*"*15)
print(t2.tail(2)) # 取后两行
print("\n")
print(t2.info())
OUT:
name age tel
0 ziaoming 24 11000
***************
name age tel
1 源仔 NaN 11070
2 ling 4 4500
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 name 3 non-null object
1 age 2 non-null object
2 tel 3 non-null object
dtypes: object(3)
memory usage: 200.0+ bytes
None
4.3.2 d_names.sort_values()的排序的方法
dogNames2.csv文件 链接:https://pan.baidu.com/s/1M6ETlxqEo2jl3g2wjixm_Q
提取码:qaqx
d_names.sort_values(by="Count_AnimalName",ascending=False)
## by="Count_AnimalName"按照Count_AnimalName这一列进行排序
## ascending=False:降序排列。ascending=True:升序排列。不写默认为升序。
import numpy as np
import pandas as pd
d_names = pd.read_csv("D:/拜师教育/课程资料/数据结构基础/第二章:数据科学库基础/14100_HM数据科学库课件/DataAnalysis-master/day04/dogNames2.csv")
print(d_names.head()) # 默认为前5个
print("%"*50)
print(d_names.info())
# dataFrame中排序方法
print('\n')
print("*"*50)
d1 = d_names.sort_values(by="Count_AnimalName",ascending=False)
## by="Count_AnimalName"按照Count_AnimalName这一列进行排序
## ascending=False:降序排列。ascending=True:升序排列。不写默认为升序。
print(d1)
print("%"*50)
print(d1.tail(10)) # 输出最后十个
print("%"*50)
prnt(d1.head(5)) # 输出前五个
OUT:
Row_Labels Count_AnimalName
0 RENNY 1
1 DEEDEE 2
2 GLADIATOR 1
3 NESTLE 1
4 NYKE 1
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4164 entries, 0 to 4163
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Row_Labels 4164 non-null object
1 Count_AnimalName 4164 non-null int64
dtypes: int64(1), object(1)
memory usage: 65.2+ KB
None
**************************************************
Row_Labels Count_AnimalName
858 BELLA 112
4134 MAX 82
3273 LUCY 82
843 BUDDY 79
433 SADIE 77
... ... ...
1654 RUBY ROSE 1
1655 MOO MOO 1
1656 KYLIE 1
1657 JEEP 1
2082 ANIOT 1
[4164 rows x 2 columns]
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
Row_Labels Count_AnimalName
1643 T. C. 1
1646 BERAND 1
1649 CHAUNCEY 1
1650 BELLA MARIE 1
1653 VIVIAN 1
1654 RUBY ROSE 1
1655 MOO MOO 1
1656 KYLIE 1
1657 JEEP 1
2082 ANIOT 1
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
Row_Labels Count_AnimalName
858 BELLA 112
4134 MAX 82
3273 LUCY 82
843 BUDDY 79
433 SADIE 77
(五)pandas 的常用小知识点
5.1 切片在DataFrame中的用法
d1[:10]["Row_Labels"]
# 取Row_Labels这一标签列的0到10行
实例如下:
import numpy as np
import pandas as pd
d_names = pd.read_csv("D:/拜师教育/课程资料/数据结构基础/第二章:数据科学库基础/14100_HM数据科学库课件/DataAnalysis-master/day04/dogNames2.csv")
d1 = d_names.sort_values(by="Count_AnimalName",ascending=False)
print(d1[:10])
print("%"*50)
print(d1[:10]["Row_Labels"])
print("%"*50)
print(type(d1[:10]["Row_Labels"]))
# 因为只取Row_Labels一列,所以是<class 'pandas.core.series.Series'
5.2 pandas之.lic和.iloc
.loc通过标签索引行数据.iloc通过位置获取行数据
一定注意图片中的红色字体:


5.3 pandas赋值更改数据

5.4 pandas之布尔索引
# coding=utf-8
import pandas as pd
from pymongo import MongoClient
# pandas读取csv中的文件
df = pd.read_csv("D:/拜师教育/课程资料/数据结构基础/第二章:数据科学库基础/14100_HM数据科学库课件/DataAnalysis-master/day04/dogNames2.csv")
# 取Count_AnimalName索引小于20的
print(df[df["Count_AnimalName"]<20])
print("%"*50)
# 取Count_AnimalName索引大于18小于20的
print(df[(18<df["Count_AnimalName"])&(df["Count_AnimalName"]<20)]) # 符号&:表示与
OUT:
Row_Labels Count_AnimalName
0 RENNY 1
1 DEEDEE 2
2 GLADIATOR 1
3 NESTLE 1
4 NYKE 1
... ... ...
4159 ALEXXEE 1
4160 HOLLYWOOD 1
4161 JANGO 2
4162 SUSHI MAE 1
4163 GHOST 3
[4087 rows x 2 columns]
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
Row_Labels Count_AnimalName
714 WINSTON 19
868 KATIE 19
886 SUGAR 19
994 NALA 19
1391 PRINCESS 19
1985 RANGER 19
3147 MILO 19
3943 MINNIE 19
4025 ZEUS 19
回到之前狗的名字的问题上,假如我们想找到所有的使用次数超过700并且名字的字符串的长度大于4的狗的名字,应该怎么选择?

回到之前狗的名字的问题上,假如我们想找到所有的使用次数超过700并且名字的字符串的长度大于4的狗的名字,应该怎么选择?
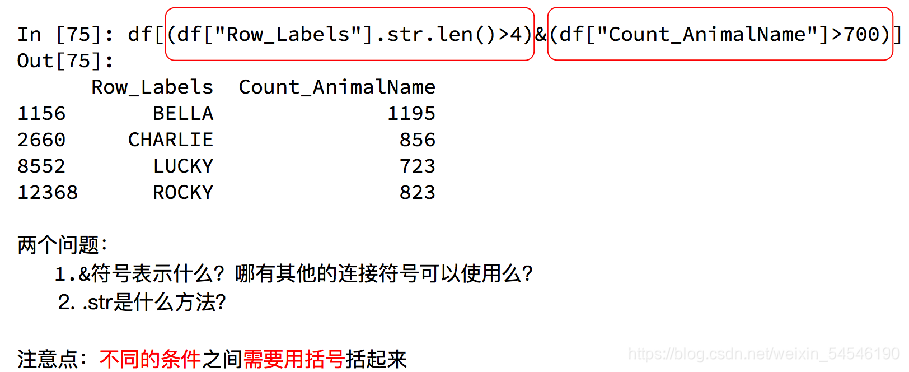
5.5 pandas之字符串方法

5.6 pandas缺失数据的处理
- 我们的数据缺失通常有两种情况:
- 一种就是空,None等,在pandas是
NaN(和np.nan一样) - 另一种是我们让其为
0,蓝色框中

- 对于NaN的数据
- 判断数据是否为NaN:
pd.isnull(df),pd.notnull(df)
pd.isnull(df)判断当前数据中是否有NaN,有为True,否则为False
Pandas dataframe.notnull()功能检测 DataFrame 中的现有/非缺失值。该函数返回一个布尔对象,其大小与其所应用的对象的大小相同,指示每个单独的值是否为na是否有价值。所有非缺失值都映射为true,而缺失值则映射为false。
import numpy as np
import pandas as pd
d2 = [{
"name":"ziaoming","age":"24","tel":"11000"},{
"name":"源仔","tel":"11070"},{
"name":"ling","age":"4","tel":"4500"}]
t2 = pd.DataFrame(d2)
print(t2)
print("%"*50)
# 判断当前数据中是否有NaN,有为True,否则为False
T2 = pd.isnull(t2)
print(T2)
print("%"*50)
T3 = pd.notnull(t2)
print(T3)
print("%"*50)
print(pd.notnull(t2))
OUT:
name age tel
0 ziaoming 24 11000
1 源仔 NaN 11070
2 ling 4 4500
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
name age tel
0 False False False
1 False True False
2 False False False
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
name age tel
0 True True True
1 True False True
2 True True True
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
name age tel
0 True True True
1 True False True
2 True True True
print(t2)
print("%"*50)
# 取只要name这一列没有NaN,就都能取得
T4 = t2[pd.notnull(t2["name"])]
print(T4)
print("%"*50)
# age这一列第二行含有NaN,所以取不到第二行
T5 = t2[pd.notnull(t2["age"])]
print(T5)
OUT:
name age tel
0 ziaoming 24 11000
1 源仔 NaN 11070
2 ling 4 4500
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
name age tel
0 ziaoming 24 11000
1 源仔 NaN 11070
2 ling 4 4500
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
name age tel
0 ziaoming 24 11000
2 ling 4 4500
- 处理方式1:删除NaN所在的行列
dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
-
axis:轴。0或’index’,表示按行删除;1或’columns’,表示按列删除。
-
how:筛选方式。‘any’,表示该行/列只要有一个以上的空值,就删除该行/列;‘all’,表示该行/列全部都为空值,就删除该行/列。
-
thresh:非空元素最低数量。int型,默认为None。如果该行/列中,非空元素数量小于这个值,就删除该行/列。
-
subset:子集。列表,元素为行或者列的索引。如果axis=0或者‘index’,subset中元素为列的索引;如果axis=1或者‘column’,subset中元素为行的索引。由subset限制的子区域,是判断是否删除该行/列的条件判断区域。
-
inplace:是否原地替换。布尔值,默认为False。如果为True,则在原DataFrame上进行操作,返回值为None。
-
具体可查看
转载:https://blog.csdn.net/qq_17753903/article/details/89817371
print(t2)
T5 = t2.dropna(axis=0,how="any")
print("%"*50)
print(T5)
T6 = t2.dropna(axis=0,how="all")
print("%"*50)
print(T6)
T7 = t2.dropna(axis=0,how="any",inplace=True)
print("%"*50)
print(T7)
OUT:
name age tel
0 ziaoming 24 11000
1 源仔 NaN 11070
2 ling 4 4500
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
name age tel
0 ziaoming 24 11000
2 ling 4 4500
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
name age tel
0 ziaoming 24 11000
1 源仔 NaN 11070
2 ling 4 4500
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
None
- 处理方式2:填充数据 ;
t.fillna(t.mean());t.fiallna(t.median());t.fillna(0)
1. t.fillna(3) 把所有NaN填充为3.
import numpy as np
import pandas as pd
d2 = [{
"name":"yanzai","age":20.0,'tel':np.nan},{
"name":"ziaoming","age":24.0,"tel":176.0},{
"name":"ling","age":30.0,"tel":170.0}]
t2 = pd.DataFrame(d2)
print(t2)
# 填充NaN
T3 = t2.fillna(3) # 填充NaN为3
print("%"*40)
print(T3)
OUT:
name age tel
0 yanzai 20.0 NaN
1 ziaoming 24.0 176.0
2 ling 30.0 170.0
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
name age tel
0 yanzai 20.0 3.0
1 ziaoming 24.0 176.0
2 ling 30.0 170.0
2. t.fillna(t.mean())
❤️. 对Dataframe取平均值,用平均值填充NaN
a = pd.DataFrame([{
'name':'a','h':180,'w':10066},{
'name':'b','h':np.nan,'w':10666},{
'name':'c','h':160,'w':10086}])
a = a.fillna(a.mean())
print("%"*40)
print(a)
OUT:
name h w
0 a 180.0 10066
1 b 170.0 10666
2 c 160.0 10086
❤️.指定取哪一列的平均数
b = a["h"].fillna(t2["age"].mean())
# 指定取哪一列的平均数
b = a["h"].fillna(t2["age"].mean())
print("%"*40)
print(b)
# 把指定一列的平均数重新付给a,相当于a = a.fillna(a.mean())的结果
a["age"] = b
print("%"*40)
print(a)
OUT:
0 180.0
1 170.0
2 160.0
Name: h, dtype: float64
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
name h w age
0 a 180.0 10066 180.0
1 b 170.0 10666 170.0
2 c 160.0 10086 160.0
❤️. pandas和Numpy求均值的区别
a["age"][1] = np.nan
print("\n")
print("%"*40)
print(a)
# pandas和Numpy求均值的区别
print(a["age"].mean())
# 可以看出pandas算均值时,不会把NaN加入,但是Numpy只要含有NaN,结果肯定为NaN。
OUT:
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
name h w age
0 a 180.0 10066 180.0
1 b 170.0 10666 NaN
2 c 160.0 10086 160.0
170.0
- 处理为0的数据:t[t==0]=np.nan,当然并不是每次为0的数据都需要处理
计算平均值等情况,nan是不参与计算的,但是0会
(六)pandas常用统计方法
6.1 实例
假设现在我们有一组从2006年到2016年1000部最流行的电影数据,我们想知道这些电影数据中评分的平均分,导演的人数等信息,我们应该怎么获取?
数据来源于:https://www.kaggle.com/damianpanek/sunday-eda/data
百度网盘链接:https://pan.baidu.com/s/1vD7VH3EnMpRIQj_PtnPF-g
提取码:4n8q
- 先查看一下数据集:
#coding = uft-8
import pandas as pd
file_path = "datasets_IMDB-Movie-Data.csv"
df = pd.read_csv(file_path)
print(df.info())
print("$"*70)
print(df.head(1))
OUT:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Rank 1000 non-null int64
1 Title 1000 non-null object
2 Genre 1000 non-null object
3 Description 1000 non-null object
4 Director 1000 non-null object
5 Actors 1000 non-null object
6 Year 1000 non-null int64
7 Runtime (Minutes) 1000 non-null int64
8 Rating 1000 non-null float64
9 Votes 1000 non-null int64
10 Revenue (Millions) 872 non-null float64
11 Metascore 936 non-null float64
dtypes: float64(3), int64(4), object(5)
memory usage: 93.9+ KB
None
$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$
Rank Title ... Revenue (Millions) Metascore
0 1 Guardians of the Galaxy ... 333.13 76.0
[1 rows x 12 columns]
- 由题目知:我们想知道这些电影数据中评分的平均分
那就是求Rating的平均数:
- 方法一:len(set(df[].tolist()))
- 方法二:len(df[].unique())
# 获取平均评分
print("\n获取平均评分")
print(df["Rating"].mean())
# 获取导演的人数
print("\n获取导演的人数")
print(len(set(df["Director"].tolist())))
# 获取导演的人数。方法二
print("\n获取导演的人数。方法二")
#print(df["Director"].unique()) # 这是获取导演的名字,并以列表形式填充出来
print(len(df["Director"].unique()))
OUT
获取平均评分
6.723200000000003
获取导演的人数
644
获取导演的人数。方法二
644
# 获取所有演员的人数
temp_actors_list = df["Actors"].str.split(",").tolist()
# str.split(","):表示字符串之间用逗号进行切割
# tolist()指以列表形式呈现
actors_list = [i for j in temp_actors_list for i in j]
actors_nums = len(set(actors_list))
print("\n获取所有演员的人数")
print(actors_nums)
OUT:
获取所有演员的人数
2394

6.2 解释一下上面一些代码的含义
set()
参考链接转载:https://blog.csdn.net/TCatTime/article/details/82312600str.split()
参考链接转载:https://www.runoob.com/python/att-string-split.html
https://www.w3school.com.cn/python/ref_string_split.asptolist():
就是把数组矩阵转化成列表形式
参考链接转载:https://blog.csdn.net/qq_18433441/article/details/55045035