1.1 pandas库总体说明
Pandas基于NumPy、SciPy补充的大量数据操作功能,能实现统计、分组、排序、透视表,可以代替Excel的绝大部分功能
Pandas主要有2种重要数据结构:Series、DataFrame(一维序列,二维表)。数据类型的转换需要用到pd.Series/DataFrame.
(1)Series
可以是一个样本的所有观测值或一个样本的某一属性的观测值
如利用NumPy生成一个正态分布的伪随机数,共含4个值
Series1 = pd.Series(np.random.randn(4))
结果就自动添加了行索引index
0 -1.344609
1 0.177173
2 0.554958
3 -0.576237
过滤Series的方法是:print Series1<0 或 print Series1[Series1 < 0]。前者给出Boolean类型的输出,后者给出具体的数值,仅仅输出Series中小于0的数值。
可以使用Key-Value的方式存储数据:
Series2 = pd.Series(Series1.values,index=['row_'+unicode(i) for i in range(4)])
同样,Python的基础数据结构字典也可以转化为Series。
Series3 = pd.Series({"China":"Beijing","England":"GB","Japan":"Tokyo"})
输出结果依旧是一个序列,但是因为字典是无序的,所有有可能的操作会打扰原字典的顺序。如果需要顺序不变,可以使用下面的方法明确指定这种秩序。
Series4_indexList = ["China",Japan","England"]
Series4 = pd.Series(Series3,index=Series4_indexList)
某些时候,index列表没有相应的对应值,这样会默认填补为空值,可以使用isnull(0,notnull())来返回boolean结果。
Series5_indexList = ["A",B","C","C"]
Series5 = pd.Series(Series1.values,index=Series5_indexList)
index允许重复,但是这样很容易导致错误。
(2)DataFrame
DataFrame可以视作Series的有序集合,可以从数据库、NumPy二维数组、JSON中定义数据框。
NumPy二维数组:
DF1 = pd.DataFrame(np.array([("Japan","Tokyo",4000),("S.Korea","Seoul",1000),("China","Beijing",9000)]),columns=["nation","capital","GDP"])
JSON:
DF2 = pd.DataFrame({"nation":["Japan","S.Korea","China"],"capital":["Tokyo","Seoul","Beijing"],"GDP":[4000,1000,9000]})
但是字典的key是无序的,所以我们又要用到刚才Series中的类似方法加以解决:
DF3 = pd.DataFrame(DF2,columns=["nation","capital","GDP"])
对应地,还可以认为指定行标秩序。
DF4 = pd.DataFrame(DF2,columns=["nation","capital","GDP"],index=[2,0,1])
在DataFrame中切片:
取列:推荐使用DF4["GDP"],最好别用DF4.GDP,容易与一些关键字(保留字)冲突
取行:DF4[0:1]或者DF4.ix[0]
区别在于前者取了第一行,后者取了index为0的第一行。
此外,如果要在数据框动态增加列,不能用"."的方式,而要用[]
DF4["region"]="East Asian"
1.2 代表性函数使用介绍
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
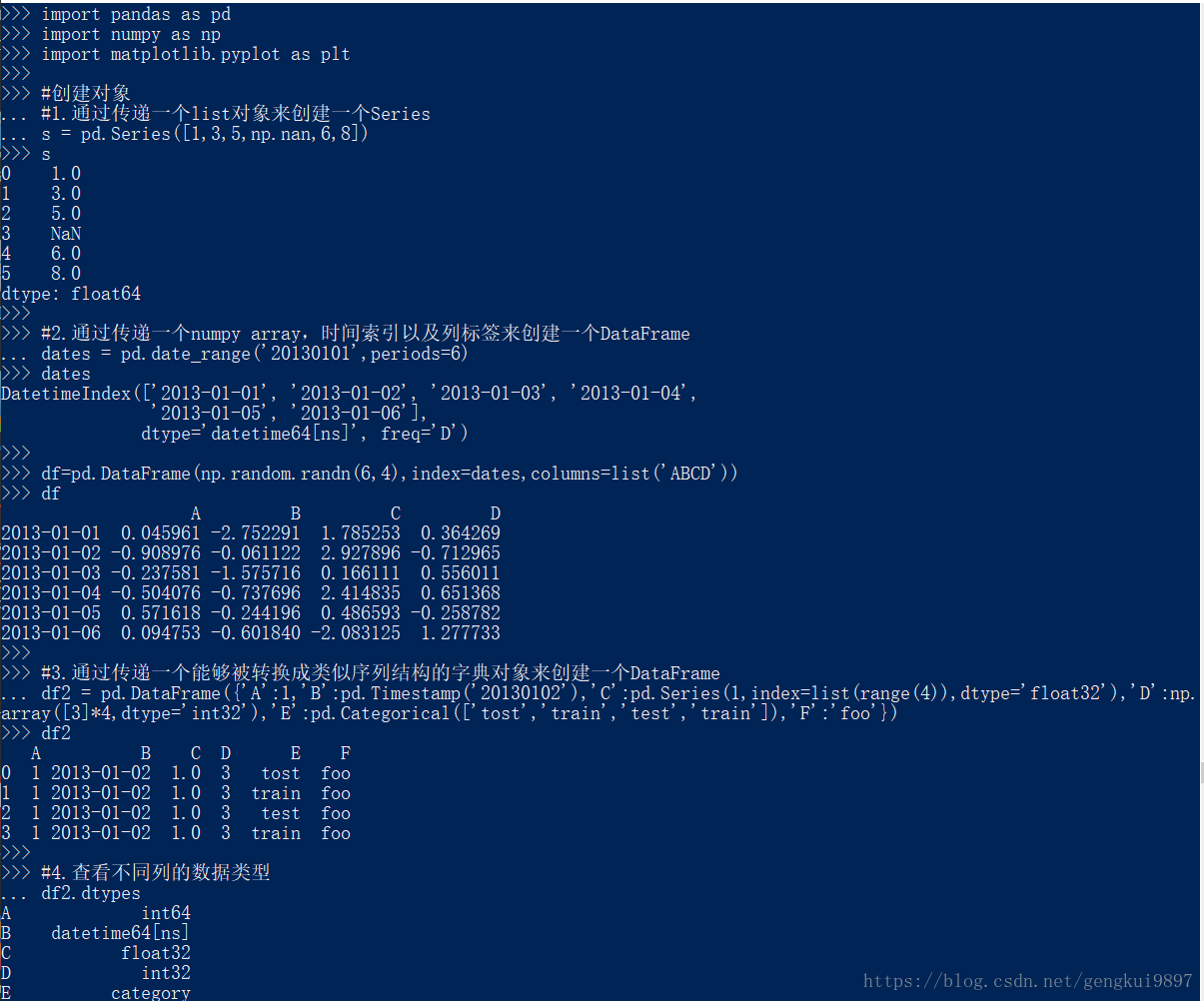
#创建对象
#1.通过传递一个list对象来创建一个Series
s = pd.Series([1,3,5,np.nan,6,8])
s
#2.通过传递一个numpy array,时间索引以及列标签来创建一个DataFrame
dates = pd.date_range('20130101',periods=6)
dates
df=pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD'))
df
#3.通过传递一个能够被转换成类似序列结构的字典对象来创建一个DataFrame
df2 = pd.DataFrame({'A':1,'B':pd.Timestamp('20130102'),'C':pd.Series(1,index=list(range(4)),dtype='float32'),'D':np.array([3]*4,dtype='int32'),'E':pd.Categorical(['tost','train','test','train']),'F':'foo'})
df2
#4.查看不同列的数据类型
df2.dtypes
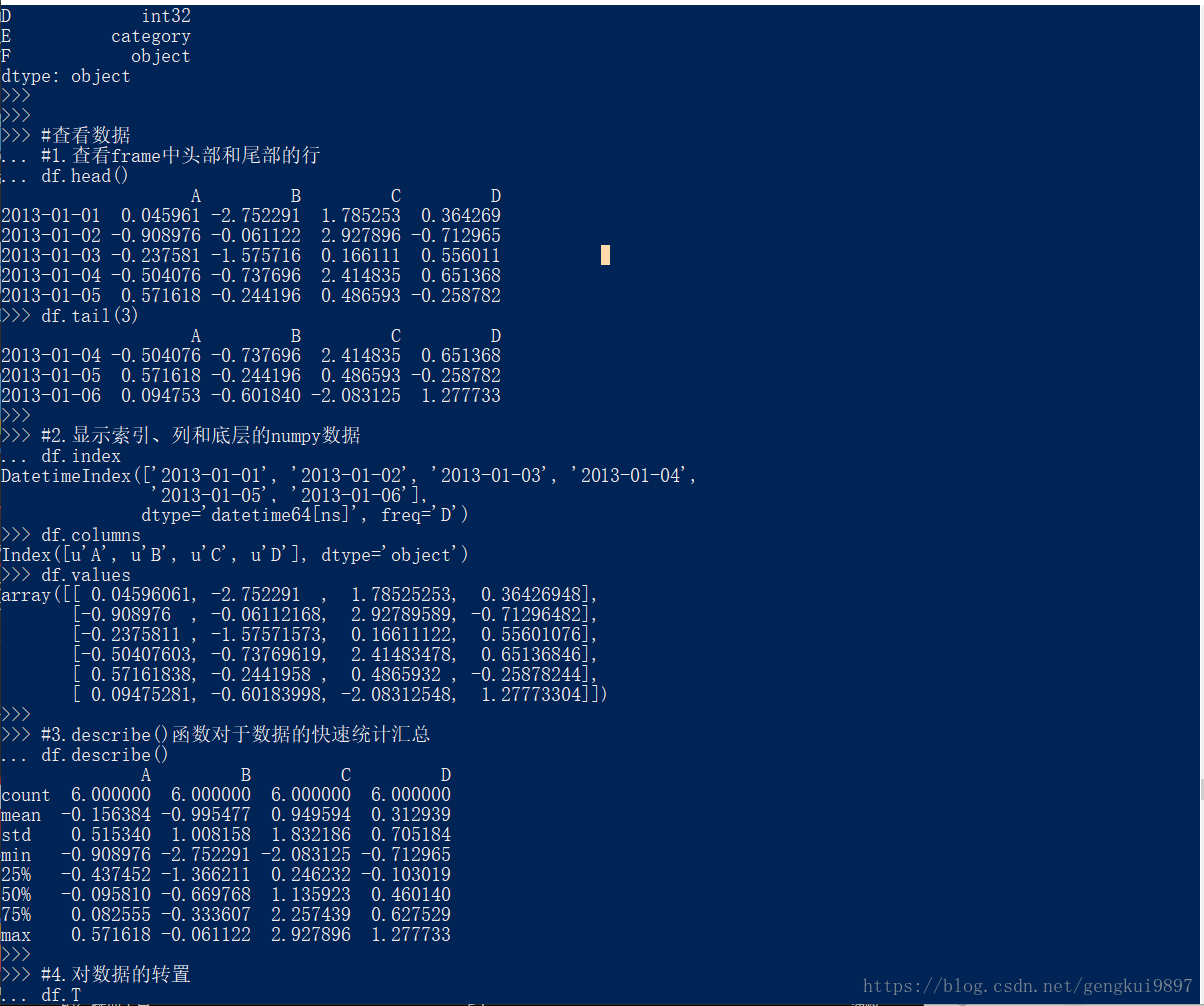
#查看数据
#1.查看frame中头部和尾部的行
df.head()
df.tail(3)
#2.显示索引、列和底层的numpy数据
df.index
df.columns
df.values
#3.describe()函数对于数据的快速统计汇总
df.describe()
#4.对数据的转置
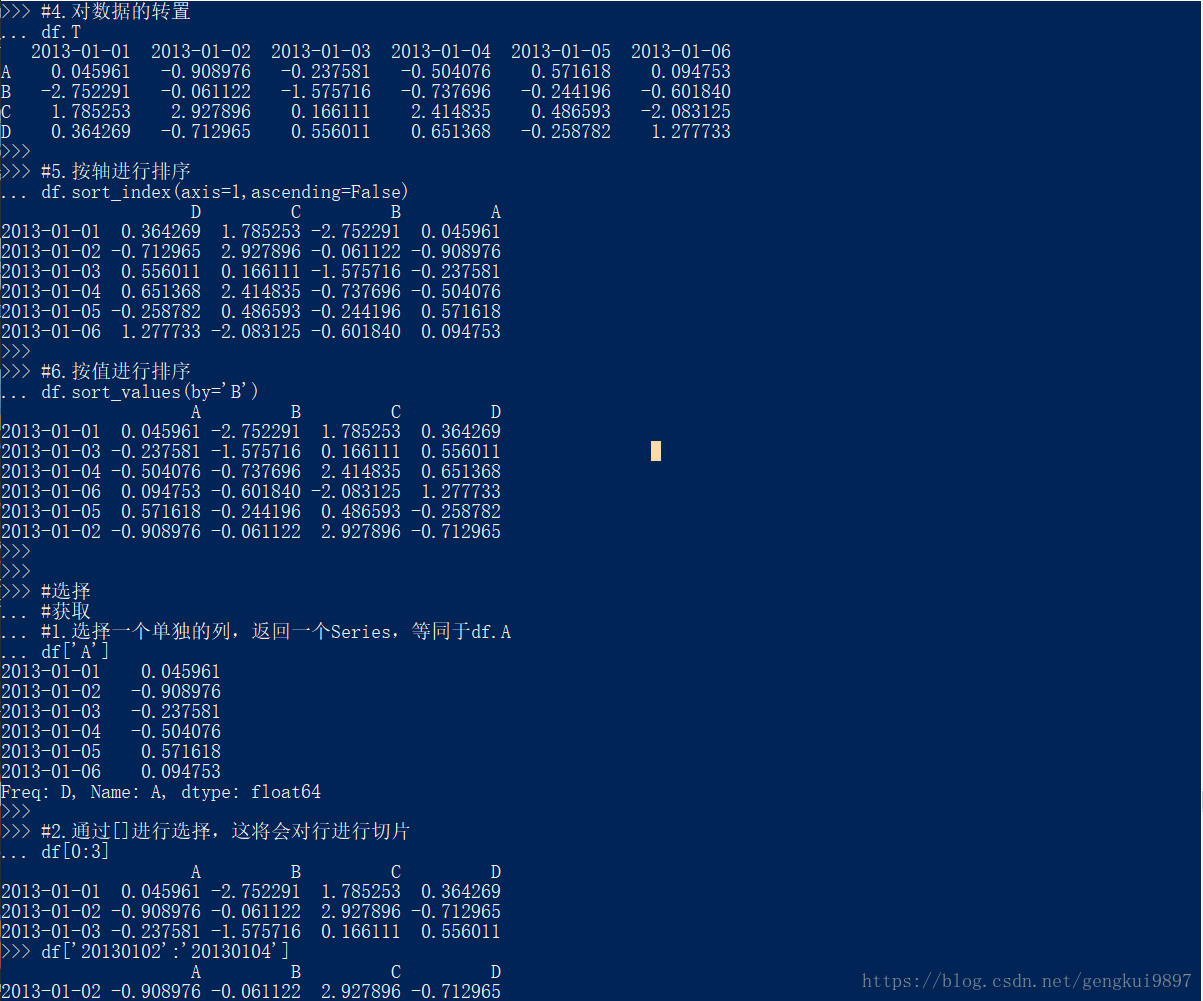
df.T
#5.按轴进行排序
df.sort_index(axis=1,ascending=False)
#6.按值进行排序
df.sort_values(by='B')
#选择
#获取
#1.选择一个单独的列,返回一个Series,等同于df.A
df['A']
#2.通过[]进行选择,这将会对行进行切片
df[0:3]
df['20130102':'20130104']
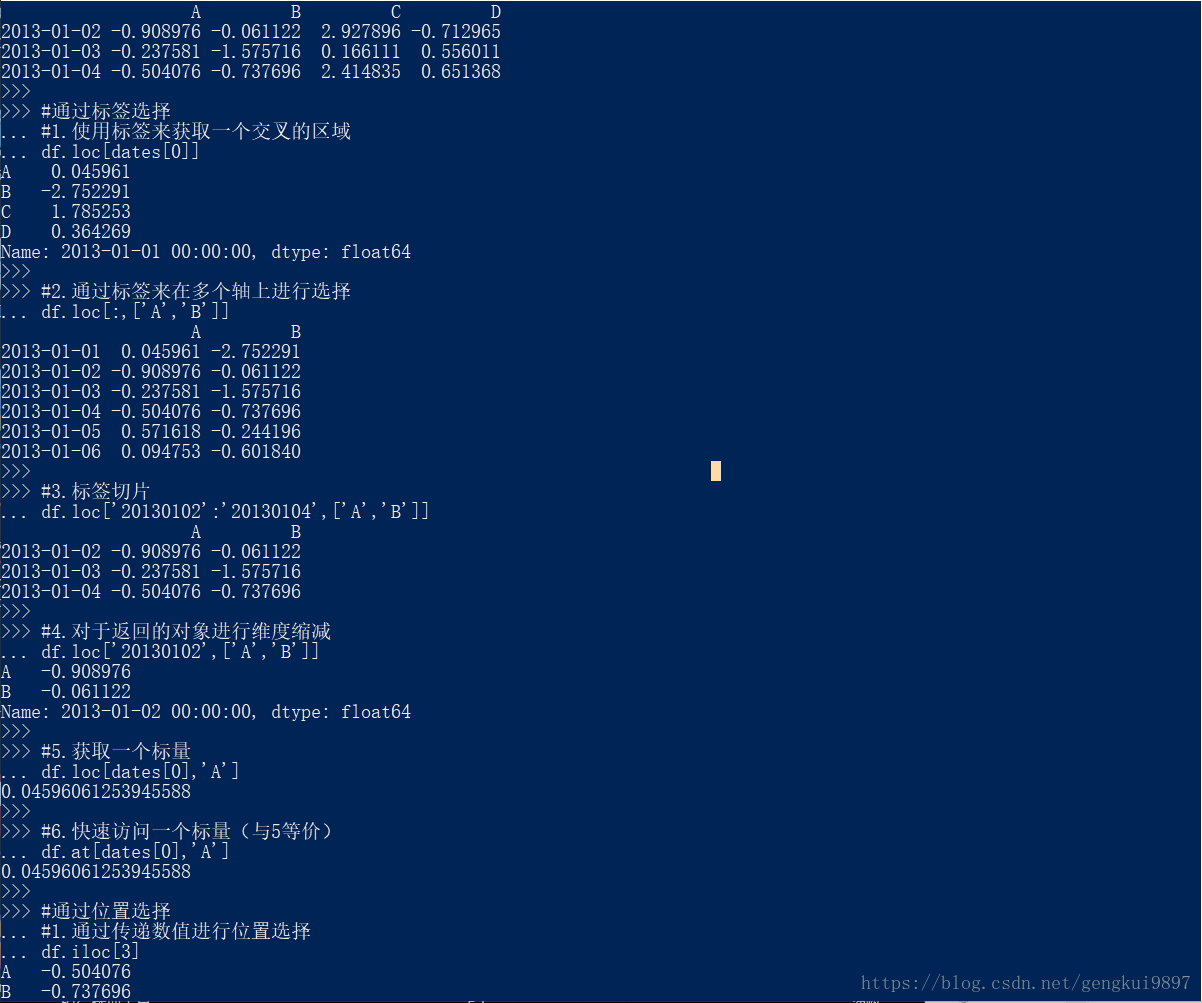
#通过标签选择
#1.使用标签来获取一个交叉的区域
df.loc[dates[0]]
#2.通过标签来在多个轴上进行选择
df.loc[:,['A','B']]
#3.标签切片
df.loc['20130102':'20130104',['A','B']]
#4.对于返回的对象进行维度缩减
df.loc['20130102',['A','B']]
#5.获取一个标量
df.loc[dates[0],'A']
#6.快速访问一个标量(与5等价)
df.at[dates[0],'A']
#通过位置选择
#1.通过传递数值进行位置选择
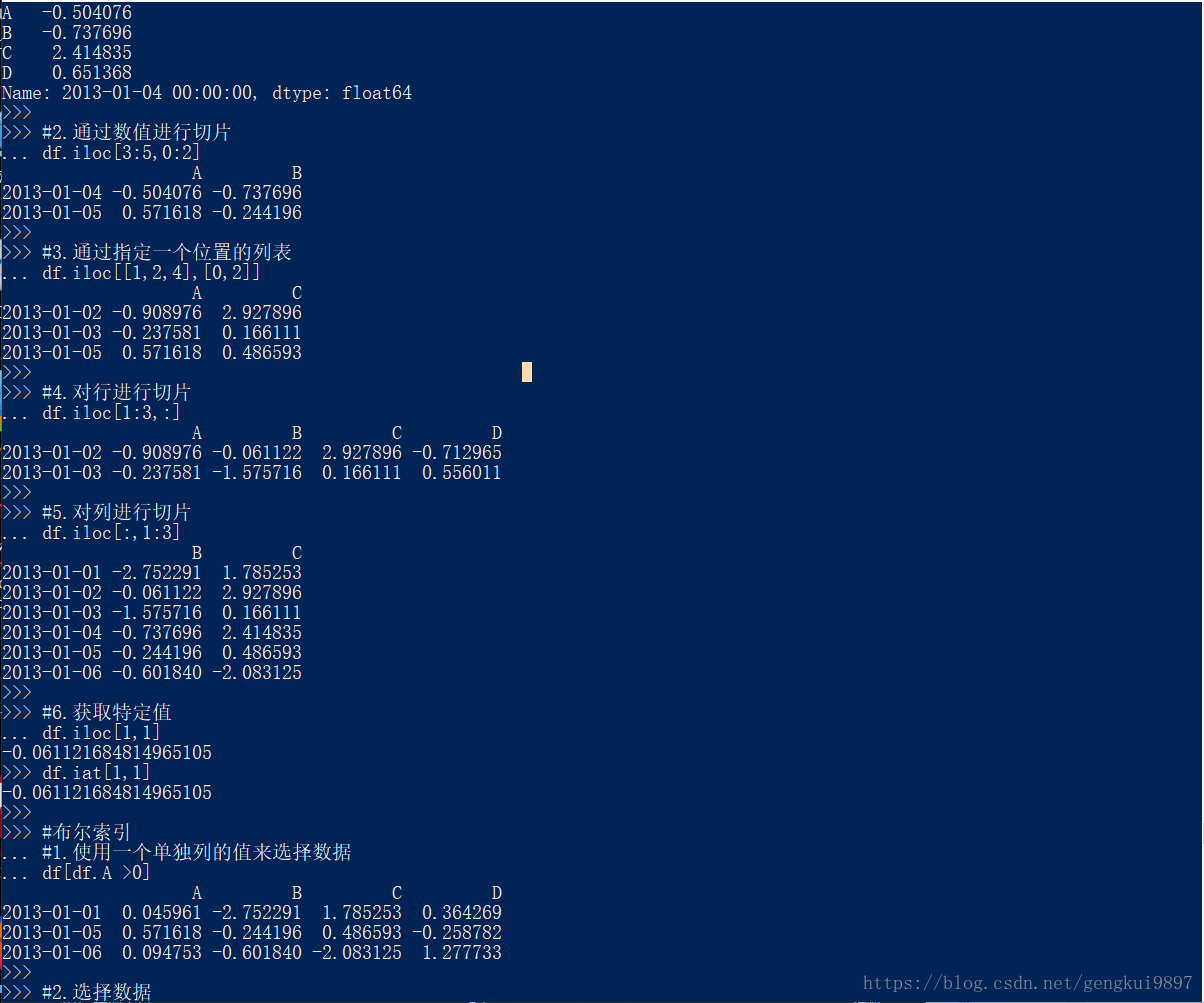
df.iloc[3]
#2.通过数值进行切片
df.iloc[3:5,0:2]
#3.通过指定一个位置的列表
df.iloc[[1,2,4],[0,2]]
#4.对行进行切片
df.iloc[1:3,:]
#5.对列进行切片
df.iloc[:,1:3]
#6.获取特定值
df.iloc[1,1]
df.iat[1,1]
#布尔索引
#1.使用一个单独列的值来选择数据
df[df.A >0]
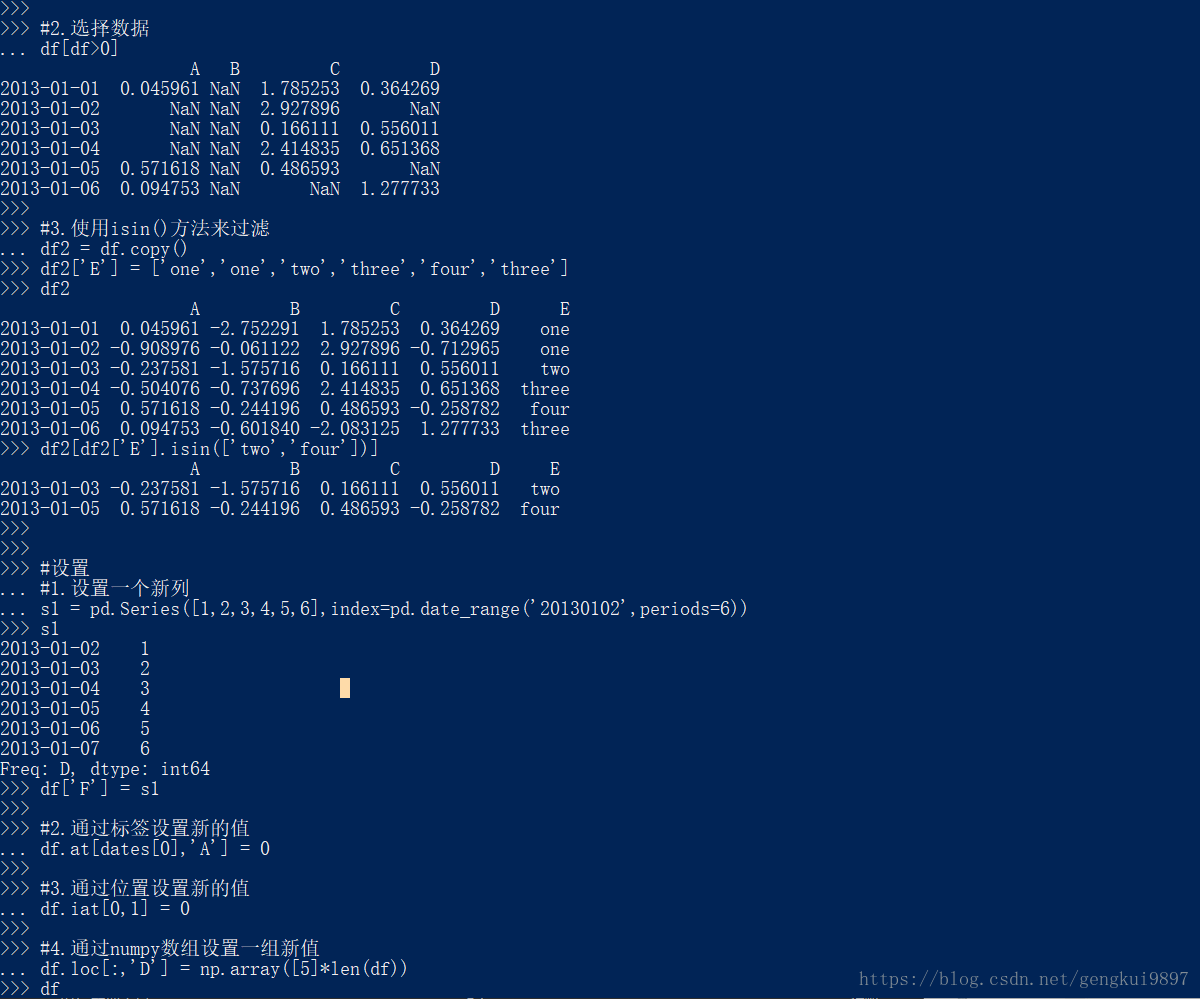
#2.选择数据
df[df>0]
#3.使用isin()方法来过滤
df2 = df.copy()
df2['E'] = ['one','one','two','three','four','three']
df2
df2[df2['E'].isin(['two','four'])]
#设置
#1.设置一个新列
s1 = pd.Series([1,2,3,4,5,6],index=pd.date_range('20130102',periods=6))
s1
df['F'] = s1
#2.通过标签设置新的值
df.at[dates[0],'A'] = 0
#3.通过位置设置新的值
df.iat[0,1] = 0
#4.通过numpy数组设置一组新值
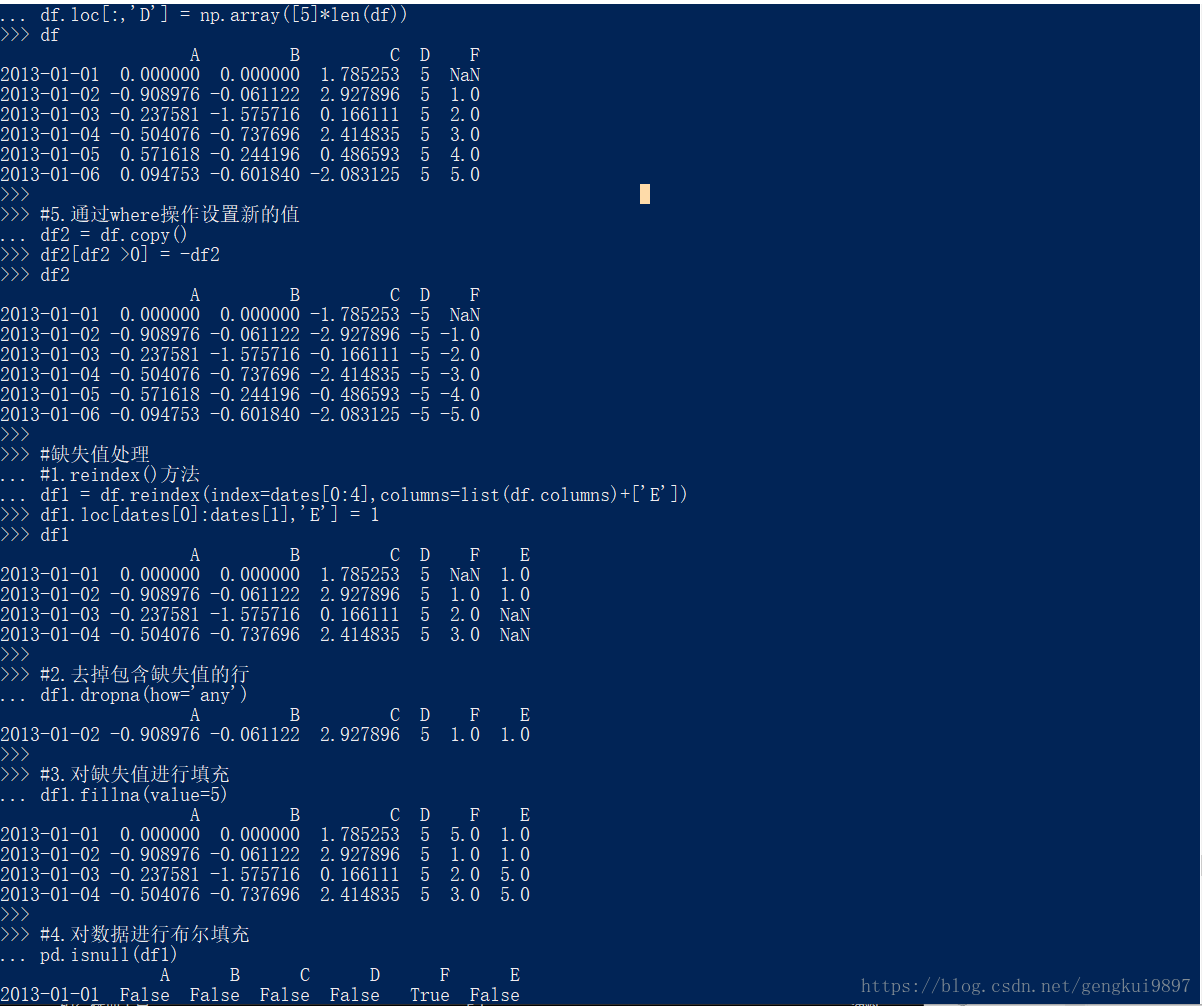
df.loc[:,'D'] = np.array([5]*len(df))
df
#5.通过where操作设置新的值
df2 = df.copy()
df2[df2 >0] = -df2
df2
#缺失值处理
#1.reindex()方法
df1 = df.reindex(index=dates[0:4],columns=list(df.columns)+['E'])
df1.loc[dates[0]:dates[1],'E'] = 1
df1
#2.去掉包含缺失值的行
df1.dropna(how='any')
#3.对缺失值进行填充
df1.fillna(value=5)
#4.对数据进行布尔填充
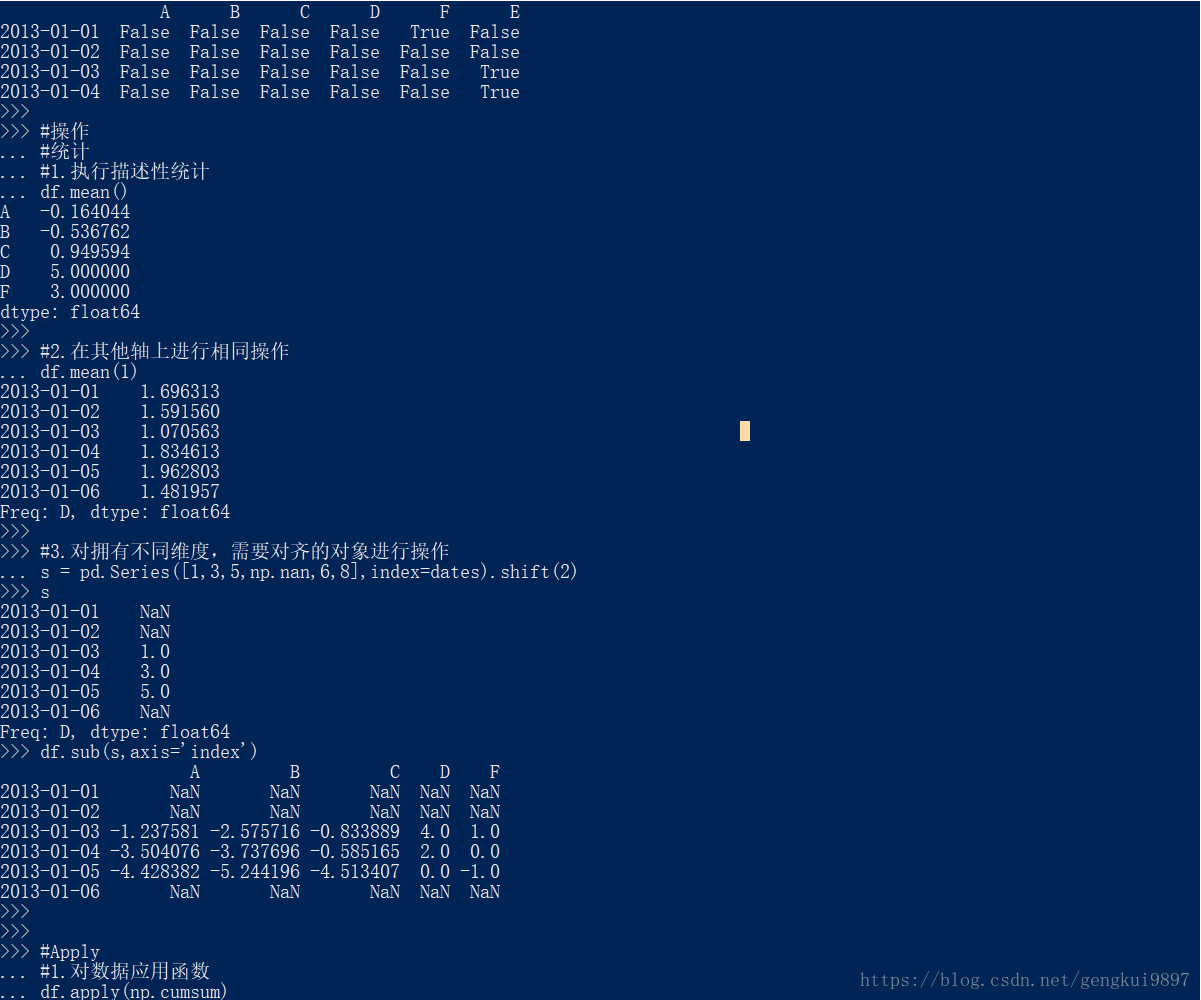
pd.isnull(df1)
#操作
#统计
#1.执行描述性统计
df.mean()
#2.在其他轴上进行相同操作
df.mean(1)
#3.对拥有不同维度,需要对齐的对象进行操作
s = pd.Series([1,3,5,np.nan,6,8],index=dates).shift(2)
s
df.sub(s,axis='index')
#Apply
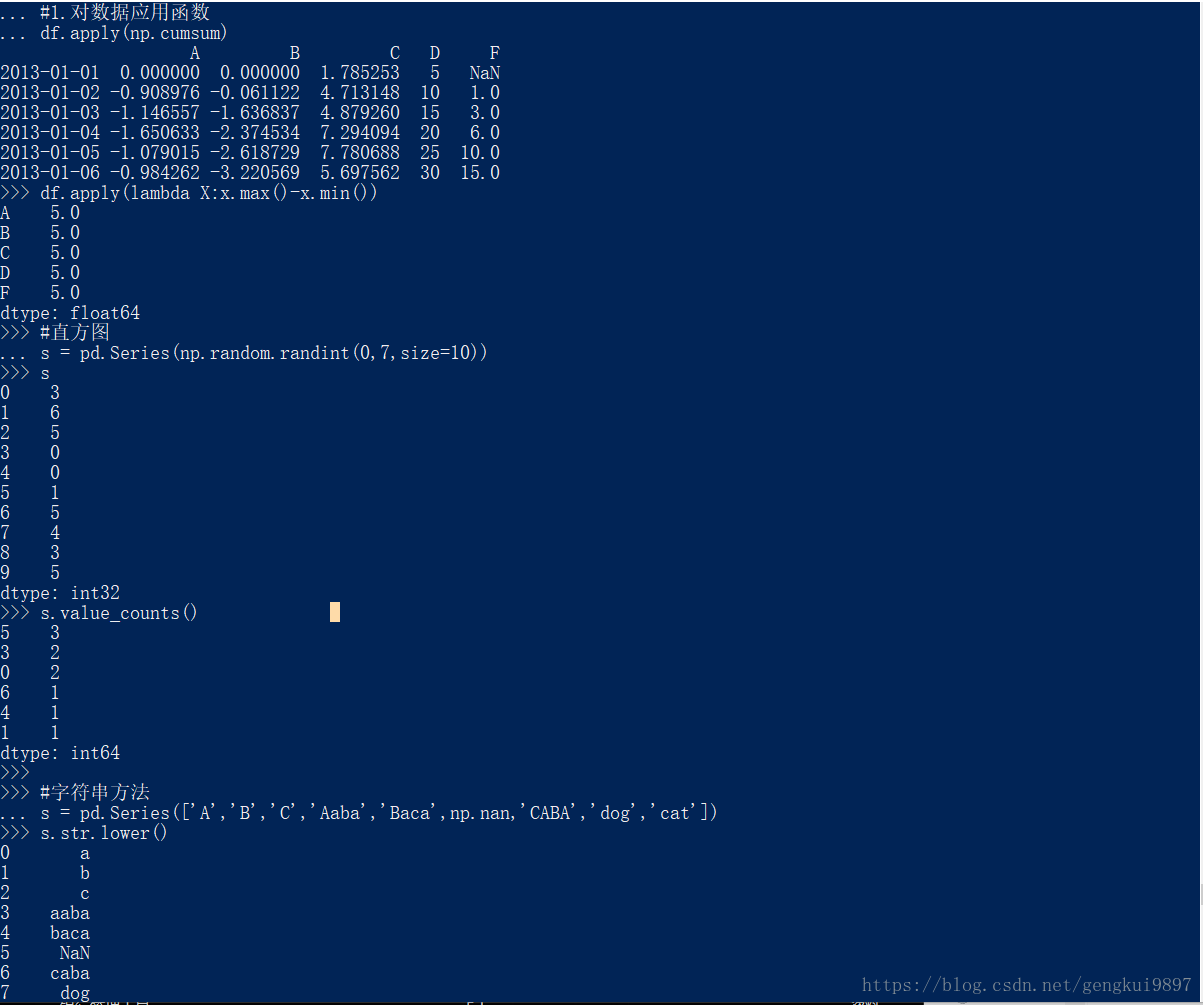
#1.对数据应用函数
df.apply(np.cumsum)
df.apply(lambda X:x.max()-x.min())
#直方图
s = pd.Series(np.random.randint(0,7,size=10))
s
s.value_counts()
#字符串方法
s = pd.Series(['A','B','C','Aaba','Baca',np.nan,'CABA','dog','cat'])
s.str.lower()
#合并
df = pd.DataFrame(np.random.randn(10,4))
df
pieces = [df[:3],df[3:7],df[7:]]
pd.concat(pieces)
#join
left = pd.DataFrame({'key':['foo','foo'],'lval':[1,2]})
right = pd.DataFrame({'key':['foo','foo'],'rval':[4,5]})
left
right
pd.merge(left,right,on='key')
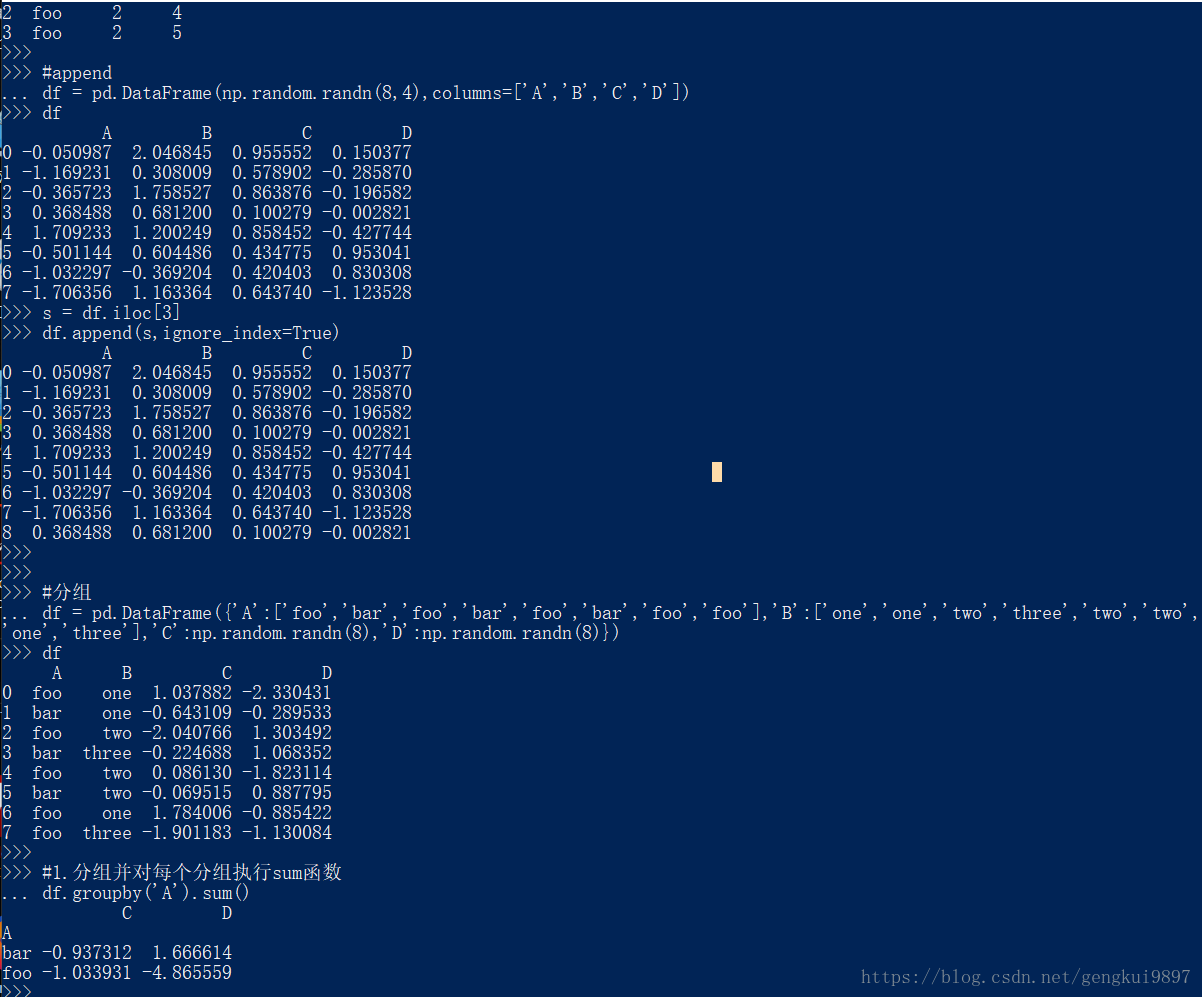
#append
df = pd.DataFrame(np.random.randn(8,4),columns=['A','B','C','D'])
df
s = df.iloc[3]
df.append(s,ignore_index=True)
#分组
df = pd.DataFrame({'A':['foo','bar','foo','bar','foo','bar','foo','foo'],'B':['one','one','two','three','two','two','one','three'],'C':np.random.randn(8),'D':np.random.randn(8)})
df
#1.分组并对每个分组执行sum函数
df.groupby('A').sum()
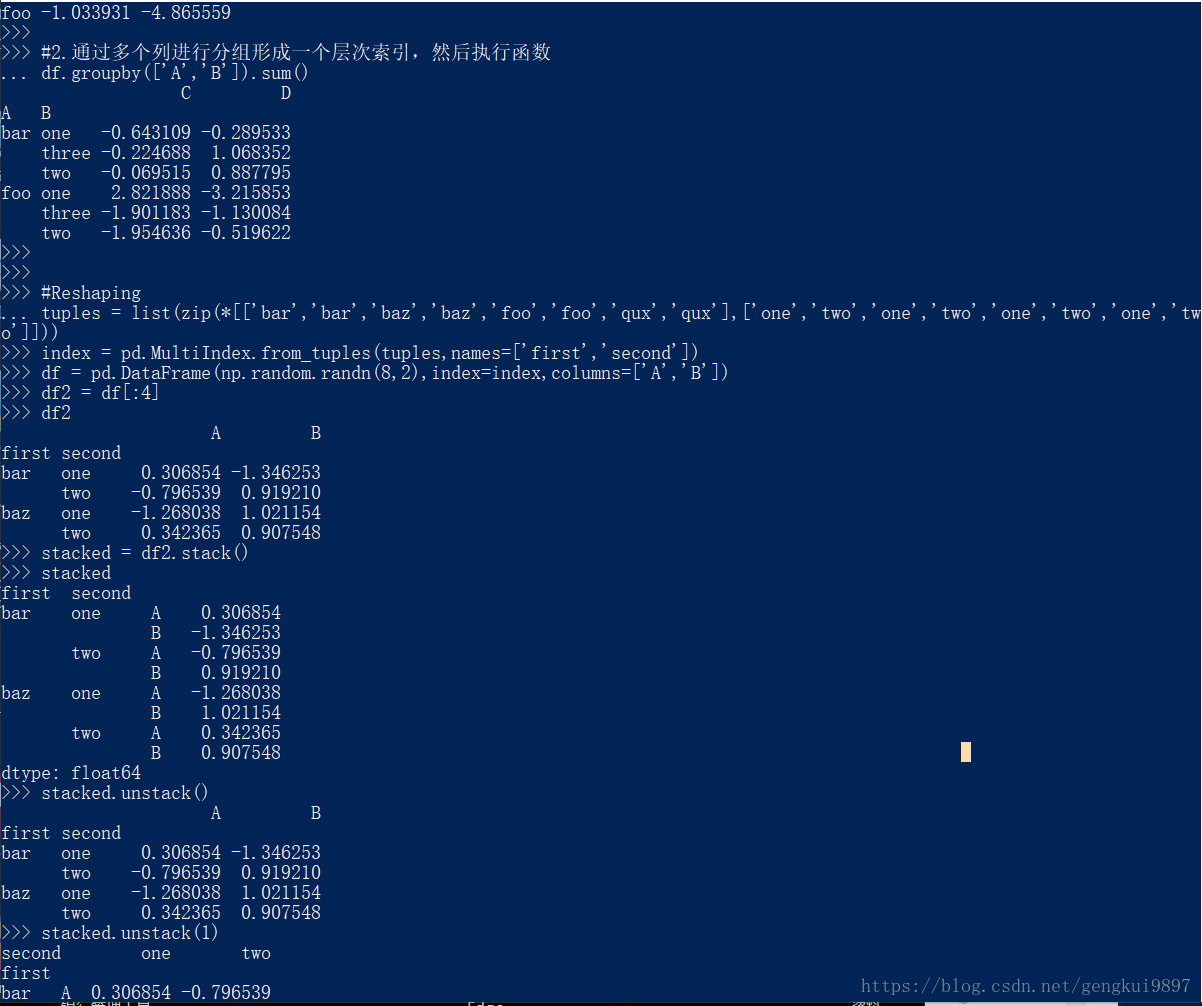
#2.通过多个列进行分组形成一个层次索引,然后执行函数
df.groupby(['A','B']).sum()
#Reshaping
tuples = list(zip(*[['bar','bar','baz','baz','foo','foo','qux','qux'],['one','two','one','two','one','two','one','two']]))
index = pd.MultiIndex.from_tuples(tuples,names=['first','second'])
df = pd.DataFrame(np.random.randn(8,2),index=index,columns=['A','B'])
df2 = df[:4]
df2
stacked = df2.stack()
stacked
stacked.unstack()
stacked.unstack(1)
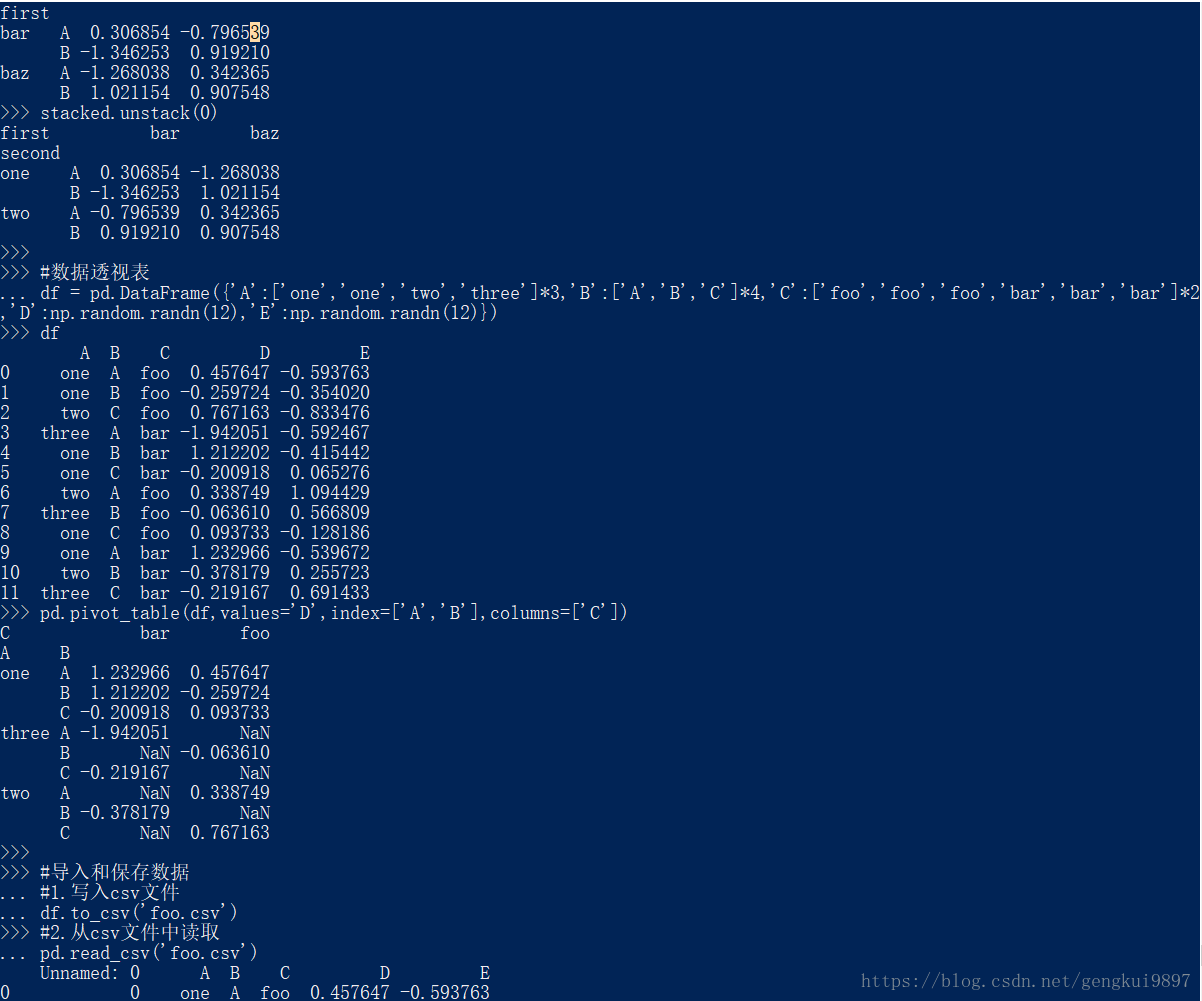
stacked.unstack(0)
#数据透视表
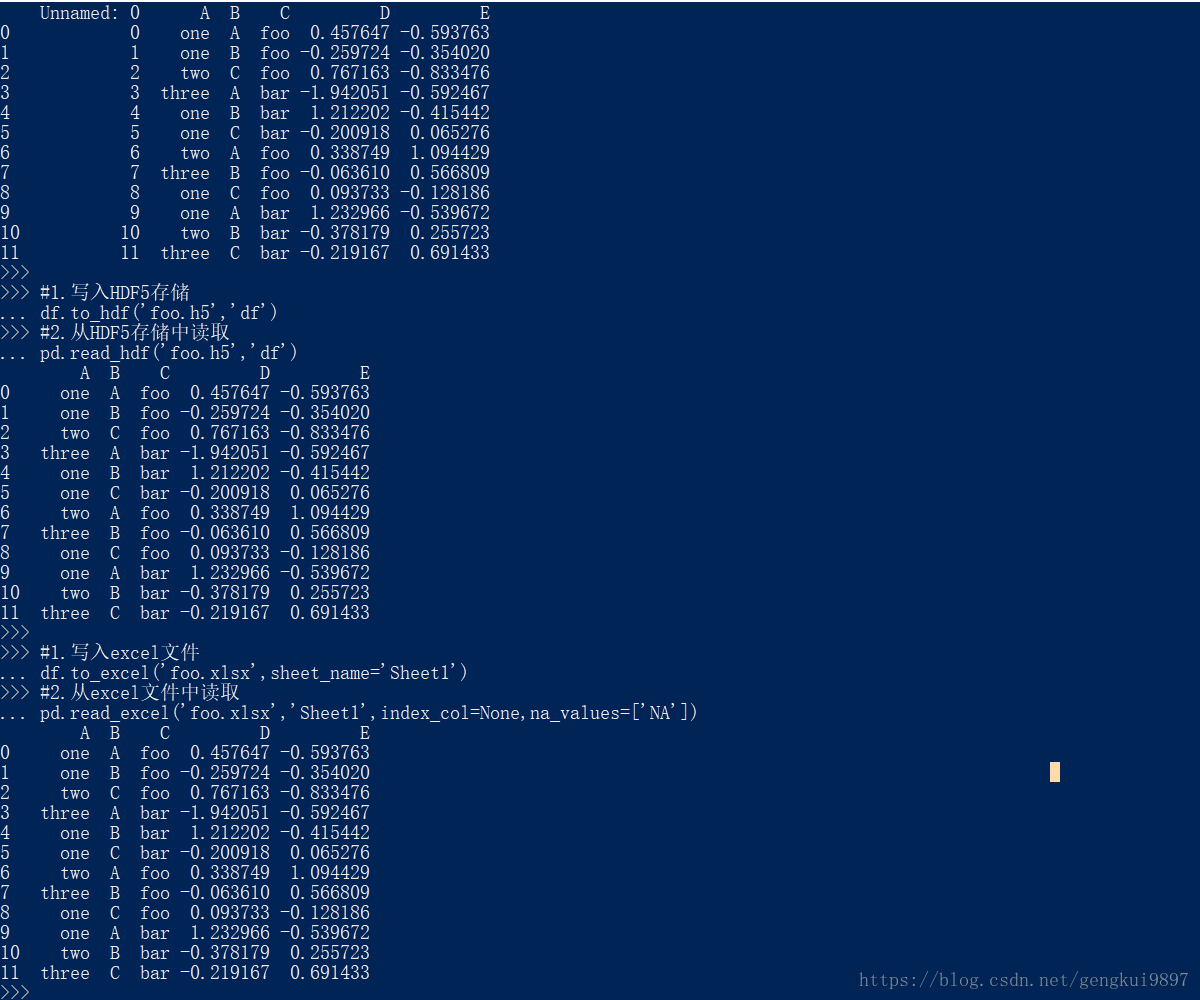
df = pd.DataFrame({'A':['one','one','two','three']*3,'B':['A','B','C']*4,'C':['foo','foo','foo','bar','bar','bar']*2,'D':np.random.randn(12),'E':np.random.randn(12)})
df
pd.pivot_table(df,values='D',index=['A','B'],columns=['C'])
#导入和保存数据
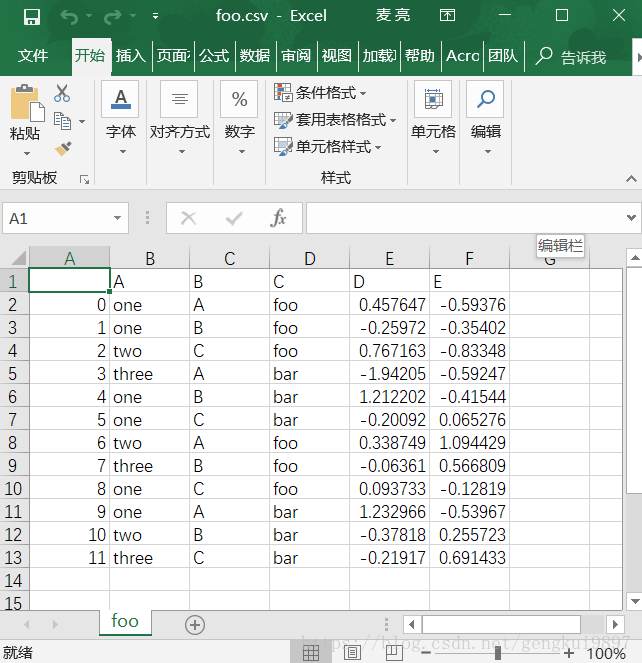
#1.写入csv文件
df.to_csv('foo.csv')
#2.从csv文件中读取
pd.read_csv('foo.csv')
#1.写入HDF5存储
df.to_hdf('foo.h5','df')
#2.从HDF5存储中读取
pd.read_hdf('foo.h5','df')
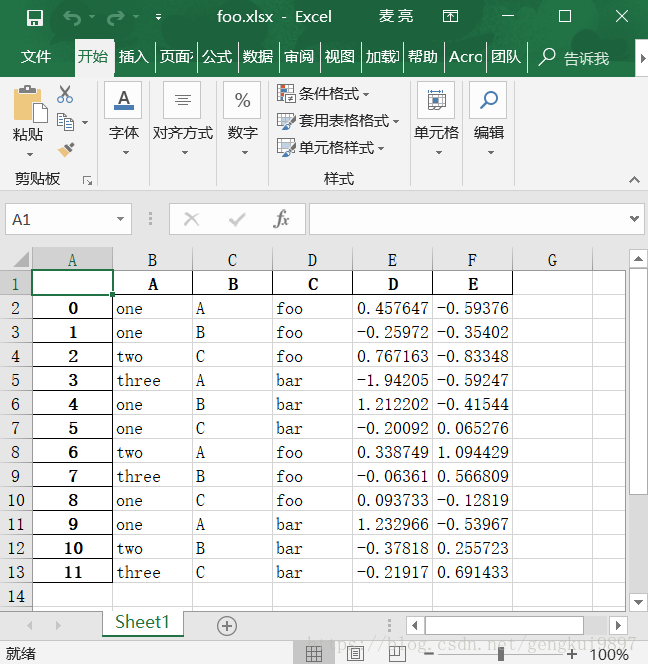
#1.写入excel文件
df.to_excel('foo.xlsx',sheet_name='Sheet1')
#2.从excel文件中读取
pd.read_excel('foo.xlsx','Sheet1',index_col=None,na_values=['NA'])