什么是numPy?用下面的图来解释一下:

如果一群人的特征(如:年龄,性别,爱好等)构成了一个数据表,这个数据表是M * N的样式,这就好比是一个M * N的矩阵。我们知道,矩阵的运算是很简单的。把一些数据表示成矩阵的样式对于计算机来说是很简单的。并且效率也非常高。而numPy就是专门用来做矩阵运算的。当然不光是矩阵运算,还有其它的操作。
下面一 一举例说明…
文件读取:
下面看一串代码:
import numpy as np
#读取文件中的数据
txt=np.genfromtxt("Car Evaluation.csv",delimiter=",",dtype=str)
print(type(txt))
print(txt)
输出的结果:

可以看到,detail.txt中的数据确实被读取出来了,以矩阵的形式返回。
如果不知道某个函数的用法,可以使用print(help(np.genfromtxt))语句查看。帮助中也提供了np.genfromtxt函数具体的例子:

矩阵定义:
代码:
#----------------矩阵定义-----------------------
mat1=np.array([[1,2],[3,3],[1,2]])
mat2=np.array([[1,3]])
print("mat1:\n",mat1)
print("mat2:\n",mat2)
print("mat1维度:\n",mat1.shape)
print("mat2维度:\n",mat2.shape)
运行结果:

用np.array()就可以定义一个矩阵。x.shape就表示x的维度,Python3中可以用mat1.shape显示mat1矩阵的维度,结果是(3,2),表示mat1是一个3*2的矩阵。
注意:np.array([x,y,z])中的x,y,z必须是相同的结构。 如果有3个int型元素,一个float型元素。那么3个int型元素都会变成float型元素。如下所示:
data=np.array([1,2,3,4])
print(data.dtype)
结果显示为: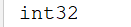
那结果变成这样:
data=np.array([1,2,3,4.0])
print(data.dtype)
那结果变成这样: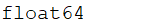
所以说,np.array([x,y,z])中的x,y,z必须是相同的结构,这是一个潜在的规则。
取值:
如果有一堆数组,我想从里面去除某一个数字,那么用下面的代码就可以实现:
#找出txt文本的维度,寻找第1728行第6列的值,因为矩阵是从(0,0)开始的相当于从坐标原点开始,所以代码使用cut_data=txt[1727,5]
print(txt.shape)
cut_data=txt[1727,5]
print("第1728行第6列的值是:",cut_data)
输出结果:

切片:
Python中可以直接对List数组进行切片,在numPy中也可以。
vector1=np.array([1,2,3,4])
print(vector1[:3])
print("-----------")
vector2=np.array([[1,2,3],
[4,5,6],
[7,8,9]])
print(vector2[:,0:2]) #取所有行,第0-1列
print("-----------")
print(vector2[1:3,0:2])
运行结果:

判断:
在numPy中,可以直接对List数组或矩阵进行元素判断,而不需要直接使用for循环去遍历查找。
data1=np.array([1,2,3,4,5])
data2=np.array([[10,20,30],
[40,50,60],
[70,80,90]])
print("判断data1中是否包含10:\n",data1==10)
print("判断data1中是否包含5:\n",data1==5)
print("判断data2中是否包含20:\n",data2==20)
运行结果:

可以看到,当被查找的元素存在时,会返回True这个布尔类型,否则返回False。
当然,这个bool类型也可以当成一个索引。
#bool类型也可以当成索引
data1=np.array([1,2,3,4,5])
a=(data1==5)
print(data1[a])
运行结果:
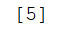
当我输入的为:a=(data1==6) print(data1[a])时,结果返回为空,因为用该索引查找不到对应的元素。
运行结果:
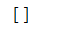
对于二维矩阵也是一样的:
data1=np.array([1,2,3,4,5])
data2=np.array([[10,20,30],
[40,50,60],
[70,80,90]])
print("判断data1中是否包含10:\n",data1==10)
print("判断data1中是否包含5:\n",data1==5)
print("判断data2中是否包含20:\n",data2==20)
#bool类型也可以当成索引
#在矩阵第二列找出对应元素
a=(data2[:,1]==50)
#用索引在该行找出所在的行
print(data2[a,:])
运行结果:
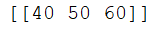
除了单个元素查找,还能多个元素查找。那么查找的结果是怎么样的呢?
data1=np.array([1,2,3,4,5])
data2=np.array([[10,20,30],
[40,50,60],
[70,80,90]])
equal10_15=(data2==10)&(data2==15)#与操作,同时满足这两个条件
print(equal10_15)
输出结果:
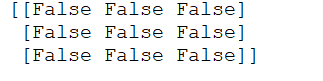
可以看到,并没有一个同时满足既是10又是15的元素。
换一下或操作:
data1=np.array([1,2,3,4,5])
data2=np.array([[10,20,30],
[40,50,60],
[70,80,90]])
equal10_15=(data2==10)|(data2==20)
print(equal10_15)
运行结果:

可以看到,找到了同时满足既是10又是20的元素。
数据类型转换
有一个数组为[‘1’,‘2’,‘3’,‘4’],现在想要将它转换成float类型的,就进行如下操作:
list=np.array(['1','2','3','4'])
print("list的数据类型是:\n",list.dtype)
print(list)
list_as=list.astype(float) #astype()是一个类型转换函数
print("list_as的数据类型是:\n",list_as.dtype)
print(list_as)
运行结果:

求最小最大值
numPy中也可以求矩阵中的最小和最大值:
Mat_data=np.array([[10,20,30],
[40,50,60],
[70,80,90]])
min_mat=Mat_data.min() #内置函数
max_mat=Mat_data.max()
print("矩阵中最小元素:\n",min_mat)
print("矩阵中最大元素:\n",max_mat)
# print(help(np.array))
运行结果:

行列求和
numPy还可以对矩阵的每行和每列分别求和:
Mat_data=np.array([[10,20,30],
[40,50,60],
[70,80,90]])
add1=Mat_data.sum(axis=1) #axis=1,矩阵每行进行求和
print("矩阵每行进行求和:\n",add1)
add2=Mat_data.sum(axis=0) #axis=0,矩阵每列进行求和
print("矩阵每列进行求和:\n",add2)
运行结果:

函数计算
numPy中还可以对矩阵各元素进行函数操作。
x=np.arange(3)
print(x)
print(np.exp(x))#e的n次方
print(np.sqrt(x))#开根号
运行结果:

矩阵变向量
把M*N的矩阵通过函数变成一个单行向量,也可以把单行向量变成二维矩阵。
a=np.array([[1,2,3],#2*3矩阵
[2,3,4]])
b=a.ravel()#变成一行的向量
print(b)
c=b.reshape(3,2)#变成3*2的矩阵,reshape(3,-1)自动计算每行有几个
print(c)
print(c.T) #求转置矩阵,行列互换
运行结果:

矩阵拼接
把两个或多个矩阵按行或按列进行拼接起来。
a=np.array([[1,2],#2*3矩阵
[2,3]])
b=np.array([[2,1],#2*3矩阵
[0,0]])
c=np.vstack((a,b)) #竖着拼接
d=np.hstack((a,b)) #横着拼接
print(c)
print("-----------------")
print(d)
运行结果:

矩阵拆分
a=np.floor(10*np.random.random((2,12))) #向下取整定义一个2*12的随机矩阵
print(a)
print("--------------------------")
print(np.hsplit(a,3)) #竖着切
print("--------------------------")
print(np.vsplit(a,2)) #横着切
运行结果:

复制
a=np.arange(8)
print(a)
b=a
b.shape=(2,4) #改变b的维度
print("b.shape:\n",b.shape)
print("a.shape:\n",a.shape)
print("id(a):",id(a))
print("id(b):",id(b))
运行结果:

也就是说,改变了b的维度,a也会发生变化。再看id,两个id的值都是一样的。所以说,a与b只是名字上的不同,就像别人叫你绰号一样,你还是你。
浅复制
a=np.arange(8)
c=a.view() #浅复制
c.shape=(4,2)
print("c.shape:\n",c.shape)
print("a.shape:\n",a.shape)
c[0,0]=100
print("c:",c)
print("a:",a)
运行结果:

可以看到,通过view()复制之后的c,改变维度,但是a的维度依然不会变。但是,改变c中某一元素的值,a中的值却变了。并且两个矩阵的id也不同。所以说,虽然两个矩阵没有什么共同联系,但是却共用着同一组数据。
分离复制
这个意思就是说复制出来的矩阵完全是独立的,你是你,他是他。
d=a.copy()
d.shape=(3,4)
a.shape=(4,3)
d[0,0]=999
print("d.shape:\n",d.shape)
print("a.shape:\n",a.shape)
print("d:",d)
print("a:",a)
print("id(d):",id(d))
print("id(a):",id(a))
运行结果:

最值
我们也可以查找矩阵中每一行或每一列的最大值或最小值。
a=np.array([[1,5],
[3,4],
[1,2]])
b=a.argmax(axis=0) #取每一列的最大值,这里输出的是索引
print("索引值:\n",b)
print("每列最大值:\n",a[b,range(a.shape[1])]) #打印输出的最值
运行结果:

矩阵扩展
a=np.arange(0,30,10) #0-30,步长为10的行向量
b=np.tile(a,(2,2)) #将a扩展成2*2的矩阵,行列均变成原来的2倍
c=np.tile(a,(3,5)) #将a扩展成3*5的矩阵,行变成原来的3倍,列变成原来的5倍
print("a:\n",a)
print("b:\n",b)
print("c:\n",c)
运行结果:

排序
numPy也能对矩阵中的元素按行或列进行排序。
a=np.array([[2,3,1],
[4,0,2]])
b=np.sort(a,axis=1) #按列进行排序
print("按列进行排序(b):\n",b)
c=np.array([3,2,4,0])
c_arg=np.argsort(c) #默认降序排序
print("降序索引:\n",c_arg)
print("降序排序:\n",c[c_arg])
运行结果:

这里放下本章所讲的所有源码:
(需要哪章将注释去掉即可)
import numpy as np
#-----------读取文件中的数据-------------
# txt=np.genfromtxt("Car Evaluation.csv",delimiter=",",dtype=str)
#
# print(type(txt))
# print(txt)
# print(help(np.genfromtxt))
#----------------矩阵定义-----------------------
# mat1=np.array([[1,2],[3,3],[1,2]])
# mat2=np.array([[1,3]])
# print("mat1:\n",mat1)
# print("mat2:\n",mat2)
# print("mat1维度:\n",mat1.shape)
# print("mat2维度:\n",mat2.shape)
#---------------取值----------------------------
#找出txt文本的维度,寻找第1728行第6列的值,因为矩阵是从(0,0)开始的相当于从坐标原点开始,所以代码使用cut_data=txt[1727,5]
# print(txt.shape)
# cut_data=txt[1727,5]
# print("第1728行第6列的值是:",cut_data)
#----------------切片-----------------------------
#[0:2]这是一个左闭右开的范围
# vector1=np.array([1,2,3,4])
# print(vector1[:3])
# print("-----------")
# vector2=np.array([[1,2,3],
# [4,5,6],
# [7,8,9]])
# print(vector2[:,0:2]) #取所有行,第0-1列
# print("-----------")
# print(vector2[1:3,0:2])
#--------------------判断----------------------------
#
# data1=np.array([1,2,3,4,5])
# data2=np.array([[10,20,30],
# [40,50,60],
# [70,80,90]])
# print("判断data1中是否包含10:\n",data1==10)
# print("判断data1中是否包含5:\n",data1==5)
# print("判断data2中是否包含20:\n",data2==20)
# #bool类型也可以当成索引
# #在矩阵第二列找出对应元素
# a=(data2[:,1]==50)
# #用索引在该行找出所在的行
# print(data2[a,:])
# #与-或判断
# equal10_15=(data2==10)|(data2==20)
# print(equal10_15)
#------------------数据类型转换-------------------------
# list=np.array(['1','2','3','4'])
# print("list的数据类型是:\n",list.dtype)
# print(list)
#
# list_as=list.astype(float) #astype()是一个类型转换函数
# print("list_as的数据类型是:\n",list_as.dtype)
# print(list_as)
#----------------求最小最大值-------------------------
# Mat_data=np.array([[10,20,30],
# [40,50,60],
# [70,80,90]])
# min_mat=Mat_data.min() #内置函数
# max_mat=Mat_data.max()
# print("矩阵中最小元素:\n",min_mat)
# print("矩阵中最大元素:\n",max_mat)
# # print(help(np.array))
#--------------行列求和-----------------------------
# Mat_data=np.array([[10,20,30],
# [40,50,60],
# [70,80,90]])
#
# add1=Mat_data.sum(axis=1) #axis=1,矩阵每行进行求和
# print("矩阵每行进行求和:\n",add1)
# add2=Mat_data.sum(axis=0) #axis=0,矩阵每列进行求和
# print("矩阵每列进行求和:\n",add2)
#---------------函数计算--------------------------
# x=np.arange(3)
# print(x)
# print(np.exp(x))#e的n次方
# print(np.sqrt(x))#开根号
#--------------------矩阵变向量操作-----------------
# a=np.array([[1,2,3],#2*3矩阵
# [2,3,4]])
# b=a.ravel()#变成一行的向量
# print(b)
# c=b.reshape(3,2)#变成3*2的矩阵,reshape(3,-1)自动计算每行有几个
# print(c)
# print(c.T) #求转置矩阵,行列互换
#--------------------矩阵拼接操作-----------------
# a=np.array([[1,2],#2*3矩阵
# [2,3]])
# b=np.array([[2,1],#2*3矩阵
# [0,0]])
# c=np.vstack((a,b)) #竖着拼接
# d=np.hstack((a,b)) #横着拼接
# print(c)
# print("-----------------")
# print(d)
#------------------矩阵拆分-----------------------
# a=np.floor(10*np.random.random((2,12))) #向下取整定义一个2*12的随机矩阵
# print(a)
# print("--------------------------")
# print(np.hsplit(a,3)) #竖着切
# print("--------------------------")
# print(np.vsplit(a,2)) #横着切
#--------------------复制-------------------------
# a=np.arange(12)
# # print(a)
# # b=a
# # b.shape=(2,4) #改变b的维度
# # print("b.shape:\n",b.shape)
# # print("a.shape:\n",a.shape)
# # print("id(a):",id(a))
# # print("id(b):",id(b))
# #
#---------------------浅复制--------------------
# a=np.arange(8)
# # c=a.view()
# # c.shape=(4,2)
# # print("c.shape:\n",c.shape)
# # print("a.shape:\n",a.shape)
# # c[0,0]=100
# # print("c:",c)
# # print("a:",a)
# # print("id(c):",id(c))
# # print("id(a):",id(a))
#------------------分离复制---------------------
# a=np.arange(12)
# d=a.copy()
# d.shape=(3,4)
# a.shape=(4,3)
# d[0,0]=999
# print("d.shape:\n",d.shape)
# print("a.shape:\n",a.shape)
# print("d:",d)
# print("a:",a)
# print("id(d):",id(d))
# print("id(a):",id(a))
#------------------取最值---------------------
# a=np.array([[1,5],
# [3,4],
# [1,2]])
# b=a.argmax(axis=0) #取每一列的最大值,这里输出的是索引
# print("索引值:\n",b)
# print("每列最大值:\n",a[b,range(a.shape[1])]) #打印输出的最值
#--------------------矩阵扩展-----------------
# a=np.arange(0,30,10) #0-30,步长为10的行向量
# b=np.tile(a,(2,2)) #将a扩展成2*2的矩阵,行列均变成原来的2倍
# c=np.tile(a,(3,5)) #将a扩展成3*5的矩阵,行变成原来的3倍,列变成原来的5倍
# print("a:\n",a)
# print("b:\n",b)
# print("c:\n",c)
#----------------------排序-----------------------
# a=np.array([[2,3,1],
# [4,0,2]])
# b=np.sort(a,axis=1) #按列进行排序
# print("按列进行排序(b):\n",b)
#
#
# c=np.array([3,2,4,0])
# c_arg=np.argsort(c) #默认降序排序
# print("降序索引:\n",c_arg)
# print("降序排序:\n",c[c_arg])