ps: 欢迎大家光临我的博客
建立数据集
标注工具:
sudo apt-get install pyqt5-dev-tools
sudo pip3 install lxml
git clone https://github.com/tzutalin/labelImg.git
cd labelImg
make qt5py3
python3 labelImg.py
执行完上面的命令会打开如下的软件界面说明正常被安装
 W键用来选择图像标注的位置
W键用来选择图像标注的位置
这里我采用的是百变小樱的小樱来作为我们的识别对象:

就像这样来标注。标注成功后,每个图片会生成一个对应的xml文件。大致结构如下:
<annotation>
<folder>picdata</folder>
<filename>1.jpg</filename>
<path>/home/daniel/Depth_Learning/tensorflow object detection API/picdata/1.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>190</width>
<height>118</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>xiaoying</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>87</xmin>
<ymin>11</ymin>
<xmax>124</xmax>
<ymax>48</ymax>
</bndbox>
</object>
</annotation>
主要的内容就是说明文件的位置 文件的高度和宽度,或者深度 然后标注的内容,这里是xiaoying
然后就是我们选择框的xmin xmax ymin ymax
xml转csv
然后我们把这些xml转换成csv文件:代码如下:
# -*- coding: utf-8 -*-
import os
import glob
import pandas as pd
import xml.etree.ElementTree as ET
os.chdir('/home/daniel/Depth_Learning/tensorflow object detection API/picdata/test') # 这个是我文件夹的目录,改成你自己的
path = '/home/daniel/Depth_Learning/tensorflow object detection API/picdata/test' # 训练图片的路径,改成你自己的
def xml_to_csv(path):
xml_list = []
for xml_file in glob.glob(path + '/*.xml'):
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall('object'):
value = (root.find('filename').text,
int(root.find('size')[0].text),
int(root.find('size')[1].text),
member[0].text,
int(member[4][0].text),
int(member[4][1].text),
int(member[4][2].text),
int(member[4][3].text)
)
xml_list.append(value)
column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax']
xml_df = pd.DataFrame(xml_list, columns=column_name)
return xml_df
def main():
image_path = path
xml_df = xml_to_csv(image_path)
xml_df.to_csv('xiaoying_test.csv', index=None) # 输出xsv文件的名字,改成你自己的
print('Successfully converted xml to csv.')
main()
这里提取xml文件中 filename 图片的宽 图片的高 标注的名字 标注框相对于图像的位置
将这几个变量转换成csv文件。
我们把标注的文件分为两部分 一部分作为训练集train ,一部分作为测试集test 然后将两个文件夹中的xml转化成csv文件,生成的csv文件也分别放在train和test文件夹中
文件目录如下:
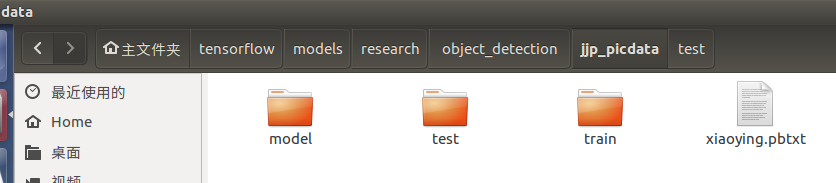
csv转tfrecord
# -*- coding: utf-8 -*-
"""
Usage:
# From tensorflow/models/
# Create train data:
python jjp_csv_to_tfrecord.py --csv_input=data/tv_vehicle_labels.csv --output_path=train.record
# Create test data:
python jjp_csv_to_tfrecord.py --csv_input=data/test_labels.csv --output_path=test.record
"""
import os
import io
import pandas as pd
import tensorflow as tf
from PIL import Image
from object_detection.utils import dataset_util
from collections import namedtuple, OrderedDict
os.chdir('/home/daniel/tensorflow/models/research/object_detection') # 当前工作目录
flags = tf.app.flags
flags.DEFINE_string('csv_input', '', 'Path to the CSV input')
flags.DEFINE_string('output_path', '', 'Path to output TFRecord')
FLAGS = flags.FLAGS
# TO-DO replace this with label map
def class_text_to_int(row_label):
if row_label == 'xiaoying':
return 1
# elif row_label == 'vehicle':
# return 2
else:
return 0
def split(df, group):
data = namedtuple('data', ['filename', 'object'])
gb = df.groupby(group)
return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)]
def create_tf_example(group, path):
with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = Image.open(encoded_jpg_io)
width, height = image.size
filename = group.filename.encode('utf8')
image_format = b'jpg'
xmins = []
xmaxs = []
ymins = []
ymaxs = []
classes_text = []
classes = []
for index, row in group.object.iterrows():
xmins.append(row['xmin'] / width)
xmaxs.append(row['xmax'] / width)
ymins.append(row['ymin'] / height)
ymaxs.append(row['ymax'] / height)
classes_text.append(row['class'].encode('utf8'))
classes.append(class_text_to_int(row['class']))
tf_example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example
def main(_):
writer = tf.python_io.TFRecordWriter(FLAGS.output_path)
# path = os.path.join(os.getcwd(), 'images/train')
path = os.path.join(os.getcwd(), 'jjp_picdata/train') # 当前路径加上你图片存放的路径
examples = pd.read_csv(FLAGS.csv_input)
grouped = split(examples, 'filename')
for group in grouped:
tf_example = create_tf_example(group, path)
writer.write(tf_example.SerializeToString())
writer.close()
output_path = os.path.join(os.getcwd(), FLAGS.output_path)
print('Successfully created the TFRecords: {}'.format(output_path))
if __name__ == '__main__':
tf.app.run()
分别 将train文件夹中 和test文件夹的内容 转换成record文件
 通过执行命令:
通过执行命令:
python3 jjp_csv_to_tfrecord.py --csv_input=jjp_picdata/train/xiaoying_train.csv --output_path=train.record
python3 jjp_csv_to_tfrecord.py --csv_input=jjp_picdata/test/xiaoying_test.csv --output_path=test.record
生成train.record 和 test.record文件 ,然后将他们放在与csv文件同级目录下。
至此我们得到训练数据和测试数据了
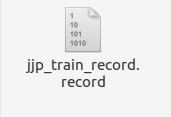
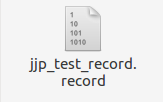
开始训练
1.训练文件的配置
将生成的csv和record文件(train和test两种)分别放在新建的jjp_picdata/train 和jjp_picdata/test文件夹下,并打开object_detection文件夹下的data文件夹,复制一个后缀为.pbtxt的文件到jjp_picdata文件夹下,并重命名为xiaoying.pbtxt
打开该文件,因为我只分了一类, 那就是小樱,所以将其他内容删除,只剩下这一个类别,并将name改为xiaoying。
我们在object_detection/jjp_picdata文件夹下新建一个Model文件夹,在里面新建一个记事本文件并命名为 ssd_mobilenet_v1_coco.config
这是我们的模型配置文件:
复制以下内容,注释部分改成你自己的内容:
# SSD with Mobilenet v1 configuration for MSCOCO Dataset.
# Users should configure the fine_tune_checkpoint field in the train config as
# well as the label_map_path and input_path fields in the train_input_reader and
# eval_input_reader. Search for "PATH_TO_BE_CONFIGURED" to find the fields that
# should be configured.
model {
ssd {
num_classes: 1 # 你类别的数量,我这里只分了一类
box_coder {
faster_rcnn_box_coder {
y_scale: 10.0
x_scale: 10.0
height_scale: 5.0
width_scale: 5.0
}
}
matcher {
argmax_matcher {
matched_threshold: 0.5
unmatched_threshold: 0.5
ignore_thresholds: false
negatives_lower_than_unmatched: true
force_match_for_each_row: true
}
}
similarity_calculator {
iou_similarity {
}
}
anchor_generator {
ssd_anchor_generator {
num_layers: 6
min_scale: 0.2
max_scale: 0.95
aspect_ratios: 1.0
aspect_ratios: 2.0
aspect_ratios: 0.5
aspect_ratios: 3.0
aspect_ratios: 0.3333
}
}
image_resizer {
fixed_shape_resizer {
height: 300
width: 300
}
}
box_predictor {
convolutional_box_predictor {
min_depth: 0
max_depth: 0
num_layers_before_predictor: 0
use_dropout: false
dropout_keep_probability: 0.8
kernel_size: 1
box_code_size: 4
apply_sigmoid_to_scores: false
conv_hyperparams {
activation: RELU_6,
regularizer {
l2_regularizer {
weight: 0.00004
}
}
initializer {
truncated_normal_initializer {
stddev: 0.03
mean: 0.0
}
}
batch_norm {
train: true,
scale: true,
center: true,
decay: 0.9997,
epsilon: 0.001,
}
}
}
}
feature_extractor {
type: 'ssd_mobilenet_v1'
min_depth: 16
depth_multiplier: 1.0
conv_hyperparams {
activation: RELU_6,
regularizer {
l2_regularizer {
weight: 0.00004
}
}
initializer {
truncated_normal_initializer {
stddev: 0.03
mean: 0.0
}
}
batch_norm {
train: true,
scale: true,
center: true,
decay: 0.9997,
epsilon: 0.001,
}
}
}
loss {
classification_loss {
weighted_sigmoid {
}
}
localization_loss {
weighted_smooth_l1 {
}
}
hard_example_miner {
num_hard_examples: 3000
iou_threshold: 0.99
loss_type: CLASSIFICATION
max_negatives_per_positive: 3
min_negatives_per_image: 0
}
classification_weight: 1.0
localization_weight: 1.0
}
normalize_loss_by_num_matches: true
post_processing {
batch_non_max_suppression {
score_threshold: 1e-8
iou_threshold: 0.6
max_detections_per_class: 100
max_total_detections: 100
}
score_converter: SIGMOID
}
}
}
train_config: {
batch_size: 16 # 电脑好的话可以调高点,我电脑比较渣就调成16了
optimizer {
rms_prop_optimizer: {
learning_rate: {
exponential_decay_learning_rate {
initial_learning_rate: 0.004
decay_steps: 800720
decay_factor: 0.95
}
}
momentum_optimizer_value: 0.9
decay: 0.9
epsilon: 1.0
}
}
# Note: The below line limits the training process to 200K steps, which we
# empirically found to be sufficient enough to train the pets dataset. This
# effectively bypasses the learning rate schedule (the learning rate will
# never decay). Remove the below line to train indefinitely.
num_steps: 50000 # 训练的steps
data_augmentation_options {
random_horizontal_flip {
}
}
data_augmentation_options {
ssd_random_crop {
}
}
}
train_input_reader: {
tf_record_input_reader {
input_path: "/home/daniel/tensorflow/models/research/object_detection/jjp_picdata/train/jjp_train_record.record" # 训练的tfrrecord文件路径
}
label_map_path: "/home/daniel/tensorflow/models/research/object_detection/jjp_picdata/xiaoying.pbtxt"
}
eval_config: {
num_examples: 10 # 验证集的数量
# Note: The below line limits the evaluation process to 10 evaluations.
# Remove the below line to evaluate indefinitely.
max_evals: 10
}
eval_input_reader: {
tf_record_input_reader {
input_path: "/home/daniel/tensorflow/models/research/object_detection/jjp_picdata/test/jjp_test_record.record" # 验证的tfrrecord文件路径
}
label_map_path: "/home/daniel/tensorflow/models/research/object_detection/jjp_picdata/xiaoying.pbtxt"
shuffle: false
num_readers: 1
}
至此,我们模型文件就配置好啦!!!
训练模型:
然后我们在object_detection目录下打开终端,进入 tensorflow环境
然后执行以下命令:
python3 model_main.py --pipeline_config_path=jjp_picdata/model/ssd_mobilenet_v1_coco.config --model_dir=jjp_picdata/model --alsologtostderr
部分参数可微调。
至此,模型就开始训练了,耐心等待训练完成即可。
在训练过程中如果出现no model named pycocotools的问题的话
参考这个链接
注意安装pycocotools要在你创建的tensorflow环境下。
如果想观察训练过程中参数的变化以及网络的话,可以打开新的一个新的终端切换到tensorflow环境下 切换到object_detection文件夹下
输入命令:tensorboard --logdir=jjp_picdata/model),复制出现的网址即可。如图所示\
如果显示不出来的话,新建网页在地址栏输入http://localhost:6006/(后面的6006是我的端口号,根据你自己的输入)
观察收敛,收敛不是很稳定,这是由于图片不多的原因:


保存模型
定位到object_detection目录下,打开终端,进入tensorflow环境 输入命令:
python3 export_inference_graph.py --input_type=image_tensor --pipeline_config_path=jjp_picdata/model/ssd_mobilenet_v1_coco.config --trained_checkpoint_prefix=jjp_picdata/model/model.ckpt-39802 --output_directory=jjp_picdata/model/
–trained_checkpoint_prefix=jjp_picdata/model/model.ckpt-39802
这个checkpoint(.ckpt-后面的数字)可以在training文件夹下找到你自己训练的模型的情况,填上对应的数字(如果有多个,选最大的)。
–output_directory=jjp_picdata/model/
output_directory是输出模型的路径
运行完后,可以在jjp_picdata/model/ (这是我的名字)文件夹下发现若干文件
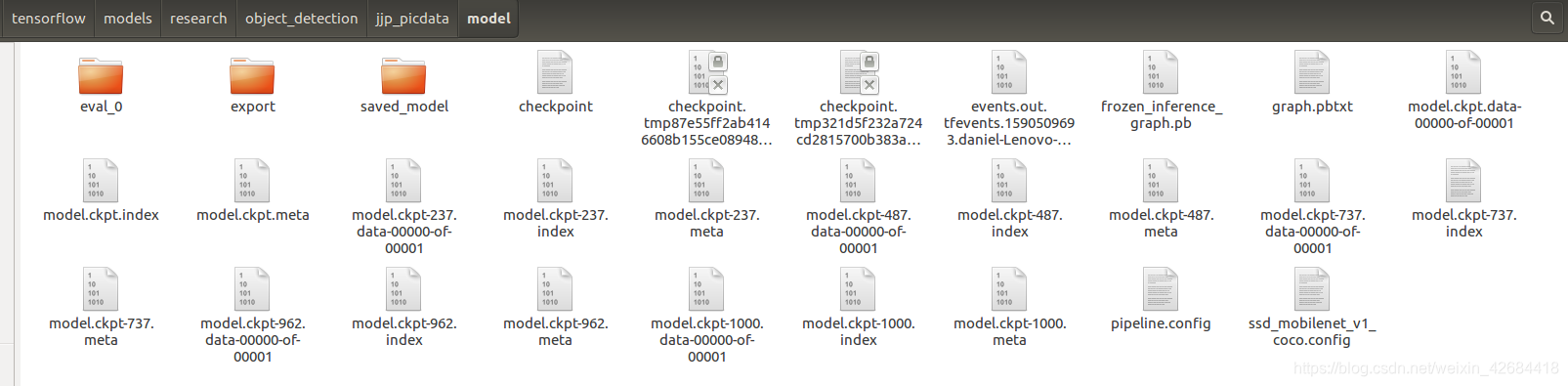
frozen_inference_graph.pb就是我们训练后得到的模型
训练的部分也完成了,接下来就是最后的test部分了,excited!
测试模型并输出
在jjp_picdata目录下建立model_test_image文件夹,在其中放入我们想要检测的图片

# -*- coding: utf-8 -*-
"""
Created on Thu Jan 11 16:55:43 2018
@author: Xiang Guo
"""
#Imports
import numpy as np
import os
import six.moves.urllib as urllib
import sys
import tarfile
import tensorflow as tf
import zipfile
from collections import defaultdict
from io import StringIO
from matplotlib import pyplot as plt
from PIL import Image
#if tf.__version__ < '1.4.0':
# raise ImportError('Please upgrade your tensorflow installation to v1.4.* or later!')
#Env setup
# This is needed to display the images.
#%matplotlib inline
# This is needed since the notebook is stored in the object_detection folder.
sys.path.append("..")
#Object detection imports
from research.object_detection.utils import label_map_util
from research.object_detection.utils import visualization_utils as vis_util
#Model preparation
# What model to download.
#MODEL_NAME = 'tv_vehicle_inference_graph'
#MODEL_NAME = 'tv_vehicle_inference_graph_fasterCNN'
#MODEL_NAME = 'tv_vehicle_inference_graph_ssd_mobile'
#MODEL_NAME = 'ssd_mobilenet_v1_coco_2017_11_17' #[30,21] best
#MODEL_NAME = 'ssd_inception_v2_coco_2017_11_17' #[42,24]
#MODEL_NAME = 'faster_rcnn_inception_v2_coco_2017_11_08' #[58,28]
#MODEL_NAME = 'faster_rcnn_resnet50_coco_2017_11_08' #[89,30]
#MODEL_NAME = 'faster_rcnn_resnet50_lowproposals_coco_2017_11_08' #[64, ]
#MODEL_NAME = 'rfcn_resnet101_coco_2017_11_08' #[106,32]
'''
MODEL_FILE = MODEL_NAME + '.tar.gz'
DOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/'
'''
# Path to frozen detection graph. This is the actual model that is used for the object detection.
#PATH_TO_CKPT = MODEL_NAME + '/frozen_inference_graph.pb'
# 我们上一步得到的模型
PATH_TO_CKPT="/home/daniel/tensorflow/models/research/object_detection/jjp_picdata/model/frozen_inference_graph.pb"
# List of the strings that is used to add correct label for each box.
#PATH_TO_LABELS = os.path.join('training', 'tv_vehicle_detection.pbtxt')
# 我们的分类,这里只有一类 xiaoying
PATH_TO_LABELS="/home/daniel/tensorflow/models/research/object_detection/jjp_picdata/xiaoying.pbtxt"
NUM_CLASSES = 1
'''
#Download Model
opener = urllib.request.URLopener()
opener.retrieve(DOWNLOAD_BASE + MODEL_FILE, MODEL_FILE)
tar_file = tarfile.open(MODEL_FILE)
for file in tar_file.getmembers():
file_name = os.path.basename(file.name)
if 'frozen_inference_graph.pb' in file_name:
tar_file.extract(file, os.getcwd())
'''
#Load a (frozen) Tensorflow model into memory.
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
# Loading label map
label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES, use_display_name=True)
category_index = label_map_util.create_category_index(categories)
# Helper code
def load_image_into_numpy_array(image):
(im_width, im_height) = image.size
return np.array(image.getdata()).reshape(
(im_height, im_width, 3)).astype(np.uint8)
#Detection
# For the sake of simplicity we will use only 2 images:
# image1.jpg
# image2.jpg
# If you want to test the code with your images, just add path to the images to the TEST_IMAGE_PATHS.
# 我们要测试的图片
PATH_TO_TEST_IMAGES_DIR = '/home/daniel/tensorflow/models/research/object_detection/jjp_picdata/model_test_image'
TEST_IMAGE_PATHS = [os.path.join(PATH_TO_TEST_IMAGES_DIR, 'test{}.jpg'.format(i)) for i in range(1, 4)]
# Size, in inches, of the output images.
IMAGE_SIZE = (12, 8)
with detection_graph.as_default():
with tf.Session(graph=detection_graph) as sess:
# Definite input and output Tensors for detection_graph
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
# Each box represents a part of the image where a particular object was detected.
detection_boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
# Each score represent how level of confidence for each of the objects.
# Score is shown on the result image, together with the class label.
detection_scores = detection_graph.get_tensor_by_name('detection_scores:0')
detection_classes = detection_graph.get_tensor_by_name('detection_classes:0')
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
for image_path in TEST_IMAGE_PATHS:
image = Image.open(image_path)
# the array based representation of the image will be used later in order to prepare the
# result image with boxes and labels on it.
image_np = load_image_into_numpy_array(image)
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
# Each box represents a part of the image where a particular object was detected.
boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
# Each score represent how level of confidence for each of the objects.
# Score is shown on the result image, together with the class label.
scores = detection_graph.get_tensor_by_name('detection_scores:0')
print(scores)
classes = detection_graph.get_tensor_by_name('detection_classes:0')
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
# Actual detection.
(boxes, scores, classes, num_detections) = sess.run(
[boxes, scores, classes, num_detections],
feed_dict={
image_tensor: image_np_expanded})
# Visualization of the results of a detection.
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores),
category_index,
use_normalized_coordinates=True,
line_thickness=8)
plt.figure(figsize=IMAGE_SIZE)
plt.imshow(image_np)
plt.show()
然后在research目录下打开终端,切换到tensorflow环境下,测试模型,得到输出:



可以看出准确率还是很高的。
参考文章
Tensorflow(一) TFRecord生成与读取
tensorflow目标检测API之训练自己的数据集
tensorflow目标检测API之训练自己的数据集