将注释的xml文件转换为csv格式使用xml_to_csv.py,将生成train.csv训练集和eval.csv验证集。具体代码如下:
import os
import glob
import pandas as pd
import xml.etree.ElementTree as ET
def xml_to_csv(path):
xml_list = []
# 读取注释文件
for xml_file in glob.glob(path + '/*.xml'):
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall('object'):
value = (root.find('filename').text.split('.')[0] + '.jpg',
int(root.find('size')[0].text),
int(root.find('size')[1].text),
member[0].text,
int(member[4][0].text),
int(member[4][1].text),
int(member[4][2].text),
int(member[4][3].text)
)
xml_list.append(value)
column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax']
# 将所有数据分为样本集和验证集,一般按照3:1的比例
train_list = xml_list[0: int(len(xml_list) * 0.67)]
eval_list = xml_list[int(len(xml_list) * 0.67) + 1: ]
# 保存为CSV格式
train_df = pd.DataFrame(train_list, columns=column_name)
eval_df = pd.DataFrame(eval_list, columns=column_name)
train_df.to_csv('data/train.csv', index=None)
eval_df.to_csv('data/eval.csv', index=None)
def main():
path = r'D:\testdata\annotations' # 换成自己的标注图片xml文件的路径
xml_to_csv(path)
print('Successfully converted xml to csv.')
main()
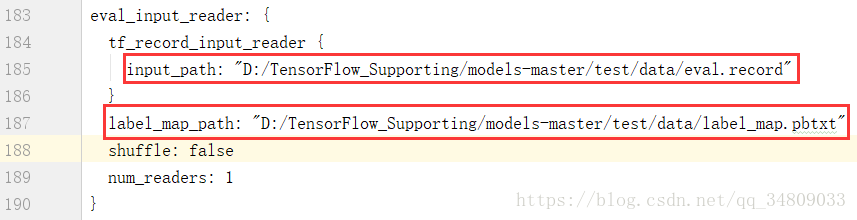
生成TFRecord文件
from __future__ import division
from __future__ import print_function
from __future__ import absolute_import
import os
import io
import pandas as pd
import tensorflow as tf
from PIL import Image
from object_detection.utils import dataset_util
from collections import namedtuple, OrderedDict
flags = tf.app.flags
flags.DEFINE_string('csv_input', '', 'Path to the CSV input')
flags.DEFINE_string('output_path', '', 'Path to output TFRecord')
FLAGS = flags.FLAGS
# 将分类名称转成ID号
def class_text_to_int(row_label):
# if row_label == 'syjxh':
# return 1
# elif row_label == 'dnb':
# return 2
# elif row_label == 'cjzd':
# return 3
# elif row_label == 'fy':
# return 4
# elif row_label == 'ecth' or row_label == 'etch': # 妈的,标记写错了,这里简单处理一下
# return 5
# elif row_label == 'lp':
# return 6
if row_label == 'raccoon':
return 1
else:
print('NONE: ' + row_label)
None
def split(df, group):
data = namedtuple('data', ['filename', 'object'])
gb = df.groupby(group)
return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)]
def create_tf_example(group, path):
print(os.path.join(path, '{}'.format(group.filename)))
with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = Image.open(encoded_jpg_io)
width, height = image.size
filename = (group.filename + '.jpg').encode('utf8')
image_format = b'jpg'
xmins = []
xmaxs = []
ymins = []
ymaxs = []
classes_text = []
classes = []
for index, row in group.object.iterrows():
xmins.append(row['xmin'] / width)
xmaxs.append(row['xmax'] / width)
ymins.append(row['ymin'] / height)
ymaxs.append(row['ymax'] / height)
classes_text.append(row['class'].encode('utf8'))
classes.append(class_text_to_int(row['class']))
tf_example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example
def main(csv_input, output_path, imgPath):
writer = tf.python_io.TFRecordWriter(output_path)
path = imgPath
examples = pd.read_csv(csv_input)
grouped = split(examples, 'filename')
for group in grouped:
tf_example = create_tf_example(group, path)
writer.write(tf_example.SerializeToString())
writer.close()
print('Successfully created the TFRecords: {}'.format(output_path))
if __name__ == '__main__':
imgPath = r'D:\testdata\images'
# 生成train.record文件
output_path = 'data/train.record' # 换成训练文件输出路径
csv_input = 'data/train.csv' # 换成train.csv路径,这个文件由上个xml_to_csv.py程序产生
main(csv_input, output_path, imgPath)
# 生成验证文件 eval.record
output_path = 'data/eval.record' # 换成验证文件输出路径
csv_input = 'data/eval.csv' # 换成eval.csv路径,这个文件由上个xml_to_csv.py程序产生
main(csv_input, output_path, imgPath)