注:个人学习笔记
虚拟机克隆:
克隆虚拟机:
https://blog.csdn.net/qq_26222859/article/details/79378213 一定记住是完整克隆。若是创建链接克隆,会连母机都连不上网(完全删除克隆机即可)。
克隆的虚拟机完全删除:https://jingyan.baidu.com/article/a501d80c419089ec630f5e81.html
虚拟机克隆后,克隆的机器是无法上网的,因为和母机的IP地址和mac地址一样:1.修改每个克隆机的mac地址 https://zhidao.baidu.com/question/647935346987424205.html ;2.修改每个克隆机的IP(直接在母机的基础上依次加1即可)。
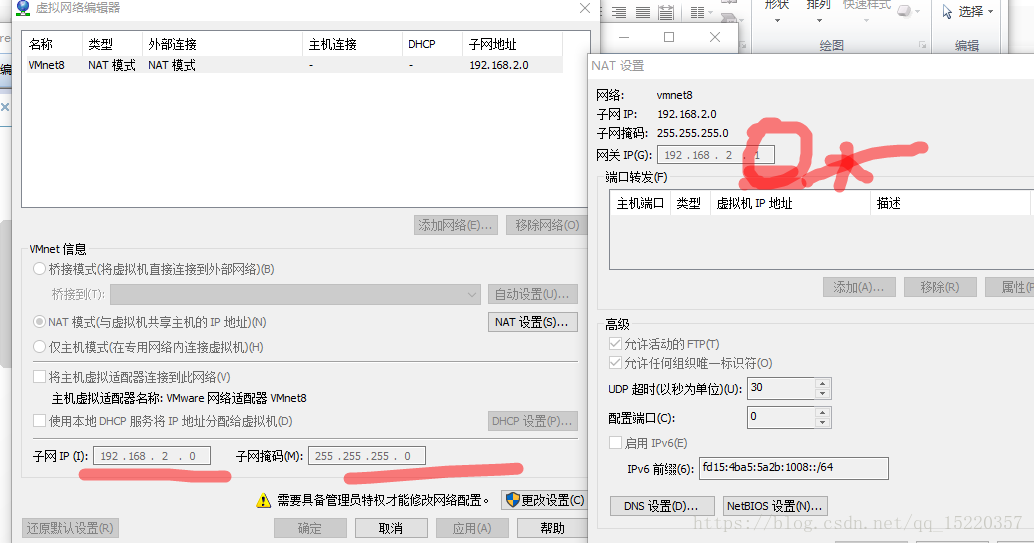
补充一句:网上好多删除 什么ruld文件下的文件,实际上centos7 是没有这个文件的,所以配置了好久都没有成功,今天意外发现居然是下面图的打圈出网关设为0了(所以,当网络出问题后还是看下配置是不是有问题,不然找好久都找不出问题出在哪里)。
Zookeeper:

伪分布式搭建:
1.上传zk安装包
2.解压
3.配置(先在一台节点上配置)
3.1添加一个zoo.cfg配置文件
$ZOOKEEPER/conf
mv zoo_sample.cfg zoo.cfg
3.2修改配置文件(zoo.cfg) //里面的tickTime 是心跳数,其他都使用默认配置
dataDir=/itcast/zookeeper-3.4.5/data //原来是tmp目录下,只要重启就没了,这里修改一下(这个目录要自己建立)
//在最后添加其他主机信息
server.1=itcast05:2888:3888
server.2=itcast06:2888:3888
server.3=itcast07:2888:3888
3.3在(dataDir=/itcast/zookeeper-3.4.5/data)创建一个myid文件,里面内容是server.N中的N(server.2里面内容为2)
指令:echo "1" > myid //将1输入到myid中。
3.4将配置好的zk拷贝到其他节点
scp -r /itcast/zookeeper-3.4.5/ itcast06:/itcast/
scp -r /itcast/zookeeper-3.4.5/ itcast07:/itcast/
3.5注意:在其他节点上一定要修改myid的内容
在itcast06应该讲myid的内容改为2 (echo "2" > myid)
在itcast07应该讲myid的内容改为3 (echo "3" > myid)
4.启动集群
分别启动zk,去每台机器的bin目录下:
./zkServer.sh start
简单的应用场景举例 - 分布式应用程序的同步:
分布式应用程序的配置文件都存在一台机器上,且一次只能有一个人访问修改。有一个问题是:万一存储配置信息的机器坏了怎么办?分布式(下图,这个配置文件会因为某台机器的修改而变化,怎么同步?zookeeper:存配置和少量状态信息,这样在一个部分应用程序上修改,其它应用程序就能马上得到修改的配置文件。具体的如支付宝的支付配置文件,这个配置文件在很多的应用中都有,如果我把这个配置文件放到zookeeper上,当我需要对这个配置文件进行一些升级时,只需要在一个应用上修改就行,其他使用该支付配置文件的应用就跟着修改了,不用人为的去升级,且速度极快,不怎么影响用户。通常机器数为奇数。):
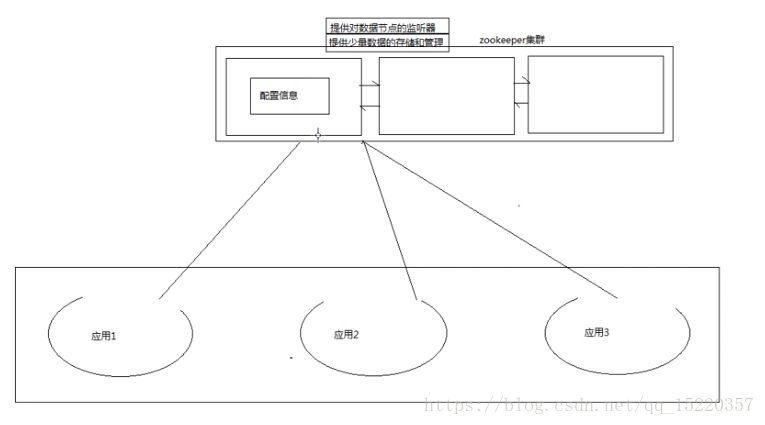
就和hadoop集群一样,zookeeper集群也有领导者和被领导者:

这里不得不说zookeeper的稳定性,当一个leader被杀死后,学习者又可以重新选举一个新的leader,且是自动的,前提是不能少于配置时节点数量的一半(如 配置3台,必须存活两台才能正常运行)。
Zookeeper的节点特性:
» Znode有两种类型,短暂的(ephemeral)和持久的(persistent)
» Znode的类型在创建时确定并且之后不能再修改
» 短暂znode的客户端会话结束时,zookeeper会将该短暂znode删除,短暂znode不可以有子节点
» 持久znode不依赖于客户端会话,只有当客户端明确要删除该持久znode时才会被删除
» Znode有四种形式的目录节点,PERSISTENT、PERSISTENT_SEQUENTIAL、EPHEMERAL、EPHEMERAL_SEQUENTIAL 。
高并发机制(HA):
原来的元数据管理虽然是可靠的,但是当NN死掉后,并不能快速的建立正常工作。NN:namenode;SN:secondnode。
HA(高并发架构):
- 能否让两个NN都正常响应客户端的请求?
应该让两个NN节点在某个时间只有一个节点正常相应客户端请求,响应请求的必须为ACTIVE状态的那一台。 - Standby状态的节点必须能够快速无缝地切换为active状态
意味着两个NN必须时刻保持元数据的一直。怎么做呢?将edits文件放在一个分布式系统上(qjournal:底层依赖zookeeper(zk)实现)。
这样当active机器出问题后,用户的请求能够无缝的切换到standby机器上去。因为active和standby都是在云上(云上存储和查询),所以切换过去得到的数据映射也是最新的,不影响用户使用。
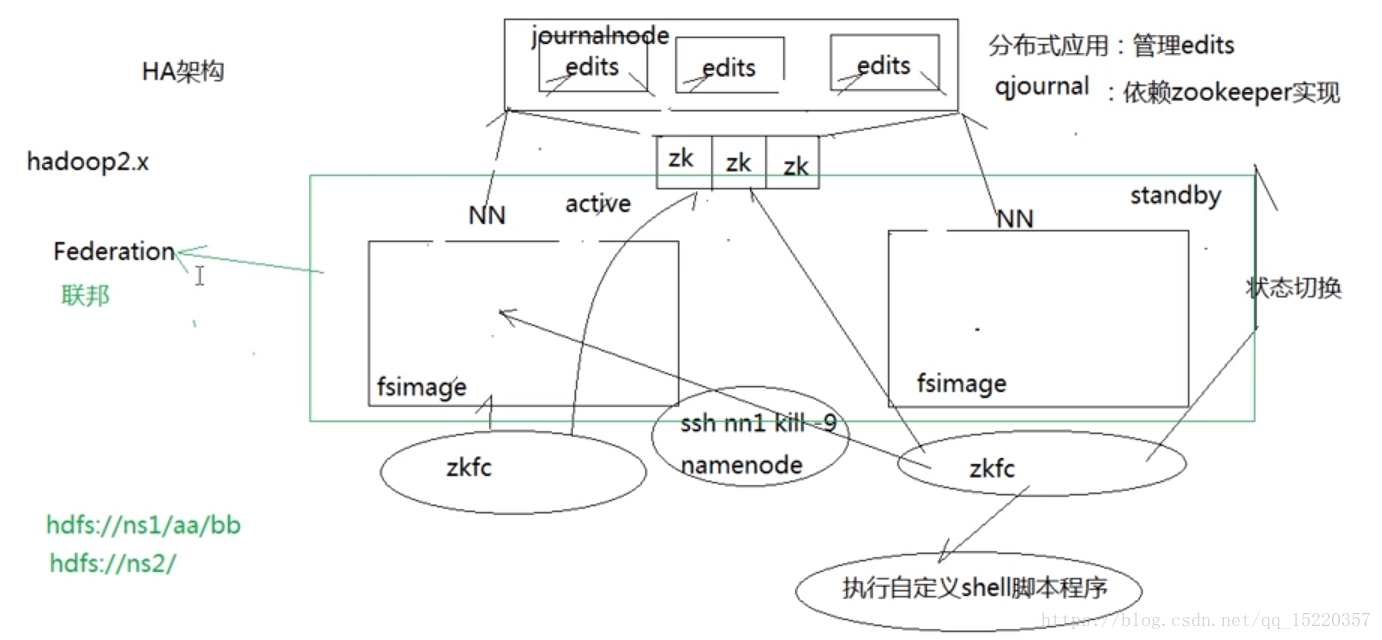
两个问题:
1.怎么切换呢?
转态管理进程Zkfc管理namenode节点的状态的转换。当左边的NN死掉后,zkfc感知这一状态,并发送给qjournal。但是有一个问题,可能某个时间段NN出现一个短暂性的停机(假死),但是一会又好了。因为它假死的时候另一个standby的NN切换到了active状态,所以此时出现了两个active的NN,这一现象叫: brain split。
2.如何避免brain split 现象出现?
Fencing机制(两个措施):(1)为了避免这一状况的发生,先去杀掉死机的NN,得到成功的返回值。但是,这个返回值可能会应为网络的原因导致接收不到。怎么解决?(2)当超过预定义的时间阈值还没有收到返回值时,执行预定义的shell脚本程序(如关掉左边的机器)。
在集群中可以有多对namenode(active和standby的namenode为一对),叫federation(联邦)。