在第一篇的配置文件的 基础上,接下来想写一点比较明显的 安装步骤
1准备好vmware 和 centos
1.1准备了vmware15.x版本,和centos6.x 安装在Windows电脑上
安装成功后是这样的图标

2虚拟机克隆
2.1在安装好虚拟机后对机器进行完整的克隆,成为一个虚拟机集群。

克隆后的虚拟机,02和03都是克隆的01虚拟机
2.2 配置克隆虚拟机的ip地址
vi /etc/sysconfig/network-scripts/ifcfg-eth0
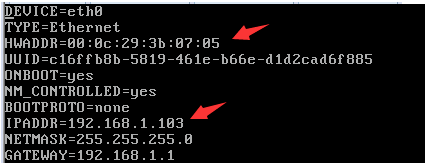
2.3 修改hostname名
如果只是修改hostname可以通过如下命令
vi /etc/sysconfig/network
修改其中的HOSTNAME项,不过此种方法需要重启后生效。
reboot重启
3对虚拟集群中的机器进行基本配置
3.1这3台虚拟机都要进行配置
vi /etc/hosts
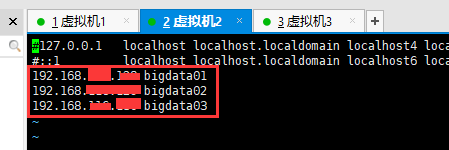
3.2 在windows上以下路径中设置地址。

3.3 集群资源规划

4 启动Hadoop&集群配置
4.1 新建opt文件夹
在opt文件夹里面建立如下几个文件夹
Mkdir tools
Mkdir modules
Mkdir datas
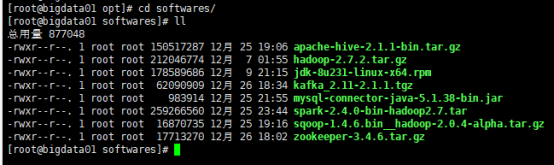
Mkdir softwares
所有下载的软件包 放入 softwares ,解压之后的文件放入modules。
4.2 Notepad++ 连接虚拟机
42.1为了方便操作设置Notepad++ 连接上三台虚拟机修改文件和配置

4.2.2打开Notepad++配置文件,使配置Linux操作系统连接信息。

4.2.3填写配置Notepad++文件,先添加点击Add new,创建一个新的连接。
4.2.4配置Linux的Ip信息,没有说明的按照默认就可以了,需要注意的是连接类型得选SFTP。

4.2.5打开连接Notepad++里面的linux连接
4.2.6刷新Notepad++,获取linux里面的文件列表。
配置:
在文件配置前先创建一个current文件夹,用来存放namenode和datanode的节点信息
Core-site.xml, Yarn-site.xml, Hdfs-site.xml 这3个文件的配置情况下面博客:
https://blog.csdn.net/for_yayun/article/details/105580783
这个里面有涉及到的文件存放路径,请提取创建好。如下图:

我是在第一台机器也就是bigdata01 里面的slaves 文件配置如下:

4.3 分布式集群配置-HDFS
4.3.1格式化文件
命令 bin/hdfs namenode -format 如下图:

操作完成后进行命令传递给另外2台:
scp -r hadoop-2.7.2/ bigdata02:/opt/modules/
scp -r hadoop-2.7.2/ bigdata03:/opt/modules/

4.3.2 启动 hadoop
根据上面的规划表来进行相当应的启动机器
Namenode 启动

Datanode 启动

结果如下
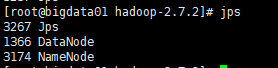
查看网页端,全部启动成功。

4.3.3 在hdfs的文件夹方便分类和存放数据
命令:bin/hdfs dfs -mkdir -p /user/yayun/data

上传 一份测试数据
命:bin/hdfs dfs -put /opt/modules/hadoop-2.7.2/etc/hadoop/core-site.xml /user/yayun/data

读取hdfs里面的文件
命令:bin/hdfs dfs -mkdir -p /user/yayun/data

4.4 分布式集群配置-YARN
4.4.1 yarn-site文件配置:

4.4.2 更改 mapred-site.template 为 mapred-site.xml 并且进行site文件配置

4.5 将上面配置的好的文件在一次分发到另外2台机器上
scp -r ./* bigdata02:/opt/modules/hadoop-2.7.2/etc/hadoop/
scp -r ./* bigdata03:/opt/modules/hadoop-2.7.2/etc/hadoop/

至此Hadoop 配置启动完成。
4.6 启动resourcemanager,nodemanager
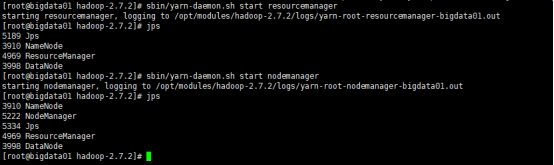
启动另外02和03虚拟机的nodemanager


查看网页端的监控页面
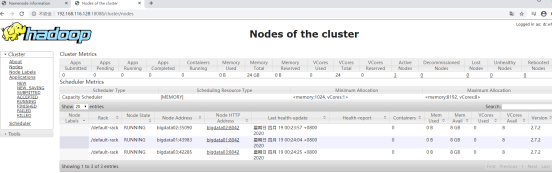
5 Hadoop伪分布式集群数据运行测试
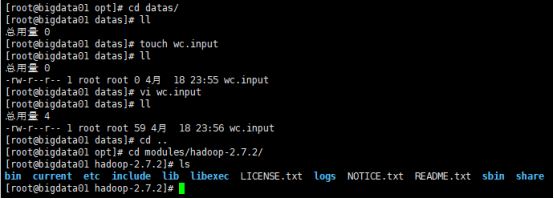
5.1先准备一个测试文件数据
数据放入之前创建的datas 文件夹里面,并且编辑。
然后进入modules/Hadoop2.7.2文件夹里面
5.2 将准备的数据上传到 hdfs
命令:bin/hdfs dfs -put /opt/datas/wc.input /user/yayun/data

网页查看数据:

未完待续ing。。。。。
