接上一篇文章
在上一篇文章中遗漏了一个core-site的配置文件

这个是改默认的名字为自己需要的,其效果在如下:

好了接下来 说接着上一篇文章写:
开始 启动jobhistory
命令: sbin/mr-jobhistory-daemon.sh start historyserver

运行mapreduce
创建一个输出目录
命令:bin/hdfs dfs -mkdir -p /user/yayun/data/output/

开始运行
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/yayun/data/wc.input /user/yayun/data/output/1

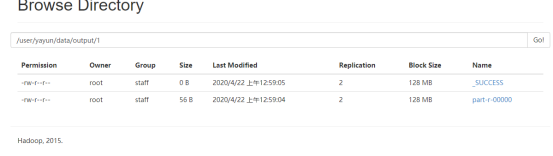

网页端查看
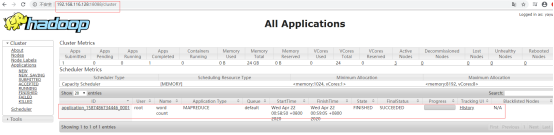
4.9.2 结果查看:
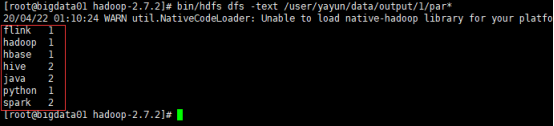
bin/hdfs dfs -text /user/yayun/data/output/1/par*
SSH无密码登录
在主节点生成密钥
确保在生成公钥和密钥之前ssh目录下无任何文件,如果有则清理。
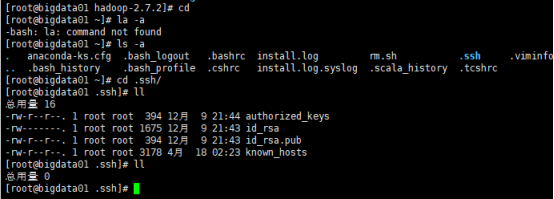
生成密钥的命令:ssh-keygen -t rsa

将密钥分发到3台机器上,因为机器1上也有datanode
ssh-copy-id bigdata01
ssh-copy-id bigdata02
ssh-copy-id bigdata03

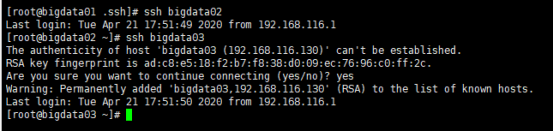
测试
命令:ssh bigdata02
停掉使用的yarn 的命令:sbin/stop-yarn,sh
停掉使用的hdfs 的命令:sbin/stop-all.sh
开启使用的hdfs 的命令:sbin/start-all.sh
至此一个 Hadoop 伪分布式集群就正式创建。
至于其他生态圈的工具安装 后面会更新中,在这个过程中我遇到很多的问题,很感谢csdn上的大佬,让我有优质的资料可查,并且一步步解决问题。并且成功。
