Abstract
本文提出一种简单而强有力的CNN架构RepVGG,在推理阶段,它具有与VGG类似的架构,而在训练阶段,它则具有多分支架构体系,这种训练-推理解耦的架构设计源自一种称之为“重参数化(re-parameterization)”的技术。

优势
- Fast:相比VGG,现有的多分支架构理论上具有更低的Flops,但推理速度并未更快。比如VGG16的参数量为EfficientNetB3的8.4倍,但在1080Ti上推理速度反而快1.8倍。这就意味着前者的计算密度是后者的15倍。Flops与推理速度的矛盾主要源自两个关键因素:(1) MAC(memory access cose),比如多分支结构的Add与Cat的计算很小,但MAC很高; (2)并行度,已有研究表明:并行度高的模型要比并行度低的模型推理速度更快。
- Memory-economical: 多分支结构是一种内存低效的架构,这是因为每个分支的结构都需要在Add/Concat之前保存,这会导致更大的峰值内存占用;而plain模型则具有更好的内存高效特征。
- Flexible: 多分支结构会限制CNN的灵活性,比如ResBlock会约束两个分支的tensor具有相同的形状;与此同时,多分支结构对于模型剪枝不够友好。
基本结构
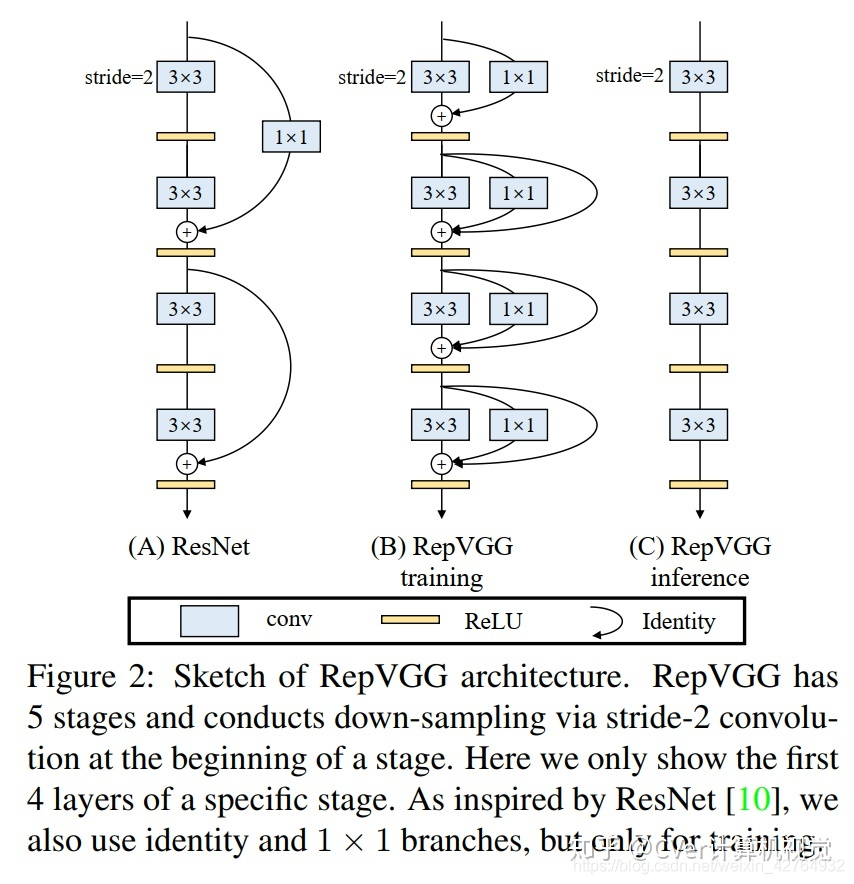
本文所设计的RepVGG则是受ResNet启发得到,尽管多分支结构对于推理不友好,但对于训练友好,作者将RepVGG设计为训练时的多分支,推理时单分支结构。作者参考ResNet的identity与 1 × 1 1\times1 1×1分支,设计了如下形式模块: y = x + g ( x ) + f ( x ) y=x+g(x)+f(x) y=x+g(x)+f(x)
其中, g ( x ) , f ( x ) g(x),f(x) g(x),f(x)分别对应 1 × 1 , 3 × 3 1\times1,3\times3 1×1,3×3卷积。
def conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups=1):
result = nn.Sequential()
result.add_module('conv', nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=padding, groups=groups, bias=False))
result.add_module('bn', nn.BatchNorm2d(num_features=out_channels))
return result
class RepVGGBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size,
stride=1, padding=0, dilation=1, groups=1, padding_mode='zeros', deploy=False):
super(RepVGGBlock, self).__init__()
self.deploy = deploy
self.groups = groups
self.in_channels = in_channels
assert kernel_size == 3
assert padding == 1
padding_11 = padding - kernel_size // 2
self.nonlinearity = nn.ReLU()
if deploy:
self.rbr_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=True, padding_mode=padding_mode)
else:
self.rbr_identity = nn.BatchNorm2d(num_features=in_channels) if out_channels == in_channels and stride == 1 else None
self.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, groups=groups)
self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride, padding=padding_11, groups=groups)
print('RepVGG Block, identity = ', self.rbr_identity)
在训练阶段deploy=False,通过简单的堆叠上述模块构建CNN架构;
而在推理阶段deploy=True,上述模块可以轻易转换为 y = h ( x ) y=h(x) y=h(x)形式,且 h ( x ) h(x) h(x)的参数可以通过线性组合方式从已训练好的模型中转换得到。
Re-param for Plain Inference-time Model
如何将三个分支合并呢?
定义:
卷积核: W ( 1 ) ∈ R C 2 × C 1 , W ( 3 ) ∈ R C 2 × C 1 × 3 × 3 W^{(1)}\in R^{C_{2}\times C_{1}}, W^{(3)}\in R^{C_{2}\times C_{1}\times 3 \times 3} W(1)∈RC2×C1,W(3)∈RC2×C1×3×3即 1 × 1 1\times1 1×1和 3 × 3 3\times3 3×3卷积
BN参数: μ ( 3 ) , σ ( 3 ) , γ ( 3 ) , β ( 3 ) \mu^{(3)}, \sigma ^{(3)}, \gamma ^{(3)}, \beta ^{(3)} μ(3),σ(3),γ(3),β(3)与 μ ( 1 ) , σ ( 1 ) , γ ( 1 ) , β ( 1 ) \mu^{(1)}, \sigma ^{(1)}, \gamma ^{(1)}, \beta ^{(1)} μ(1),σ(1),γ(1),β(1)分别是 1 × 1 1\times1 1×1和 3 × 3 3\times3 3×3卷积后的BatchNorm的参数, μ ( 0 ) , σ ( 0 ) , γ ( 0 ) , β ( 0 ) \mu^{(0)}, \sigma ^{(0)}, \gamma ^{(0)}, \beta ^{(0)} μ(0),σ(0),γ(0),β(0)表示identity分支的BatchNorm的参数
输入输出: M ( 1 ) ∈ R N × C 1 × H 1 × W 1 , M ( 2 ) ∈ R N × C 2 × H 2 × W 2 M^{(1)}\in R^{N \times C_{1}\times H_{1}\times W_{1}},M^{(2)}\in R^{N \times C_{2}\times H_{2}\times W_{2}} M(1)∈RN×C1×H1×W1,M(2)∈RN×C2×H2×W2
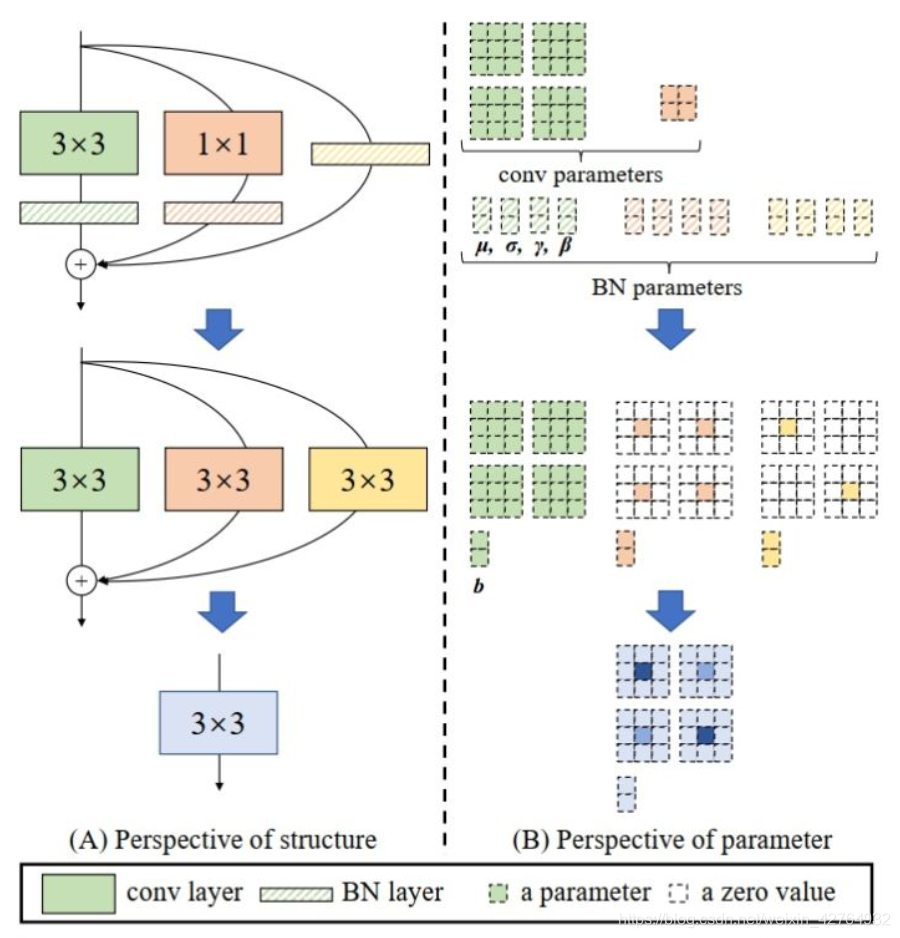
由此,一个基本结构可以表示为: M ( 2 ) = b n ( M ( 1 ) ∗ W ( 3 ) , μ ( 3 ) , σ ( 3 ) , γ ( 3 ) , β ( 3 ) ) + b n ( M ( 1 ) ∗ W ( 1 ) , μ ( 1 ) , σ ( 1 ) , γ ( 1 ) , β ( 1 ) ) + b n ( M ( 1 ) , μ ( 0 ) , σ ( 0 ) , γ ( 0 ) , β ( 0 ) ) M^{(2)}=bn(M^{(1)}*W^{(3)}, \mu ^{(3)}, \sigma ^{(3)}, \gamma ^{(3)}, \beta ^{(3)})\\+bn(M^{(1)}*W^{(1)}, \mu ^{(1)}, \sigma ^{(1)}, \gamma ^{(1)}, \beta ^{(1)})\\+bn(M^{(1)}, \mu ^{(0)}, \sigma ^{(0)}, \gamma ^{(0)}, \beta ^{(0)}) M(2)=bn(M(1)∗W(3),μ(3),σ(3),γ(3),β(3))+bn(M(1)∗W(1),μ(1),σ(1),γ(1),β(1))+bn(M(1),μ(0),σ(0),γ(0),β(0))
可以看到,每个分支都有BN层,而BN层可以拆开,
b n ( M , μ , σ , γ , β ) : , i , : , : = ( M : , i , : , : − μ i ) γ i σ i + β i . bn(M, \mu , \sigma , \gamma , \beta):,i,:,:=(M_{:,i,:,:}- \mu _{i})\frac{\gamma _{i}}{\sigma _{i}}+ \beta _{i}. bn(M,μ,σ,γ,β):,i,:,:=(M:,i,:,:−μi)σiγi+βi.将每个BN与其前接Conv层合并 W i , : , : , : ′ = γ i σ i W i , : , : , : , b i ′ = − μ i γ i σ i + β i \begin{matrix}W_{i,:,:,:}^{\prime}= \frac{\gamma _{i}}{\sigma _{i}}W_{i,:,:,:}, \\ \\b^{\prime}_{i}=- \frac{\mu _{i}\gamma _{i}}{\sigma _{i}}+ \beta _{i}\\ \end{matrix} Wi,:,:,:′=σiγiWi,:,:,:,bi′=−σiμiγi+βi
该分支变成了一个卷积核和一个bias的结构,同理,三个分支都可以变换,得到一个 3 × 3 3\times3 3×3卷积核,两个 1 × 1 1\times1 1×1卷积核以及三个bias参数;
三个bias参数可以通过简单的add方式合并为一个bias
卷积核则可以将 1 × 1 1\times1 1×1卷积核参数加到 3 × 3 3\times3 3×3卷积核的中心点得到
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1,1,1,1])
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def repvgg_convert(self):
kernel, bias = self.get_equivalent_kernel_bias()
return kernel.detach().cpu().numpy(), bias.detach().cpu().numpy(),
网络设计

RepVGG是一种类VGG的架构,在推理阶段它仅仅采用 3 × 3 3\times3 3×3卷积与ReLU,且未采用MaxPool。对于分类任务,采用GAP+全连接层作为输出头。
对于每个阶段的层数按照如下三种简单的规则进行设计:
-
第一个阶段具有更大的分辨率,故而更为耗时,为降低推理延迟仅仅采用了一个卷积层;
-
最后一个阶段因为具有更多的通道,为节省参数量,故而仅设计一个卷积层;
-
在倒数第二个阶段,类似ResNet,RepVGG放置了更多的层。
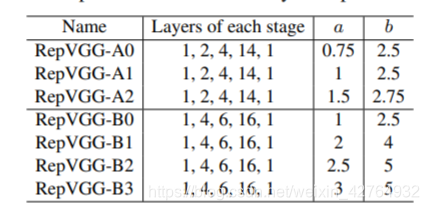
基于上述考量,RepVGG-A不同阶段的层数分别为1-2-4-14-1;与此同时,作者还构建了一个更深的RepVGG-B,其层数配置为1-4-6-16-1。RepVGG-A用于与轻量型网络和中等计算量网络对标,而RepVGG-B用于与高性能网络对标。
在不同阶段的通道数方面,作者采用了经典的配置64-128-256-512。与此同时,作者采用因子 a a a控制前四个阶段的通道,因子 b b b控制最后一个阶段的通道,通常 b > a b>a b>a(我们期望最后一层具有更丰富的特征)。为避免大尺寸特征的高计算量,对于第一阶段的输出通道做了约束 m i n ( 64 , 64 a ) min(64,64a) min(64,64a)。基于此得到的不同RepVGG见下表。