本文学习了RepVGG以及同作者在网络重参数化领域的几篇文章,总结其主要原理,试验重参数化方法的效果并分析其价值意义。
RepVGG是CVPR2021收录的一篇论文,作者是清华大学的丁霄汉博士,同一作者在该领域还有其他几篇论文:
ACNet:https://arxiv.org/abs/1908.03930
RepVGG:https://arxiv.org/abs/2101.03697
DiverseBranchBlock:https://arxiv.org/abs/2103.13425
ResRep:https://arxiv.org/abs/2007.03260
RepMLP:https://arxiv.org/abs/2105.01883
作者在他的知乎专栏里对这些文章有比较详细的讲解:https://www.zhihu.com/column/c_168760745。代码都已开源,在:https://github.com/DingXiaoH
我这里主要是按照我的理解把论文中的知识点整体梳理并实践操作一下,便于我加深学习。
1,网络重参数化的原理
这一系列文章主要围绕网络重参数化这一技术展开。网络重参数化可以认为是模型压缩领域的一种新技术,它的主要思想是把一个K x K的卷积层等价转换为若干种特定网络层的并联或串联,转换后的网络更复杂、参数更多,因此转换的网络在训练阶段有希望达到更好的效果,在推理阶段,又可以把大网络的参数等价转换到原来的KxK卷积层中,使得网络兼具了训练阶段大网络的更好的学习能力和推理阶段小网络的更高的计算速度。
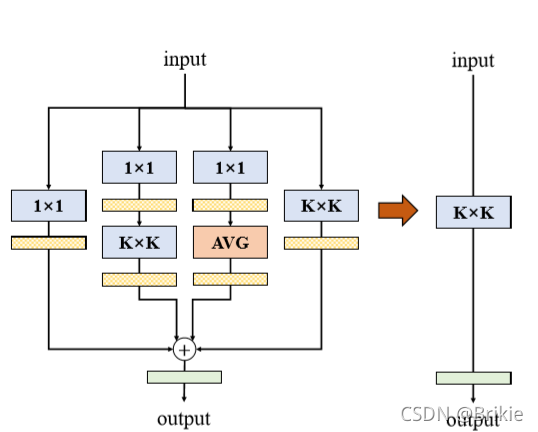
在DBB(DiverseBranchBlock)这篇文章中作者提到了6种可以和KxK卷积层等价转换的结构,如论文中的图Figure2. 其中的Transform VI就是ACNet论文中的结构,除了这6种外还有一种结构在DBB论文中没有提到,就是RepVGG中的结构,我把它画到下面图1.


上述这些结构可以归纳为以下几点:
(1)“吸BN”操作:KxK卷积层可以和BN层合并起来,把BN的参数转换到卷积的参数中,从而去掉BN。
(2)卷积是线性操作,满足叠加性质f(ax+by)=af(x)+bf(y),所以 conv(W1 + W2) = conv(W1) + conv(W2),因此可以把两个KxK卷积相加变成一个参数相加后的KxK卷积。
(3)1x1卷积可以看成是一个除中心点外其他都为0的KxK卷积(前提是K为奇数);1xK卷积和Kx1卷积可以看成是一个两边的行或列为0的KxK卷积;恒等变换则是一个更特殊的1x1卷积,可以理解为一个这样的CxCxKxK参数的KxK卷积:其中CxC部分为单位矩阵,而KxK部分的中心点为1,其余为0。
(4)1x1卷积和KxK卷积的串联可以将它们参数相乘后转换为一个KxK卷积(乘的时候需要一些转置操作,公式见原文)。
(5)AVG操作等效于一个元素都为1/(K*K)的KxK卷积。
(6)由于可叠加性质,上述各种结构还可以无限叠加组合,比如下图是论文中给出的DBB模块。
RepMLP是作者最新的一篇论文,这篇论文中指出,不仅KxK卷积可以用一系列更复杂的网络等价,多层全连接网络MLP也是线性操作,也是可以把卷积等价到MLP中。
2,网络重参数化的用途和意义
基于这套方法主要是对KxK卷积有用,当然它最能发挥作用的就是纯3x3卷积一卷到底的VGG了,作者在RepVGG一文中也展示了这个技巧在VGG上的巨大效果,能够打平现在的SOTA模型,确实让人眼前一亮。然而纯VGG占显存也大,并不适合在端侧设备部署,这就失去了模型压缩的本来意义,所以我觉得RepVGG的实用意义并不大。另外,网络重参数化方法也不能用于对任意网络模型进行压缩,它只能把一些特定网络结构压缩到KxK卷积中,并不是一种通用的方法。
然而KxK卷积在当前各种主流神经网络中非常普遍,如果把这些KxK卷积层进行复杂化后训练然后再重参数化后推理部署,就有望提高模型效果的同时又不影响推理时的速度,这可能是一个有实用价值的点。
3,我的试验
为了更深入的掌握这个方法并检验其效果,我准备做个试验,为了客观检验它,我们不用作者试验好的CIFAR10和Imagenet,以及VGG、ResNet等。我决定随机选一个任务,正好我刚刚做完无线通信AI的一个竞赛。这个任务当前比较主流的方法是CRNet,其中包含有多种卷积层,我们把它替换为等价多分支模块,观察训练时是否能有效提高效果。CRNet结构如下图,这个网络的作用是对一段用户侧的无线信号进行压缩编码,发送到基站后再解码,追求更高的还原率,具体介绍可参见原论文https://arxiv.org/abs/1910.14322。对于从训练好的网络重参数化到推理用KxK卷积层的过程我们一点不用担心,因为它是严格数学推导的,不会有问题,这里面不确定的是复杂化成多分支结构的大网络的训练过程是否真的有效,所以我们重点试这个。

这个网络结构中含有3x3卷积、5x5卷积,以及1x9、9x1、1x5、5x1卷积等,我们可以尝试把这些卷积层用DBB或并联一些其他等价结构来替换进行训练,然后推理阶段再把参数重整到原来的CRNet网络中。
| 网络结构 | 参数量 | FLOPs | 训练时间/ep | 效果(恢复率)ep10 | ep100 |
|---|---|---|---|---|---|
| CRNet | 926k | 711M | 234s | 0.8043 | 0.8152 |
| KxK -> DBB, Kx1 -> Kx1+ 1x1 | 2273k | 1744M | 590s | 0.8007 | - |
| KxK -> DBB | 2157k | 1656M | 480s | 0.8037 | 0.8173 |
| Kx1 -> Kx1+ 1x1 | 926k | 711M | 234s | 0.7996 | - |
注:为了比赛时的效果,我这里使用的CRNet比原论文中的中间层通道数更高,达到128。
从表中可以看出,进行等价替换后,并非更多分支更大的网络就一定训练的更好,在本例中把Kx1和1xK卷积都并联上一个1x1卷积反而是有害的,训练效果反而下降;有些情况下更大的等价网络确实有点用,如把KxK替换为DBB,在100epoch后效果比原CRNet微弱提升0.002,但此时训练速度比原来慢了一倍。
我分析,这个CRNet网络中本身已经使用了多分支结构,且KxK卷积用的不是很多,所以这种方法没有多大作用,如果是一些分支结构较少的网络和大量使用KxK卷积的网络,可能效果会明显一些。
4,总结
重参数化使用一种巧妙的方法把KxK卷积层替换为一些参数可线性组合的并联分支结构,这样可以通过牺牲一些训练速度来提高训练精度,在推理时把参数映射回原KxK卷积层,可使推理时的速度不变而精度提升。这种方法仅对特定结构有用,不能把任意网络重参数化为一个更小的网络。这种方法对于分支结构较少、KxK卷积使用较多,比较规整的网络会有更好的训练效果,对于推理速度要求较高且推理时硬件更支持KxK卷积运算的场合会有较好的应用。由于受到很多限制条件,个人认为这个方法的实用性仍不是很大,但这个方法有很好的启发意义,它说明一个大网络的参数有可能映射到一个小网络中,保持小网络的推理性能不变。