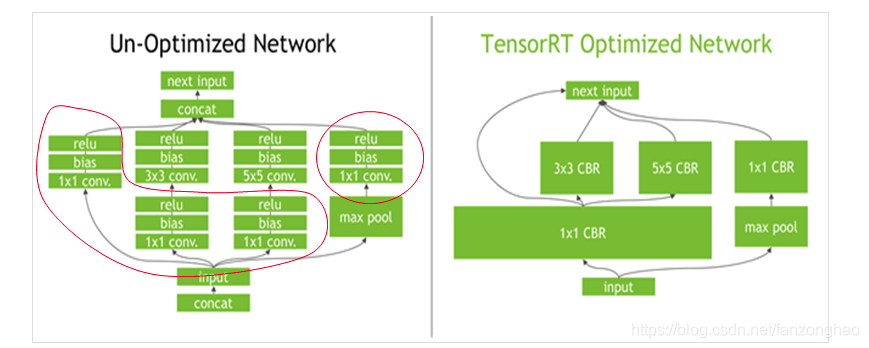
一.背景:
现在的一些复杂模型虽然有很高准确度,但是缺点也很明显:
1.多分支,带来了速度的减慢和降低显存的使用率;
2.Mobilenet虽然采用可分离卷积.shufflenet采用分组卷积,带来了flop降低,但是却增加了内存的访问成本(MAC)

二.网络结构
1. 模型
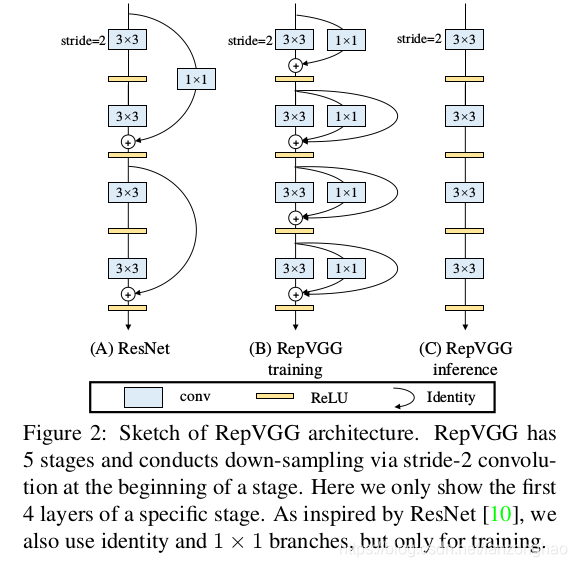
RepVGG在train和inference和ResNet的差异,可看出train时除了引入残差分支和1*1卷积分支,同时为了方便参数化重构,没有跨层连接.
2. 3*3卷积核优势
在N卡和MKL等,3*3卷积核计算密度是其他的4倍左右.


3.inference时重构参数细节

(1).卷积和BN合并

官方代码:
import copy
import torch
def fuse_conv_bn_eval(conv, bn):
assert(not (conv.training or bn.training)), "Fusion only for eval!"
fused_conv = copy.deepcopy(conv)
fused_conv.weight, fused_conv.bias = \
fuse_conv_bn_weights(fused_conv.weight, fused_conv.bias,
bn.running_mean, bn.running_var, bn.eps, bn.weight, bn.bias)
return fused_conv
def fuse_conv_bn_weights(conv_w, conv_b, bn_rm, bn_rv, bn_eps, bn_w, bn_b):
if conv_b is None:
conv_b = torch.zeros_like(bn_rm)
if bn_w is None:
bn_w = torch.ones_like(bn_rm)
if bn_b is None:
bn_b = torch.zeros_like(bn_rm)
bn_var_rsqrt = torch.rsqrt(bn_rv + bn_eps)
conv_w = conv_w * (bn_w * bn_var_rsqrt).reshape([-1] + [1] * (len(conv_w.shape) - 1)) #
conv_b = (conv_b - bn_rm) * bn_var_rsqrt * bn_w + bn_b
return torch.nn.Parameter(conv_w), torch.nn.Parameter(conv_b)(2)1*1卷积与残差分支转换成3*3
这里以单通道为例:

可看出1*1卷积和残差连接都转换成了3*3卷积,对于残差连接的多通道要注意的是只能有一个卷积核中心为1,其他卷积核都为0,这样才能复原原始输入.
三.实验结果:

四.一些想法