这里 ConvNets 对 ConvNets 的蒸馏,并发现当教师模型是大核 ConvNets ,学生模型是小核 ConvNets 时,蒸馏效果比较好:比如一个小于 30M 参数的卷积网络在 ImageNet 上实现了 83.1% 的精度
本文研究的是大核卷积网络作为教师去蒸馏小核卷积网络的问题。尽管 Vision Transformer 模型在越来越大的数据量和越来越大的模型量级的加持下在各种任务上实现了 SOTA 的性能,但是目前的资源受限的端侧设备上人们依然更倾向于使用 ConvNets ,而 ConvNets 相比于 Transformer 的性能差距是制约其广泛应用的瓶颈之一。蒸馏小一点的 ConvNets 模型是提升其性能的重要手段之一,那这时的教师模型就可以使用 Transformer 或者继续维持 ConvNets 。由于 Transformer 和 ConvNets 的整体结构相差过大,之前有研究证明它可能不是合适的教师模型。所以本文研究 ConvNets 对 ConvNets 的蒸馏,并发现当教师模型是大核 ConvNets ,学生模型是小核 ConvNets 时,蒸馏效果比较好:比如一个小于 30M 参数的卷积网络在 ImageNet 上实现了 83.1% 的精度。
大核卷积网络是比 Transformer 更好的教师吗?
论文名称:Are Large Kernels Better Teachers than Transformers for ConvNets? (ICML 2023)
论文地址:
https://arxiv.org/pdf/2305.19412.pdf
代码地址:
https://github.com/VITA-Group/SLaK
Transformer 给 AI 领域带来了一场历史性的变革,作为一种基础模型,刷新了计算机视觉,自然语言处理和生物科学等多个领域的记录。借助越来越大的模型和越来越大的数据集,在各个领域实现了先进的性能,可以说,Transformer 已经在学术界和工业界引起了一场令人望而却步的竞争,将模型的量级推向了更高的级别。
但是,目前在资源受限的端侧设备上,ConvNets 依然是更有优势的选择,比如 Edge AI 和 AIoT 设备上。但是 CNN 相比于 Transformer 的性能差距是制约其广泛应用的瓶颈之一。比如 ResNets 和 MobileNets 的训练成本更低,模型大小也负担得起,但是精度往往更差。因此,如何把这些小卷积核模型的性能提升到视觉 Transformer 的先进水平是个现实中值得研究的好问题。
知识蒸馏 (Knowledge Distillation, KD) 是提升小模型性能的有效手段,但是从视觉 Transformer 教师模型蒸馏到 CNN 学生模型似乎不是明智之选,因为之前就有工作研究过[1]。本文通过详细的实验发现:由于架构的相似性,不论是 Logit Distillation 还是 Feature Distillation,从大核 CNN 教师模型蒸馏到 小核 CNN 学生模型都是更有效的。 大核 ConvNets 在现代架构和训练策略的加持下,可以达到和 Vision Transformer 相当的精度水平,与 Vision Transformers 相比,大核 ConvNets 具有3个优势:
-
相当的分类精度
-
相似或者更大的感受野
-
基于卷积操作,和学生模型架构上更相似
但是,现代大核 ConvNets (ConvNeXt 和 SLaK) 与传统的小核 ConvNets 也有许多差异,比如:
-
一开始对图片进行的分块操作等,
-
使用 LayerNorm 而不是 BatchNorm
-
使用 GELU 激活函数 ReLU
作者还发现,这样得到的蒸馏模型比其他模型具有更大的 ERF 和更好的鲁棒性,这表明,除了准确性之外,大核 ConvNets 的其他良好属性也可以通过蒸馏范式转移到小核 ConvNets。
大核 ConvNets 蒸馏小核 ConvNets 的实验设置
本节中描述所使用的实验设置和基准。为了进行公平比较,需要仔细控制下面的几个关键组件。
① 评价指标
作者定义了两种指标,分别是直接增益 (Direct Gain) 和有效增益 (Effective Gain):
 New Knowledge Distillation (NKD)[3] 由原始损失、非目标分布式损失和目标软损失组成,可以表示为
New Knowledge Distillation (NKD)[3] 由原始损失、非目标分布式损失和目标软损失组成,可以表示为
 Feature Distillation:
Feature Distillation:

实验结果
Logit Distillation 实验结果:
1 对于小核 ConvNet,大核 ConvNet 是比 Transformer 更好的教师模型。
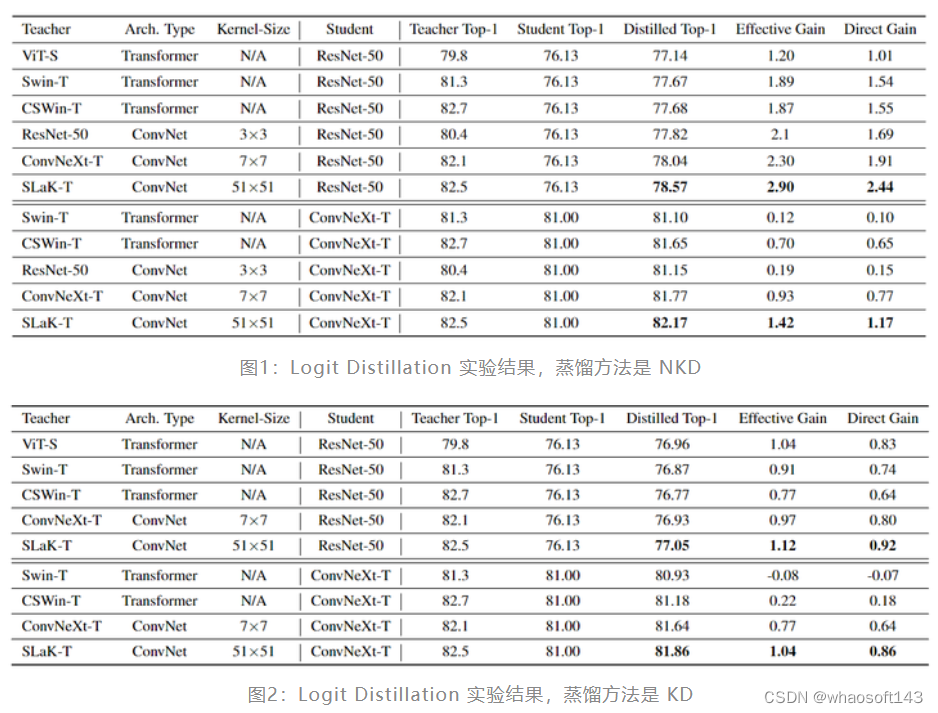 上图1和图2分别显示了 NKD 和 KD 在不同教师模型上的结果。总体而言,可以得出结论,SLaK-T 和 ConvNeXt-T 等大核 ConvNet 教师模型,虽然在自身性能上不一定超过 Transformer 教师模型,但是从蒸馏角度看,对学生模型的有效增益和直接增益指标方面都优于所有 Transformer。ResNet-50 和 ConvNeXt-T 的 SLaK-T 的直接增益分别达到 2.44% 和 1.17%,明显高于 Transformer 教师模型所带来的增益。
上图1和图2分别显示了 NKD 和 KD 在不同教师模型上的结果。总体而言,可以得出结论,SLaK-T 和 ConvNeXt-T 等大核 ConvNet 教师模型,虽然在自身性能上不一定超过 Transformer 教师模型,但是从蒸馏角度看,对学生模型的有效增益和直接增益指标方面都优于所有 Transformer。ResNet-50 和 ConvNeXt-T 的 SLaK-T 的直接增益分别达到 2.44% 和 1.17%,明显高于 Transformer 教师模型所带来的增益。
2 学生从更大的 Kernel Size 中受益更多。
同样是大核 ConvNet,51×51 的 SLaK-T 蒸馏的学生模型在有效增益和直接增益指标下始终优于 ConvNeXt-T 蒸馏的学生模型,表明学生从更大的 Kernel Size 中受益更多。
3 大核 ConvNet 帮助学生模型收敛更快。
在有监督训练情况下,ConvNeXt-T 需要 300 个 Epoch 才能达到 ImageNet 上的 82.1% 的准确率,而使用 SLaK-T 作为教师模型蒸馏仅仅 120 Epoch 就可以达到一样的精度。
Feature Distillation 实验结果
为了全面理解视觉 Transformer 和大核 ConvNet 教师模型的效果,作者还比较了一些特征蒸馏的方法,具体是蒸馏最后一个 Stage 的输出特征。此外,另一种常见的做法是将 Logit Distillation 与 Feature Distillation 相结合以进一步提高性能。
作者将 FD[5] 的损失函数与 NKD[6] 的损失函数相结合,并使用学生模型 ResNet-50 评估不同的教师模型。数字 LL 表示蒸馏 LL 层特征,比如 L=2L=2 就代表最后2个阶段的输出用于构建特征蒸馏损失。
 图3:Feature Distillation 实验结果,蒸馏方法是 FD
图3:Feature Distillation 实验结果,蒸馏方法是 FD
如图3所示,大核 ConvNet 的蒸馏性能依然超过了 Transformer,有趣的是,虽然 SLaK-T 在特征蒸馏中仅比 Swin-T 高出 0.08% 的直接增益,但当与 Logit 蒸馏结合时,增益增加到 0.66%。这说明大核 ConvNet 不仅对 Logit Distillation 帮助很大,对 Logit Distillation + Feature Distillation 的帮助也很大。
更长的训练实验结果
最近的研究[7]表明,知识蒸馏需要通常更多的训练 Epoch 数才能达到最佳性能,比监督学习中常用的 Epoch 数多得多。因此这里作者还将训练时间从 120 个扩展到 300 个 Epoch。结果如下图4所示,ResNet-50 的性能在将训练时期从 120 个 Epoch 扩展到 300 个 Epoch 时获得了 2.05% 的性能提升。SLaK-T 这个卷积核最大的教师模型蒸馏得到的学生模型的性能也是最好的。
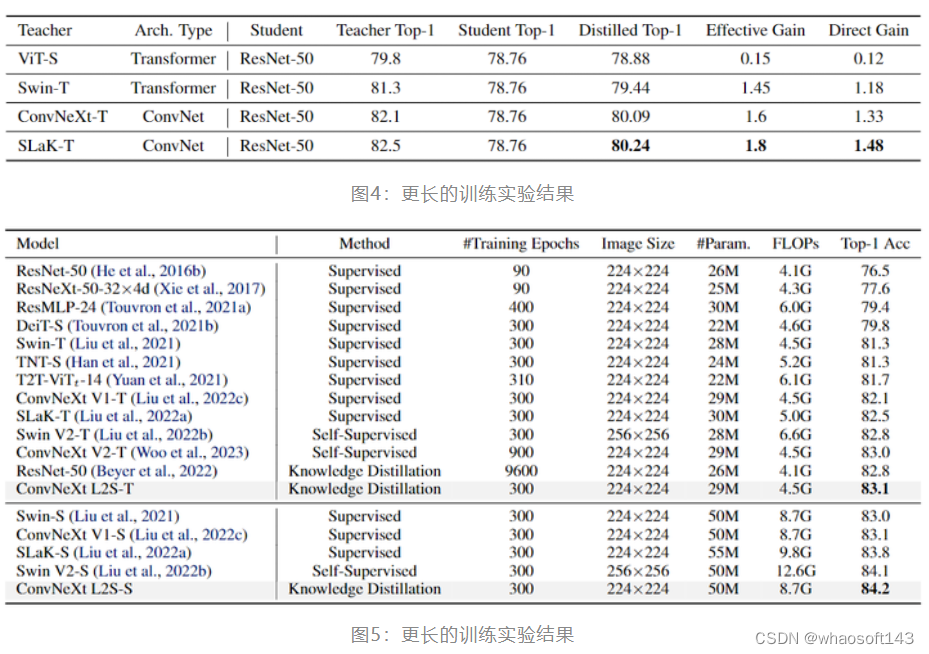 图5所示,从 51×51 SLaK-T 蒸馏得到的 ConvNeXt-Tiny 模型在 300 Epoch 的训练策略下获得了 83.1% 的 ImageNet-1K 精度,得到最先进的效果。这个精度超越了 MAE 自监督训练 900 Epoch 得到的 ConvNeXt V2-T 的精度。
图5所示,从 51×51 SLaK-T 蒸馏得到的 ConvNeXt-Tiny 模型在 300 Epoch 的训练策略下获得了 83.1% 的 ImageNet-1K 精度,得到最先进的效果。这个精度超越了 MAE 自监督训练 900 Epoch 得到的 ConvNeXt V2-T 的精度。
大卷积核教师蒸馏对 Effective Receptive Fields (ERF) 的影响
CV 中 Effective Receptive Fields (ERF) 也是个很重要的概念,描述的是对于一个神经网络层的输出单元,输入中对该输出有不可忽略的影响的部分。换句话讲,感受野之外的输入不会对这个位置的输出值造成影响。人们普遍认为,大核 ConvNet 和 Vision Transformer 都有更大的 ERF,这反过来又有助于它们优于传统的小核 ConvNet。
这一小节的实验,作者想看看蒸馏能不能帮助小核 ConvNet 获得更大一点的 ERF,改善它这方面性质。做法和 RepLKNet 保持一致:从 ImageNet 的验证集中采样 5000 张图片,变为 1024×1024 大小,测量每个像素对最后一层生成的特征图中心点的贡献。贡献分数进一步累积并投影到 1024×1024 矩阵。
实验结果如图6所示,可以发现从 SLaK-T 中蒸馏得到的学生模型的 ERF 大于从 Swin-T 和 CSWin-T 中蒸馏得到的学生模型的 ERF,这可能也解释了为什么前者有更好的性能,即:大 Kernel 教师帮助改善了小 Kernel 学生模型的 ERF,弥补了后者的固有缺陷。
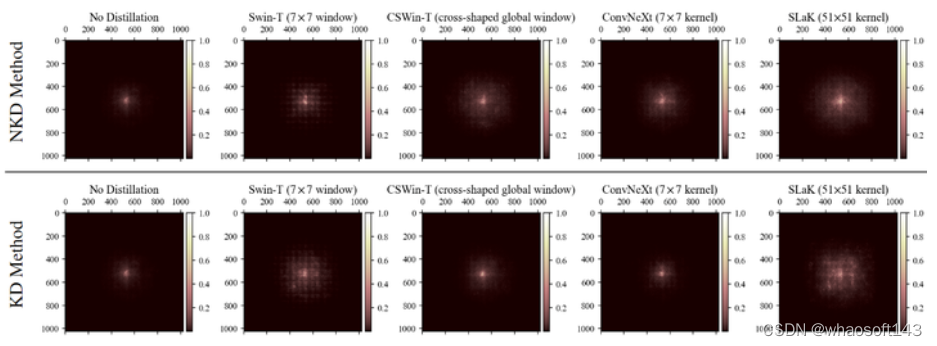 图6:大卷积核教师蒸馏对 ERF 的影响
图6:大卷积核教师蒸馏对 ERF 的影响
大卷积核教师蒸馏对 Robustness 的影响
鲁棒性也是神经网络的一项重要的性质,[8][9]表明 Transformer 和大核 ConvNet 比小核 ConvNet 具有更大的鲁棒性。本文探讨知识蒸馏能否改善小核 ConvNet 的鲁棒性。评价数据集包括 ImageNet-R, ImageNetA, ImageNet-Sketch 和 ImageNet-C (评价指标使用 Mean corruption error, mCE)。 图7:蒸馏对学生模型鲁棒性的改善
图7:蒸馏对学生模型鲁棒性的改善
结果如图7所示,从大核 ConvNet 中蒸馏得到的学生模型相比从 Transformer 中蒸馏得到的学生模型有更好的鲁棒性。鲁棒的 Transformer 教师模型不一定可以将其鲁棒性质转移给学生模型。例如,从 Swin-T 和 ViT-S 中蒸馏得到的学生 ResNet-50 模型在 ImageNet-SK/A 数据集上甚至降低了它们的 top-1 精度。而大核 ConvNet 教师模型 SLaK-T 比 ConvNeXt-T 在鲁棒性迁移方面更好。