KNN算法--K近邻算法(K-Nearest Neighbors)
如下图所示,用肿瘤的大小表示横坐标,时间表示中坐标,其中红色表示良性肿瘤,蓝色表示恶性肿瘤。 根据下图能够得到8个点的初始信息。

假如此时出现了第9个点,它的落点在第7个点和第8个点之间,怎么判断它的属性是良性还是恶性呢?
在KNN的算法中,首先确定K的值,经典的K值为3,在这里K= 3,表示寻找与第9个点最近的三个点。如下图:
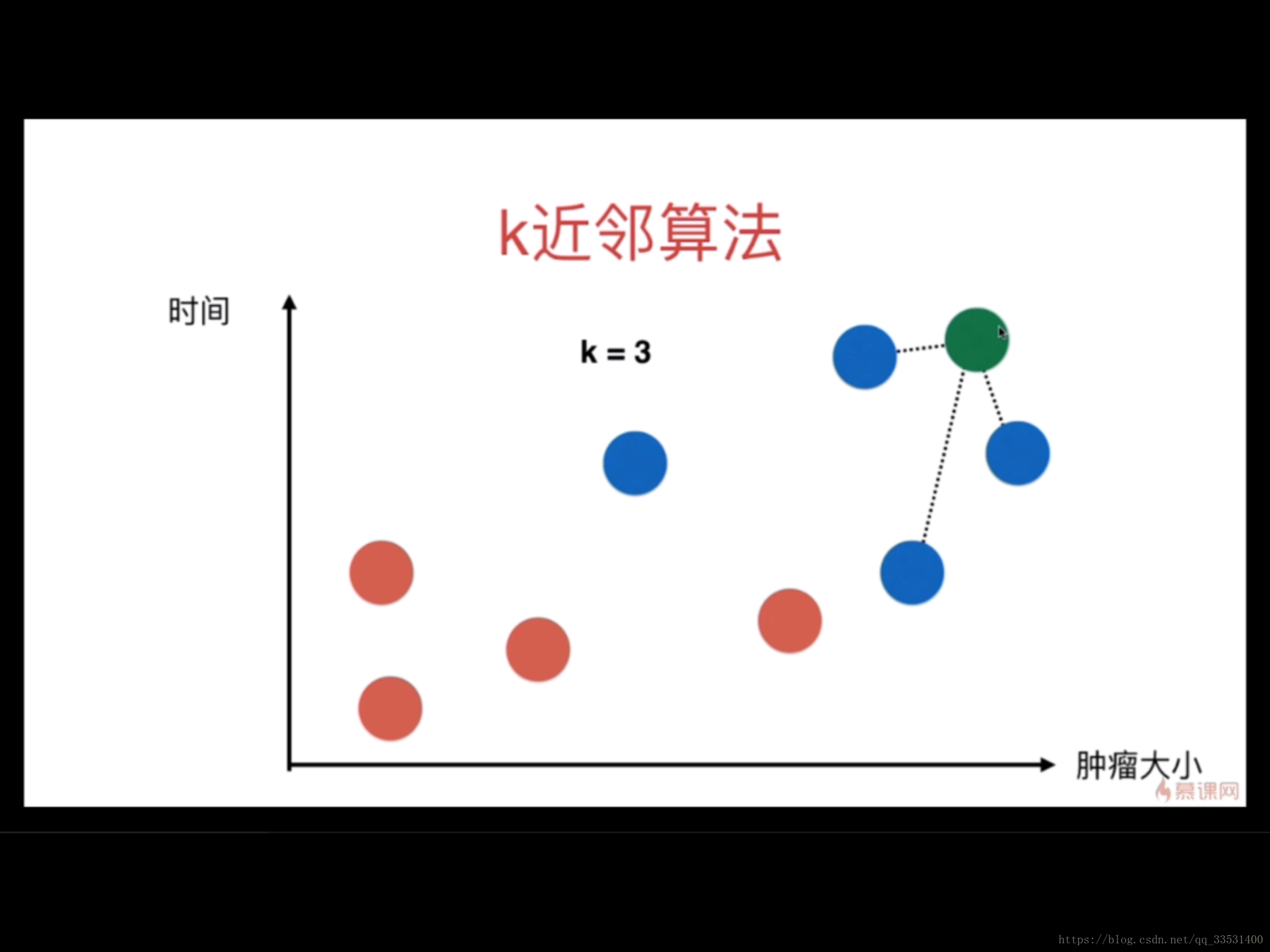
此时,在最近的三个点中,全是恶性肿瘤,没有良性肿瘤,那么第9个点的标签则定义为恶性肿瘤。
KNN算法的本质就是,两个高度相似的样本,极有可能属于同一个标签,当然比较的样本数不止两个,K的取值就是比较样本的个数,在K个样本中,哪个标签的样本数最多,那么该新样本的标签就确定了。
描述两个样本是否相似度,采用计算在特征空间中两个样本的距离来表示。
代码讲解:
1,首先准备好测试数据raw_data_X和测试标签raw_data_y,用列表表示
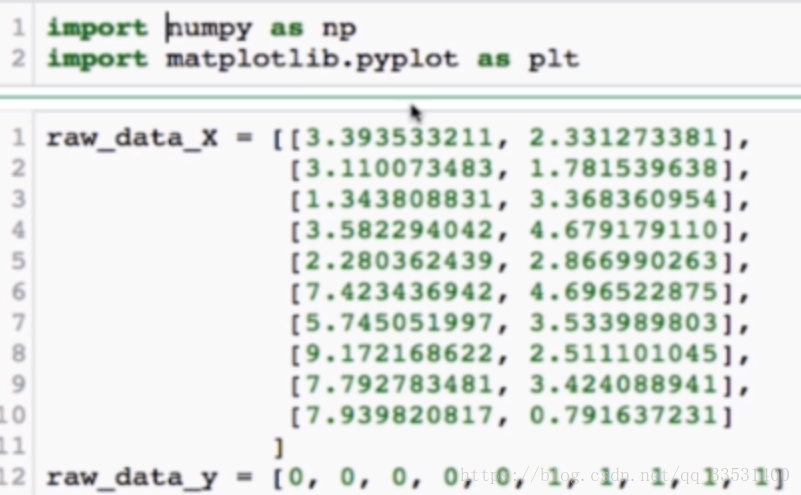
2,将列表转换成二维矩阵,X_train 表示测试数据,y_train表示测试标签
X_train = np.array(raw_data_X)
y_train = np.array(raw_data_y)3,引入待预测的数据x
x = np.array([8.09360731,3.365731514])4,计算x与特征空间每个向量的距离,即x与X_train中每个向量x_train的距离。采用欧拉距离来表示,公式如下:

分别是平面和三维空间两点的计算方式。
distance = []
for x_train in X_train:
d = sqrt((np.sum((x_train - x)**2)))
distance.append(d)
#另一种写法
distance = [sqrt(np.sum((x_train -x)** 2)) for x_train in X_train]5,将distance中的距离进行排序,按照从小到大的顺序排列。这里采用的是numpy中的argaort函数,排完序返回的是索引值。
比如[8,7,6,5,4,3,2,1,9,0],设置K的值,这里设置K= 6,那么从返回的索引排序值中,取前6个索引值表示的标签。
a = np.argaort(distance)
k = 6
topk_y = (y_train[i] for i in a[:k])
6,计算topk_y中每个标签出现的次数,那么次数出现最多的标签就是待预测数据所属标签,这里Counter的返回值是字典形式。
votes = Counter(topk_y)
predict = votes.most_common(1)[0][0]
print(predict)KNN算法是机器学习中思想极简单的分类算法。
优点:
1)简单、有效。
2)重新训练的代价较低(类别体系的变化和训练集的变化,在Web环境和电子商务应用中是很常见的)。
3)计算时间和空间线性于训练集的规模(在一些场合不算太大)。
4)由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
5)该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
缺点:
1)KNN算法是懒散学习方法(lazy learning,基本上不学习),一些积极学习的算法要快很多。
2)类别评分不是规格化的(不像概率评分)。
3)输出的可解释性不强,例如决策树的可解释性较强。
4)该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。可以采用权值的方法(和该样本距离小的邻居权值大)来改进。
5)计算量较大。目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本