
系列文章目录
YOLO V5 代码解析
一、网络结构图

二、不同网络的深度
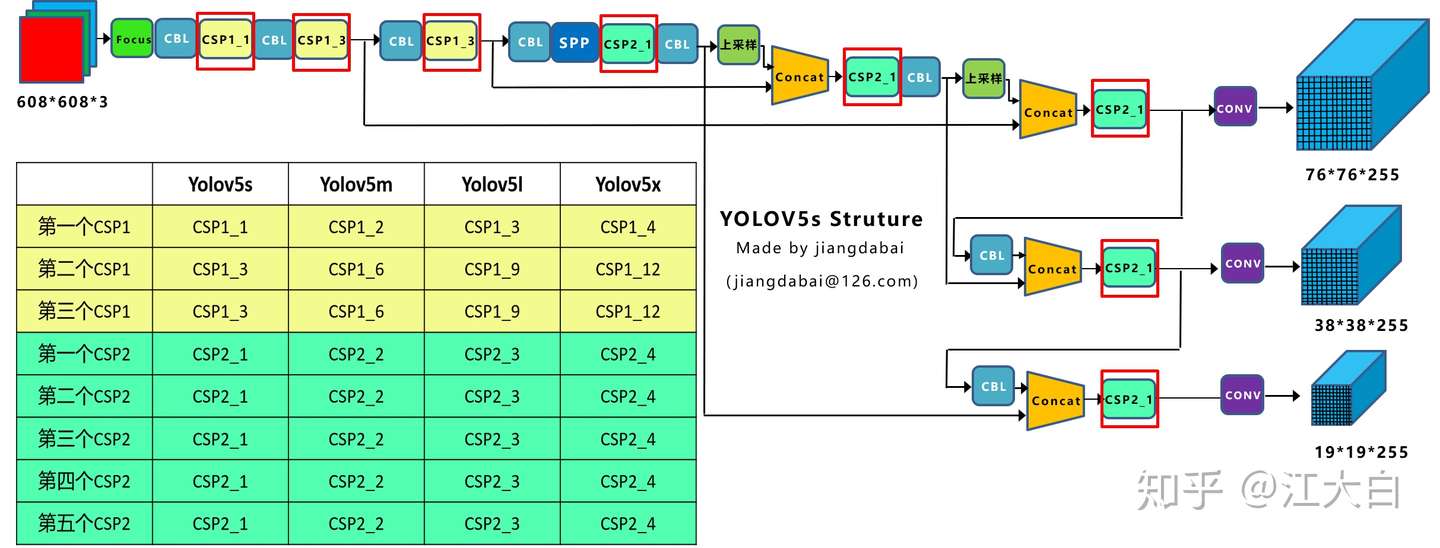
在上图中,画了两种 CSP 结构,
CSP1和CSP2,其中 CSP1 结构主要应用于 Backbone 中,CSP2 结构主要应用于 Neck 中。需要注意的是,四种网络结构中每个 CSP 结构的深度都是不同的。
- 在
yolov5s中,第一个 CSP1 中,使用了 1 个残差组件,因此是 CSP1_1;
在yolov5m中,则增加了网络的深度,在第一个 CSP1 中,使用了 2 个残差组件,因此是 CSP1_2;
在yolov5l中,同样的位置,则使用了 3 个残差组件;
在yolov5x中,使用了 4 个残差组件。
其余的第二个 CSP1 和第三个 CSP1 也是同样的原理。- 在第二种 CSP2 结构中也是同样的方式,以第一个 CSP2 结构为例:
在yolov5s组件中使用了 2*1=2 组卷积,因此是 CSP2_1;
在yolov5m中使用了 2 组;
在yolov5l中使用了 3 组;
在yolov5x中使用了 4 组。
其他的四个CSP2结构,也是同理。
Yolov5 中,网络的不断加深,也在不断增加网络特征提取和特征融合的能力。
控制深度的代码:
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
n = max(round(n * gd), 1) if n > 1 else n # depth gain
验证控制深度的有效性: 我们选择最小的 yolov5s.yaml 和中间的 yolov5l.yaml 两个网络结构,将 gd(height_multiple) 系数带入,看是否正确。

- yolov5s.yaml
其中 depth_multiple=0.33,即 gd=0.33,而 n 则由上面红色框中的信息获得。
以上面网络框图中的第一个 CSP1 为例,即上面的第一个红色框。n 等于第二个数值 3。
而 gd=0.33,带入控制深度中的计算代码,结果 n=1。因此第一个 CSP1 结构内只有 1 个残差组件,即 CSP1_1。
第二个 CSP1 结构中,n 等于第二个数值 9,而 gd=0.33,带入控制深度中的计算,结果 n=3,因此第二个 CSP1 结构中有 3 个残差组件,即 CSP1_3。
第三个 CSP1 结构也是同理,这里不多说。- yolov5l.xml
其中 depth_multiple=1,即 gd=1
和上面的计算方式相同,第一个 CSP1 结构中,n=1,带入代码中,结果 n=3,因此为CSP1_3。
下面第二个 CSP1 和第三个 CSP1 结构都是同样的原理。
三、不同网络的宽度
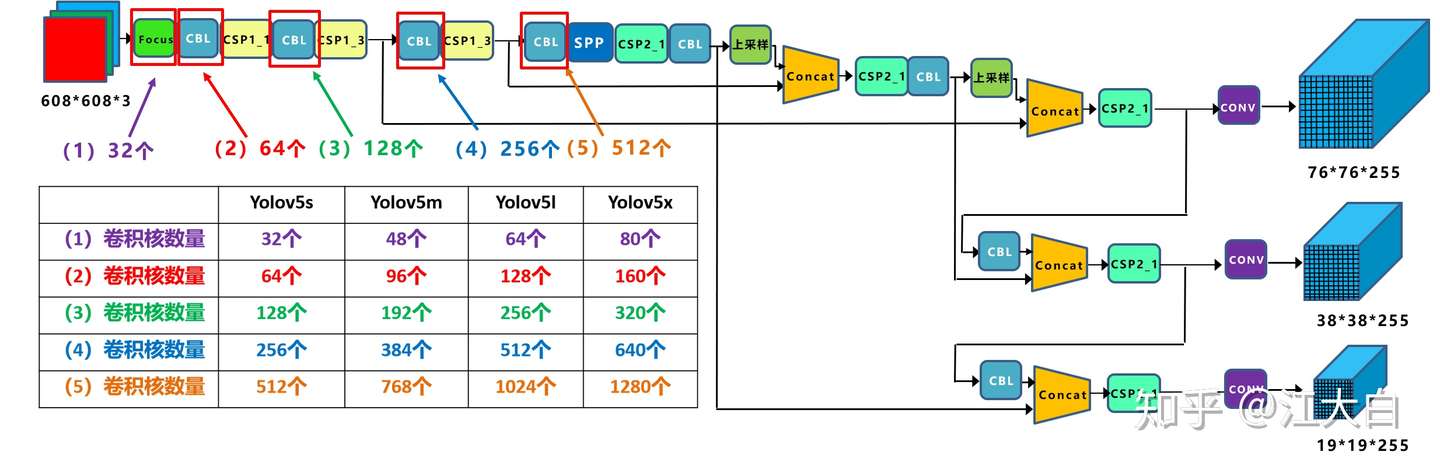
如上图中所示,四种 yolov5 结构在不同阶段的卷积核的数量都是不一样的,因此也直接影响卷积后特征图的第三维度,即厚度,表示为网络的宽度。
- 以
yolov5s结构为例,第一个 Focus 结构中,最后卷积操作时,卷积核的数量是 32 个,因此经过 Focus 结构,特征图的大小变成304*304*32。
yolov5m的 Focus 结构中的卷积操作使用了 48 个卷积核,因此 Focus 结构后的特征图变成304*304*48。
yolov5l,yolov5x也是同样的原理。- 第二个卷积操作时,
yolov5s使用了 64 个卷积核,因此得到的特征图是152*152*64。
yolov5m使用 96 个特征图,因此得到的特征图是152*152*96。
yolov5l,yolov5x也是同理。- 后面三个卷积下采样操作也是同样的原理。
- 四种不同结构的卷积核的数量不同,这也直接影响网络中,比如 CSP1,CSP2 等结构,以及各个普通卷积,卷积操作时的卷积核数量也同步在调整,影响整体网络的计算量。
- 大家最好可以将结构图和前面第一部分四个网络的特征图链接,对应查看,思路会更加清晰。
- 当然卷积核的数量越多,特征图的厚度,即宽度越宽,网络提取特征的学习能力也越强。
控制宽度的代码:
c2 = make_divisible(c2 * gw, 8) if c2 != no else c2
def make_divisible(x, divisor):
# Returns x evenly divisble by divisor
return math.ceil(x / divisor) * divisor
验证控制宽度的有效性: 我们还是选择最小的 yolov5s 和中间的 yolov5l 两个网络结构,将 width_multiple 系数带入,看是否正确。

- yolov5s.yaml
其中 width_multiple=0.5,即 gw=0.5。
以第一个卷积下采样为例,即 Focus 结构中下面的卷积操作。
按照上面Backbone的信息,我们知道 Focus 中,标准的 c2=64,而 gw=0.5,代入控制宽度的代码中的计算公式,最后的结果为 c2=32。即yolov5s的 Focus 结构中,卷积下采样操作的卷积核数量为 32 个。
再计算后面的第二个卷积下采样操作,标准 c2=128,gw=0.5,代入控制宽度的代码中的计算公式,最后的结果为 c2=64,也是正确的。- yolov5l.yaml
其中 width_multiple=1,即 gw=1,而标准的 c2=64,代入控制宽度的代码中的计算公式中,可以得到yolov5l的 Focus 结构中,卷积下采样操作的卷积核的数量为 64 个,而第二个卷积下采样的卷积核数量是 128 个。
另外的三个卷积下采样操作,以及yolov5m,yolov5x结构也是同样的计算方式,这里不过多解释。
四、yolov5s.yaml
- 这部分属于代码中的配置文件。yolov5 代码是 xxxx.yaml 使用配置文件,通过
./models/yolo.py解析文件加了一个输入构成的网络模块。- 与 config 设置的网络不同,不需要进行叠加,只需要在配置文件中对 number 进行修改即可。
4.1 yaml 介绍
- YAML文件,它不是一个标记语言。配置文件有 xml、properties 等,但 YAML 是以数据为中心,更适合做配置文件。
- YAML的语法和其他高级语言类似,并且可以简单表达清单、散列表,标量等数据形态。
- 它使用空白符号缩进和大量依赖外观的特色,特别适合用来表达或编辑数据结构、各种配置文件、倾印调试内容、文件大纲。
- 大小写敏感;缩进不允许使用 tab,只允许空格;缩进的空格数不重要,只要相同层级的元素左对齐即可;’#'表示注释;使用缩进表示层级关系。
Note: 在 yaml 文件中空格数其实也是重要的!在建立 YAML 对象时,对象键值对使用冒号结构表示
key: value,冒号后面要加一个空格。
4.2 parameters
# parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple, 宽度 设置卷积核个数
depth_multiple是用在 backbone 中的 number≠1 的情况下, 即在 Bottleneck 层使用,控制模型的深度,yolov5s 中设置为 0.33,假设 yolov5l 中有三个 Bottleneck,那 yolov5s 中就只有一个 Bottleneck。因为一般 number=1 表示的是功能背景的层,比如说下采样 Conv、Focus、SPP(空间金字塔池化)。
——————————————————————————————————————
width_multiple主要是用于设置 arguments,例如 yolov5s 设置为 0.5,Focus 就变成 [32, 3],Conv 就变成 [64, 3, 2]。以此类推,卷积核的个数都变成了设置的一半。
4.3 anchors
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
4.4 backbone
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, BottleneckCSP, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, BottleneckCSP, [1024, False]], # 9
]
Bottleneck 可以译为“瓶颈层”。
- from列参数:-1 代表是从上一层获得的输入,-2表示从上两层获得的输入(head同理)。
- number列参数:1 表示只有一个,3 表示有三个相同的模块。
- SPP、Conv、Bottleneck、BottleneckCSP 的代码可以在
./models/common.py中获取到。- [64, 3] 解析得到 [3, 32, 3] ,输入为 3(RGB),输出为 32,卷积核 k 为 3;
- [128, 3, 2] 这是固定的,128 表示输出 128 个卷积核个数。根据 [128, 3, 2] 解析得到 [32, 64, 3, 2] ,32 是输入,64 是输出(128*0.5=64),3 表示 3×3 的卷积核,2 表示步长为 2。
- 主干网是图片从大到小,深度不断加深。
- args这里的输入都省去了,因为输入都是上层的输出。为了修改过于麻烦,这里输入的获取是从
./models/yolo.py的def parse_model(md, ch)函数中解析得到的。
4.5 head
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, BottleneckCSP, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, BottleneckCSP, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, BottleneckCSP, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, BottleneckCSP, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]

五、common.py
该部分是 backbone 各个模块参数讲解。
5.1 卷积层
5.1.1 深度分离卷积层
DWConv 深度分离 (DepthWise) 卷积层,是 GConv 的极端情况,分组数量等于输入通道数量,即每个通道作为一个小组分别进行卷积,结果联结作为输出,Cin = Cout = g,没有bias项,如下图所示,Output channels 作为 DWConv 的输入,划分了输入通道数量相等的分组,通道之间完全没有信息流通。

def DWConv(c1, c2, k=1, s=1, act=True):
"""
深度分离卷积层
:param k: kernel 卷积核
:param s: stride 步长
:param act:
:return:
"""
# math.gcd() 返回的是最大公约数
return Conv(c1, c2, k, s, g=math.gcd(c1, c2), act=act)
5.1.2 标准卷积层

class Conv(nn.Module):
""" 标准卷积层: conv + BN + Leaky relu """
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):
# ch_in, ch_out, kernel, stride, padding, groups
# g = 1 表示从输入通道到输出通道的阻塞连接数为1。
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.Hardswish() if act else nn.Identity()
def forward(self, x): # 前向计算
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x): # 前向融合计算
return self.act(self.conv(x))
nn.Conv2d(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode=‘zeros’)
- in_channel: 输入数据的通道数,例 RGB 图片通道数为 3。
- out_channel: 输出数据的通道数,这个根据模型调整。
- kennel_size: 卷积核大小,可以是 int 或 tuple;kennel_size=2,意味着卷积大小(2,2),kennel_size=(2,3),意味着卷积大小 (2, 3) 即非正方形卷积。
- stride:步长,默认为 1,与 kennel_size 类似,stride=2,意味着步长上下左右扫描皆为2,stride=(2,3),左右扫描步长为 2,上下为 3。
- padding:零填充。
- groups:从输入通道到输出通道的阻塞连接数。
- bias:如果为
True,则向输出添加可学习的偏置。
5.2 标准 Bottleneck
class Bottleneck(nn.Module):
""" 标准 Bottleneck """
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5):
# ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
5.3 BottleneckCSP
这部分是几个标准 Bottleneck 的堆叠 + 几个标准卷积层。
class BottleneckCSP(nn.Module):
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
# ch_in, ch_out, number, shortcut, groups, expansion
super(BottleneckCSP, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)
self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)
self.cv4 = Conv(2 * c_, c2, 1, 1)
self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
self.act = nn.LeakyReLU(0.1, inplace=True)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
y1 = self.cv3(self.m(self.cv1(x)))
y2 = self.cv2(x)
return self.cv4(self.act(self.bn(torch.cat((y1, y2), dim=1))))
5.4 SPP
SPP 是空间金字塔池化的缩写。
class SPP(nn.Module):
# Spatial pyramid pooling layer used in YOLOv3-SPP
def __init__(self, c1, c2, k=(5, 9, 13)):
super(SPP, self).__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
torch.cat()是将两个 tensor 横着拼接在一起。
5.5 Flatten
在全局平均池化以后使用,去掉 2 个维度。
class Flatten(nn.Module):
# Use after nn.AdaptiveAvgPool2d(1) to remove last 2 dimensions
@staticmethod
def forward(x):
return x.view(x.size(0), -1) # x.size(0)是 batch 的大小
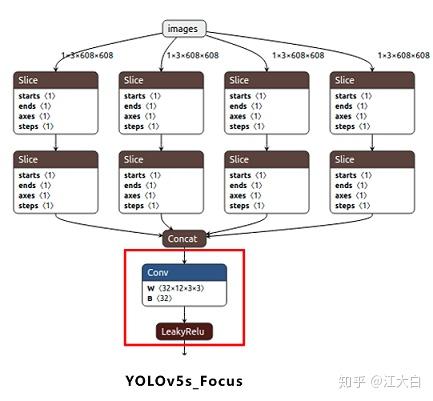
5.6 Focus
把宽度 w 和高度 h 的信息整合到 c 空间中。
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):
# ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
Note: concat 的获取如下图所示

5.7 Concat
拼接函数,将两个 tensor 进行拼接起来。
class Concat(nn.Module):
def __init__(self, dimension=1):
super(Concat, self).__init__()
self.d = dimension
def forward(self, x):
return torch.cat(x, self.d)
六、train.py
6.1 使用 torch 的 amp 接口计算混合精度训练
# 通过 torch1.6 自带的 api 设置混合精度训练
scaler = amp.GradScaler(enabled=cuda)
6.2 获取文件路径
# 如果设置进化算法则不会传入 tb_writer(则为None),设置一个 evolve 文件夹作为日志目录
log_dir = Path(tb_writer.log_dir) if tb_writer else Path(opt.logdir) / 'evolve' # logging directory
# print('log_dir: ', log_dir) # log_dir: runs/exp0
wdir = log_dir / 'weights' # weights directory 设置保存权重的路径
os.makedirs(wdir, exist_ok=True)
last = wdir / 'last.pt'
best = wdir / 'best.pt'
results_file = str(log_dir / 'results.txt') # 设置保存results的路径
6.3 获取数据路径
init_seeds(2 + rank)
with open(opt.data) as f:
data_dict = yaml.load(f, Loader=yaml.FullLoader) # data dict 加载数据配置信息
with torch_distributed_zero_first(rank): # torch_distributed_zero_first同步所有进程
# check_dataset检查数据集,如果没找到数据集则下载数据集(仅适用于项目中自带的yaml文件数据集)
check_dataset(data_dict)
# 获取训练集、测试集图片路径
train_path = data_dict['train']
test_path = data_dict['val']
# 获取类别数量和类别名字,如果设置了 opt.single_cls 则为一类
nc, names = (1, ['item']) if opt.single_cls else (int(data_dict['nc']), data_dict['names']) # number classes, names
assert len(names) == nc, '%g names found for nc=%g dataset in %s' % (len(names), nc, opt.data) # check
6.4 创建模型
# Model
pretrained = weights.endswith('.pt')
if pretrained:
# 载入预训练模型(ckpt) 及 权重(ckpt['model'])
# 加载模型,从google云盘中自动下载模型,但通常会下载失败,建议提前下载下来放进weights目录
with torch_distributed_zero_first(rank):
attempt_download(weights) # download if not found locally
ckpt = torch.load(weights, map_location=device) # load checkpoint
if hyp.get('anchors'):
ckpt['model'].yaml['anchors'] = round(hyp['anchors']) # force autoanchor
model = Model(opt.cfg or ckpt['model'].yaml, ch=3, nc=nc).to(device) # create
exclude = ['anchor'] if opt.cfg or hyp.get('anchors') else [] # exclude keys
state_dict = ckpt['model'].float().state_dict() # to FP32
state_dict = intersect_dicts(state_dict, model.state_dict(), exclude=exclude) # intersect
model.load_state_dict(state_dict, strict=False) # load
logger.info('Transferred %g/%g items from %s' % (len(state_dict), len(model.state_dict()), weights)) # report
else:
# 创建模型,ch为输入图片通道
model = Model(opt.cfg, ch=3, nc=nc).to(device) # create
七、test.py
该部分主要用于运行 train.py 时,计算每个 epoch 的 mAP。
Note: 与 train.py 相似的部分就不再阐述。
7.1 超参数设置
权重,数据,batch size,图像尺寸,使用哪张显卡,数据增强,计算 mAP。
parser = argparse.ArgumentParser(prog='test.py')
parser.add_argument('--weights', nargs='+', type=str, default='yolov5s.pt', help='model.pt path(s)')
parser.add_argument('--data', type=str, default='data/coco128.yaml', help='*.data path')
parser.add_argument('--batch-size', type=int, default=32, help='size of each images batch')
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.001, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.65, help='IOU threshold for NMS')
parser.add_argument('--save-json', action='store_true', help='save a cocoapi-compatible JSON results file')
parser.add_argument('--task', default='val', help="'val', 'test', 'study'")
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--single-cls', action='store_true', help='treat as single-class dataset')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--merge', action='store_true', help='use Merge NMS')
parser.add_argument('--verbose', action='store_true', help='report mAP by class')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
opt = parser.parse_args()
opt.save_json |= opt.data.endswith('coco.yaml')
opt.data = check_file(opt.data) # check file
print(opt)
7.2 设置任务(验证,测试,学习)
if opt.task in ['val', 'test']: # run normally
test(opt.data,
opt.weights,
opt.batch_size,
opt.img_size,
opt.conf_thres,
opt.iou_thres,
opt.save_json,
opt.single_cls,
opt.augment,
opt.verbose)
elif opt.task == 'study': # run over a range of settings and save/plot
# “study” 应该是可以修改预训练权重的操作。
for weights in ['yolov5s.pt', 'yolov5m.pt', 'yolov5l.pt', 'yolov5x.pt']:
f = 'study_%s_%s.txt' % (Path(opt.data).stem, Path(weights).stem) # filename to save to
x = list(range(320, 800, 64)) # x axis
y = [] # y axis
for i in x: # img-size
print('\nRunning %s point %s...' % (f, i))
r, _, t = test(opt.data, weights, opt.batch_size, i, opt.conf_thres, opt.iou_thres, opt.save_json)
y.append(r + t) # results and times
np.savetxt(f, y, fmt='%10.4g') # save
os.system('zip -r study.zip study_*.txt')
# utils.general.plot_study_txt(f, x) # plot
7.3 测试函数
7.3.1 初始化模型
判断模型是否存在,若不存在则训练为假,移除之前的测试结果,下载模型。
# Initialize/load model and set device
training = model is not None
if training: # called by train.py
device = next(model.parameters()).device # get model device
else: # called directly
set_logging()
device = select_device(opt.device, batch_size=batch_size)
merge, save_txt = opt.merge, opt.save_txt # use Merge NMS, save *.txt labels
if save_txt:
out = Path('inference/output')
if os.path.exists(out):
shutil.rmtree(out) # delete output folder
os.makedirs(out) # make new output folder
# Remove previous
for f in glob.glob(str(Path(save_dir) / 'test_batch*.jpg')):
os.remove(f)
# Load model
model = attempt_load(weights, map_location=device) # load FP32 model
imgsz = check_img_size(imgsz, s=model.stride.max()) # check img_size
# Half 判断设备类型并仅仅单 GPU 支持一半的精度。
half = device.type != 'cpu' # half precision only supported on CUDA
if half:
model.half()
7.3.2 获取配置文件路径和文件参数
获取配置文件 yaml 中的 nc 参数。
# Configure
model.eval()
with open(data) as f:
data = yaml.load(f, Loader=yaml.FullLoader) # model dict
check_dataset(data) # check
nc = 1 if single_cls else int(data['nc']) # number of classes
iouv = torch.linspace(0.5, 0.95, 10).to(device) # iou vector for [email protected]:0.95
niou = iouv.numel()
7.3.3 数据获取
- 测试数据的获取
- 使用NMS
- 初始化图片大小
- 获取测试或验证图片路径
- 用梯度下降运行模型、计算损失和运行 NMS
- 计算每张测试图片的数据并保存到 json 文件中
- 画出某几张 batch 图片(包括 GT 和 预测)
7.3.4 计算 map 数据
# Compute statistics
stats = [np.concatenate(x, 0) for x in zip(*stats)] # to numpy
if len(stats) and stats[0].any():
p, r, ap, f1, ap_class = ap_per_class(*stats)
p, r, ap50, ap = p[:, 0], r[:, 0], ap[:, 0], ap.mean(1) # [P, R, [email protected], [email protected]:0.95]
mp, mr, map50, map = p.mean(), r.mean(), ap50.mean(), ap.mean()
nt = np.bincount(stats[3].astype(np.int64), minlength=nc) # number of targets per class
else:
nt = torch.zeros(1)
7.3.5 打印结果(图片,速度),保存结果至 json,并返回结果
# Print results
pf = '%20s' + '%12.3g' * 6 # print format
print(pf % ('all', seen, nt.sum(), mp, mr, map50, map))
# Print results per class
if verbose and nc > 1 and len(stats):
for i, c in enumerate(ap_class):
print(pf % (names[c], seen, nt[c], p[i], r[i], ap50[i], ap[i]))
# Print speeds
t = tuple(x / seen * 1E3 for x in (t0, t1, t0 + t1)) + (imgsz, imgsz, batch_size) # tuple
if not training:
print('Speed: %.1f/%.1f/%.1f ms inference/NMS/total per %gx%g images at batch-size %g' % t)
# Save JSON
if save_json and len(jdict):
f = 'detections_val2017_%s_results.json' % (weights.split(os.sep)[-1].replace('.pt', '') if isinstance(weights, str) else '') # filename
print('\nCOCO mAP with pycocotools... saving %s...' % f)
with open(f, 'w') as file:
json.dump(jdict, file)
try: # https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocoEvalDemo.ipynb
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
imgIds = [int(Path(x).stem) for x in dataloader.dataset.img_files]
cocoGt = COCO(glob.glob('../coco/annotations/instances_val*.json')[0]) # initialize COCO ground truth api
cocoDt = cocoGt.loadRes(f) # initialize COCO pred api
cocoEval = COCOeval(cocoGt, cocoDt, 'bbox')
cocoEval.params.imgIds = imgIds # images IDs to evaluate
cocoEval.evaluate()
cocoEval.accumulate()
cocoEval.summarize()
map, map50 = cocoEval.stats[:2] # update results ([email protected]:0.95, [email protected])
except Exception as e:
print('ERROR: pycocotools unable to run: %s' % e
# Return results
model.float() # for training
maps = np.zeros(nc) + map
for i, c in enumerate(ap_class):
maps[c] = ap[i]
return (mp, mr, map50, map, *(loss.cpu() / len(dataloader)).tolist()), maps, t