文章目录
一、算法的重要性
- 算法工程师
- 锻炼代码思维,更高效写代码
- 应聘面试(笔试/机试)
二、算法(Algorithm)
概念:一种设计过程,解决问题的办法。
Niklaus Wirth:“程序=数据结构+算法”
算法需要有输入和输出

1.时间复杂度
1.1引入&问题分析
 显然是第一个运行快!
显然是第一个运行快!
类⽐⽣活中的⼀些事件,估计时间:
眨⼀下眼 =》一瞬间
⼝算“29+68” =》几秒
烧⼀壶⽔ =》几分钟
睡⼀觉 =》 几个小时
完成⼀个项⽬ =》几天/几星期/几个月
⻜船从地球⻜出太阳系 = 几年
时间复杂度是用来评估算法运行效率的一个式子。
以python为例
print('hello world')
这条语句的时间复杂度记为:O(1)
其中1是一个单位的意思,我们约定以打印语句、加减乘除、赋值等简单语句所浪费的时间为一个单位。
for i in range(n):
print('hello world')
那么这段代码时间复杂度为O(n)因为我们执行了n次“1” ==》n*1=n
类似的
for i in range(n):
for j in range(n):
print('hello world')
时间复杂度记为O(n²)
注意:
这里的一个单位并不是一个确切的概念,相对于无穷多次重复的过程,有限执行的简单语句(打印语句、加减乘除、赋值)仍然可以看做是一个单位。
a = 2
print('hello world')
c = 4 + a
这段程序的时间复杂度仍然为O(1)而非O(3)
同样的对于
for i in range(n):
print('Hello World’)
for j in range(n):
print('Hello World')
时间复杂度为:O(n²)而非O(n*(n+1))即为O(n²+n)
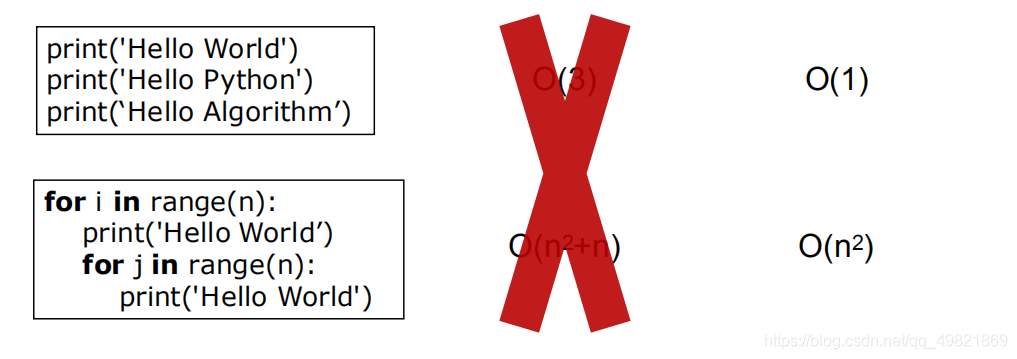
对于如下问题,我们称之为折半问题
n = 64
while n > 1:
print(n)
n = n // 2
#输出
#64
#32
#16
#8
#4
#2
时间复杂度如何计算?
解:设简单语句执行的次数(单位)为n
则:2**n=64 ==》 n = log2 64 =6
时间复杂度:O(n) = O(log2 64) = O(log 64)
当算法过程出现循环折半的时候,复杂度式子中会出现logn。
1.2时间复杂度干货小结
》时间复杂度是⽤来估计算法运⾏时间的⼀个式⼦(单位)。
》⼀般来说,时间复杂度⾼的算法⽐复杂度低的算法慢。
一般:因为程序运行时间长短还会受限于机器的性能这个物理因素。
》常⻅的时间复杂度(按效率排序)
》O(1)<O(logn)<O(n)<O(nlogn)<O(n2)<O(n2logn)<O(n3)
》复杂问题的时间复杂度
》O(n!) O(2n) O(nn)
1.3如何简单快速判断算法复杂度(适应于绝大多数简单情况)
-
确定问题规模n
-
循环减半过程—》logn
-
k层关于n的循环—》n的k次方
-
复杂情况:依据算法执行过程判断
2.空间复杂度
空间复杂度:用来评估算法内存占用大小的式子
空间复杂度的表达方式和时间复杂度完全一样
》算法使⽤了⼏个变量:O(1)
》算法使⽤了⻓度为n的⼀维列表:O(n)
》算法使⽤了m⾏n列的⼆维列表:O(mn)
注意:
多数情况下,“空间换时间”,时间的价值要比空间大。
三、递归算法
1.递归特点
递归本质上是一种循环,理论上所有递归能干的事情循环都能干,但有些情况下递归比循环更加容易实现功能。
特点:
1.调用自身
2.结束条件
def func1(x):
print(x)
func(x-1)
这不是递归,而是死循环,没有结束条件
def func2(x):
if x>1:
print(x)
func(x-1)
这是递归
同样的
def func3(x):
if x>0:
print(x)
func2(x+1)
这不是递归
def func4(x):
if x>0:
func4(x-1)
print(x)
这是递归
我以窄条表示打印,大方框表示函数来更好的展示func2的运行。假设x为3,依次打印3、2、1

而func4(3)依次打印1、2、3
1.2递归实例:汉诺塔问题
神话背景:(其实是一个数学家瞎扯的,骗你来学汉诺塔)
⼤梵天创造世界的时候做了三根⾦刚⽯柱⼦,在⼀根
柱⼦上从下往上按照⼤⼩顺序摞着64⽚⻩⾦圆盘。
⼤梵天命令婆罗⻔把圆盘从下⾯开始按⼤⼩顺序重新
摆放在另⼀根柱⼦上。
在⼩圆盘上不能放⼤圆盘,在三根柱⼦之间⼀次只能
移动⼀个圆盘。
64根柱⼦移动完毕之⽇,就是世界毁灭之时。

我们假设盘子个数为n:
》当n=0:啥也不用干,问题结束
》当n=1:A=》C
》当n=2:小盘子=》B,大盘子=》C,小盘子=》B
》当n=3:从小到大的盘子分别标记为1,2,3
》则:1=》C,2=》B,1=》B,3=》C,1=》A,2=》C,1=》C
…………………………
》当n=n时:我们可以理解为有n-1个小盘子和1个大盘子
》1.把n-1个小盘子经过C放到B
》2.把那个大盘子放到C
》3.把n-1个小盘子经过A放到C
完成任务。
在这个过程中,我们简化了问题的规模,其实这是递归的核心,我之前学递归的时候,总是把关注点放在大规模和小规模问题之间发生了什么这个点上,想也想不清……现在感觉只需要关注怎么把问题规模缩小的和递归终止条件即可。
代码实现:
def hanoi(n,a,b,c):
#这里的n是盘子数,a是盘子一开始在的位置,c是终点位置,b是过度位置
if n>0: #n=0任务完成
hanoi(n-1,a,c,b)
print(f'{a}=>{c}') #模拟最后一个盘子从a到c
hanoi(n-1,b,a,c)
结果:
a=>c
a=>b
c=>b
a=>c
b=>a
b=>c
a=>c
我们可以和我们之前人工模拟的过程对比一下。
1.3有趣的汉诺塔
》汉诺塔移动次数的递推式:h(x)=2h(x-1)+1
》h(64)=18446744073709551615
》假设婆罗⻔每秒钟搬⼀个盘⼦,则总共需要5800亿年
四、查找算法
查找:在一些数据元素中,通过一定的方法找出与给定关键字相同的数据的元素的过程。
列表查找,也叫线性表查找:从列表中查找指定元素
》》输入:列表、待查找元素
》》输出:找到:元素下标 未找到:None/-1
内置列表查找函数:index(),其作用就是上面所描述的,区别就是元素没找到会抛出异常
lis = [1,2,3,4,5]
print(lis.index(1))
print(lis.index(6))
结果
0 Traceback (most recent call last): File
“C:/Users/LENOVO/Desktop/算法.py”, line 5, in
print(lis.index(6)) ValueError: 6 is not in list
1.顺序查找
顺序查找:也叫线性查找,从列表第一个元素开始,顺序进行查找,直到找到元素或者搜索到列表末尾为止。
时间复杂度:O(n),n为列表长度,这里的列表我们特指一维列表
> def linear_search(data_set,value):
for i in range(len(data_set)):
if data_set[i] == value:
return i
结果:
2.二分查找/折半查找
二分查找:又叫折半查找,从有序列表的初始候选区开始,通过对待查找的值与候选区中间值比较,可以使得候选区每次选都减少一半。
举个例子:
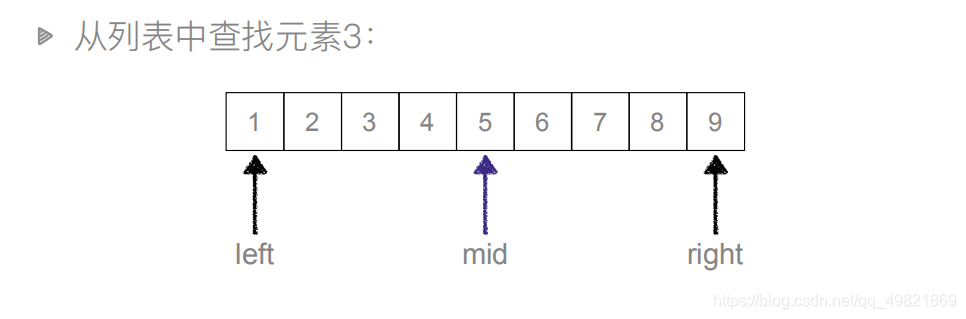 二分查找是这样执行的:
二分查找是这样执行的:
第一次查找:left=0,right=8,这里的left、right是元素的下标
mid = 4,中间索引对应的值(中间值)是5,5>3
第二次查找:由于上次5>3和列表是从小到大的顺序,我们可以得出要查找的值在mid左侧,此时right=mid-1=4-1=3,left=0不变,mid=\(left+right)// 2 (下标是整数值)mid=1,中间值为2,2<3
第三次查找:我们根据第二次查找结果可以判断出待查找的值在mid右边,则left=mid+1=1+1=2,right=3不变,mid=(2+3)// 2 = 2,所对应的值为3,查找结束。
值得注意,如果left>right 即中间区没有任何值,说明该元素不在所查找的列表里,查找结束。
python实现:
lis = [1,2,3,4]
def bin_search(data_set,value):
left,right = 0,len(data_set)-1
while left <= right:
mid = (left+right)//2
if data_set[mid]==value:
return mid
elif data_set[mid]>value:
high = mid-1
else:
left=mid+1
return -1
res =bin_search(lis,6)
print(res)
结果:
时间复杂度:O(logn) n为一维列表长度
3.比较
通常情况下,二分查找要比线性查找要快,但是由于二分查找的前提是列表元素按照顺序排列,有个一个排序的过程,如果列表元素很多,排序需要花费大量的时间。
所以如何选择这两种查找方法还需要考虑具体情况。
多次用到查找,可以考虑排序+二分查找
python中index()的实现是顺序查找
ps:python自带排序方法
1.sort(),

2.sorted()
lis = [1,2,3,4,5]
res = sorted(lis,key=lambda x:-x)
print(res)
结果
