注:非Vmware安装
全篇都在root权限下运行
1.修改主机名
1.查看主机名:hostname
2.修改主机名:hostnamectl set-hostname master
或者修改:
/etc/hostname
3.将主机名写入/etc/hosts
IP地址 主机名
2.关闭防火墙
1.查看防火墙状态:firewall-cmd --state | system status firewalld
2.关闭防火墙:system stop firewalld
3.ssh
主节点生成密钥:ssh-keygen -t rsa
3次回车
然后将密钥拷贝到其他节点
ssh-copy-id master
ssh-copy-id slave
4.安装jdk
1.下载jdk压缩包
2.利用shell软件拖到主机上
3.解压压缩包:tar -zxvf 版本号 -C 指定文件夹
4.修改/etc/profile文件,添加:
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_221
export PATH=$PATH:$JAVA_HOME/bin
注意是自己的版本,自己的安装路径
5.让修改的文件生效:source /etc/profile
6.测试是否安装成功:java -version
1-6所有节点所有节点都要
5.安装Hadoop
1.下载hadoop压缩包,上传到主机,解压压缩包
2.同样修改/etc/profile文件,添加:
扫描二维码关注公众号,回复:
12199652 查看本文章

#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.9.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
3.让修改的文件生效:source /etc/profile
4.新建hdfs相关目录:
mkdir /home/hdfs
mkdir /home/hdfs/tmp
mkdir /home/hdfs/name
mkdir /home/hdfs/data
1-4步骤所有节点都要执行
5.接下来修改hadoop配置:
文件名:hadoop_env.sh / yarn-env.sh
路径:hadoop-2.9.2/etc/hadoop/(下同)
export JAVA_HOME=/usr/java/latest
文件名:core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hdfs/tmp</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
文件名:hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/home/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hdfs/data</value>
</property>
</configuration>
文件名:mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
文件名:yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
文件名:slaves
将localhost去掉
添加集群主机:
master
slave1
slave2
将修改了的文件全部发送到从节点:
scp 路径+文件名 @从节点主机名:路径
eg: scp /opt/module/hadoop-2.9.2/etc/hadoop/yarn-site.xml @slave1:/opt/mudule-2.9.2/etc/hadoop/
6.启动Hadoop
1.先格式化data:hadoop namenode -format
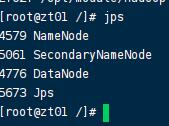
2.start-all.sh
3.输入命令jpd查看: