版权声明:本文为博主原创文章,欢迎转载。 https://blog.csdn.net/u011095110/article/details/83791734
本文介绍搭建一个Namenode两个DataNode的Hadoop全分布式集群的全部步骤及方法。具体环境如下:
一、环境准备
- 3个Centos7虚拟机或者3个在一个局域网内的实际Centos7机器,机器上已安装JDK1.8,至于不会安装Centos7或者JDK1.8的同学可以自行网上百度教程,不为此文重点;
- 关闭禁用防火墙,主要是方便hadoop集群内部相互之间可以顺利访问,方便于web端通过ip+端口访问管理界面;
[root@slave1 ~]# systemctl stop firewall [root@slave1 ~]# firewall-cmd --state not running - 修改hostname和hosts文件主节点namenode
#ip地址请替换成自己对应的地址hostnamectl set-hostname master.hadoop #两个从节点分别为slave1.hadoop和slave2.hadoop vim /etc/hosts
172.16.16.15 master.hadoop
172.16.16.12 slave1.hadoop
172.16.16.13 slave2.hadoop
| IP地址 | Hostname | 描述 |
|---|---|---|
| 172.16.16.15 | master.hadoop | NameNode Master节点 |
| 172.16.16.12 | slave1.hadoop | DataNode slave节点1 |
| 172.16.16.15 | slave2.hadoop | DataNode slave节点2 |
配置完之后reboot重启系统,然后用hostnamectl查看是否hostname已经生效
```
[root@slave1 ~]# hostnamectl
Static hostname: slave1.hadoop
Icon name: computer-desktop
Chassis: desktop
Machine ID: 76547338655241a2b56abe659fe05dc1
Boot ID: 2d0f564b16f24bd7959ff4608d790223
Operating System: CentOS Linux 7 (Core)
CPE OS Name: cpe:/o:centos:centos:7
Kernel: Linux 3.10.0-862.11.6.el7.x86_64
Architecture: x86-64
```
二、免密码登录
1、在master机器上输入 ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa 创建一个无密码的公钥,-t是类型的意思,dsa是生成的密钥类型,-P是密码,’’表示无密码,-f后是秘钥生成后保存的位置
2、在master机器上输入 cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys 将公钥id_dsa.pub添加进keys,这样就可以实现无密登录ssh
3、在master机器上输入 ssh master 测试免密码登陆
4、在slave1.hadoop主机上执行 mkdir ~/.ssh
5、在slave2.hadoop主机上执行 mkdir ~/.ssh
6、在master机器上输入 scp ~/.ssh/authorized_keys [email protected]:~/.ssh/authorized_keys 将主节点的公钥信息导入slave1.hadoop节点,导入时要输入一下slave1.hadoop机器的登陆密码
7、在master机器上输入 scp ~/.ssh/authorized_keys [email protected]:~/.ssh/authorized_keys 将主节点的公钥信息导入slave2.hadoop节点,导入时要输入一下slave2.hadoop机器的登陆密码
8、在三台机器上分别执行 chmod 600 ~/.ssh/authorized_keys 赋予密钥文件权限
9、在master节点上分别输入 ssh slave1.hadoop和 ssh slave2.hadoop测试是否配置ssh成功
三、下载解压Hadoop
master机器创建Hadoop根目录,下载,解压Hadoop安装包
mkdir /hadoop
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.9.0/hadoop-2.9.0-src.tar.gz
tar -zxvf hadoop-2.9.0-src.tar.gz
四、配置hadoop master节点
可先配置master.hadoop机器,然后通过scp的方式复制到两个从节点
- core-site.xml在中添加
vim /hadoop/hadoop-2.9.0/etc/hadoop/core-site.xml<property> <name>fs.default.name</name> <value>hdfs://master.hadoop:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/tmp</value> </property> <property> <name>io.file.buffer.size</name> <value>131702</value> </property> - hdfs-site.xml
vim /hadoop/hadoop-2.9.0/etc/hadoop/hdfs-site.xml<configuration> <property> <name>dfs.namenode.name.dir</name> <value>file:///home/hadoop/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///home/hadoop/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>master.hadoop:50090</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration> - mapred-site.xml
模板文件copy一份自己的要修改的mapred-site.xml
cp /hadoop/hadoop-2.9.0/etc/hadoop/mapred-site.xml.template /home/hadoop/hadoop- 2.9.0/etc/hadoop/mapred-site.xml
vim /home/hadoop/hadoop-2.9.0/etc/hadoop/mapred-site.xml
```
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>master.hadoop:50030</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master.hadoop:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master.hadoop:19888</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>http://master.hadoop:9001</value>
</property>
</configuration>
```
- yarn-site.xml
vim /home/hadoop/hadoop-2.9.0/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property> <name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master.hadoop:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master.hadoop:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master.hadoop:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master.hadoop:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master.hadoop:8088</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master.hadoop</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
</configuration>
五、配置JAVA_HOME&slaves
- 配置JAVA_HOME
配置/hadoop/hadoop-2.9.0/etc/hadoop目录下hadoop.env.sh、yarn-env.sh的JAVA_HOME
export JAVA_HOME=/usr/local/jdk1.8.0_181 #此处为你的jdk目录
- 配置slaves
配置/hadoop/hadoop-2.9.0/etc/hadoop目录下的slaves,删除默认的localhost,添加2个slave节点
slave1.hadoop
slave2.hadoop
六、Hadoop复制
将master服务器上配置好的Hadoop复制到各个节点对应位置上,通过scp传送
scp -r /hadoop 172.16.16.12:/
scp -r /hadoop 172.16.16.13:/
七、启动hadoop
在master节点启动hadoop服务,各个从节点会自动启动,进入/home/hadoop/hadoop-2.9.0/sbin/目录,hadoop的启动和停止都在master上进行
hdfs namenode -format
[root@master sbin]# ./start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master.hadoop]
master.hadoop: starting namenode, logging to /hadoop/hadoop-2.9.0/logs/hadoop-root-namenode-master.hadoop.out
slave1.hadoop: starting datanode, logging to /hadoop/hadoop-2.9.0/logs/hadoop-root-datanode-slave1.hadoop.out
slave2.hadoop: starting datanode, logging to /hadoop/hadoop-2.9.0/logs/hadoop-root-datanode-slave2.hadoop.out
Starting secondary namenodes [master.hadoop]
master.hadoop: starting secondarynamenode, logging to /hadoop/hadoop-2.9.0/logs/hadoop-root-secondarynamenode-master.hadoop.out
starting yarn daemons
starting resourcemanager, logging to /hadoop/hadoop-2.9.0/logs/yarn-root-resourcemanager-master.hadoop.out
slave1.hadoop: starting nodemanager, logging to /hadoop/hadoop-2.9.0/logs/yarn-root-nodemanager-slave1.hadoop.out
slave2.hadoop: starting nodemanager, logging to /hadoop/hadoop-2.9.0/logs/yarn-root-nodemanager-slave2.hadoop.out
[root@master sbin]# ./stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
Stopping namenodes on [master.hadoop]
master.hadoop: stopping namenode
slave1.hadoop: stopping datanode
slave2.hadoop: stopping datanode
Stopping secondary namenodes [master.hadoop]
master.hadoop: stopping secondarynamenode
stopping yarn daemons
stopping resourcemanager
slave1.hadoop: stopping nodemanager
slave2.hadoop: stopping nodemanager
slave1.hadoop: nodemanager did not stop gracefully after 5 seconds: killing with kill -9
slave2.hadoop: nodemanager did not stop gracefully after 5 seconds: killing with kill -9
no proxyserver to stop
八、jps查看启动情况
在master和slave节点查看是否成功启动
[root@master sbin]# jps
24340 SecondaryNameNode
24837 Jps
24502 ResourceManager
24124 NameNode
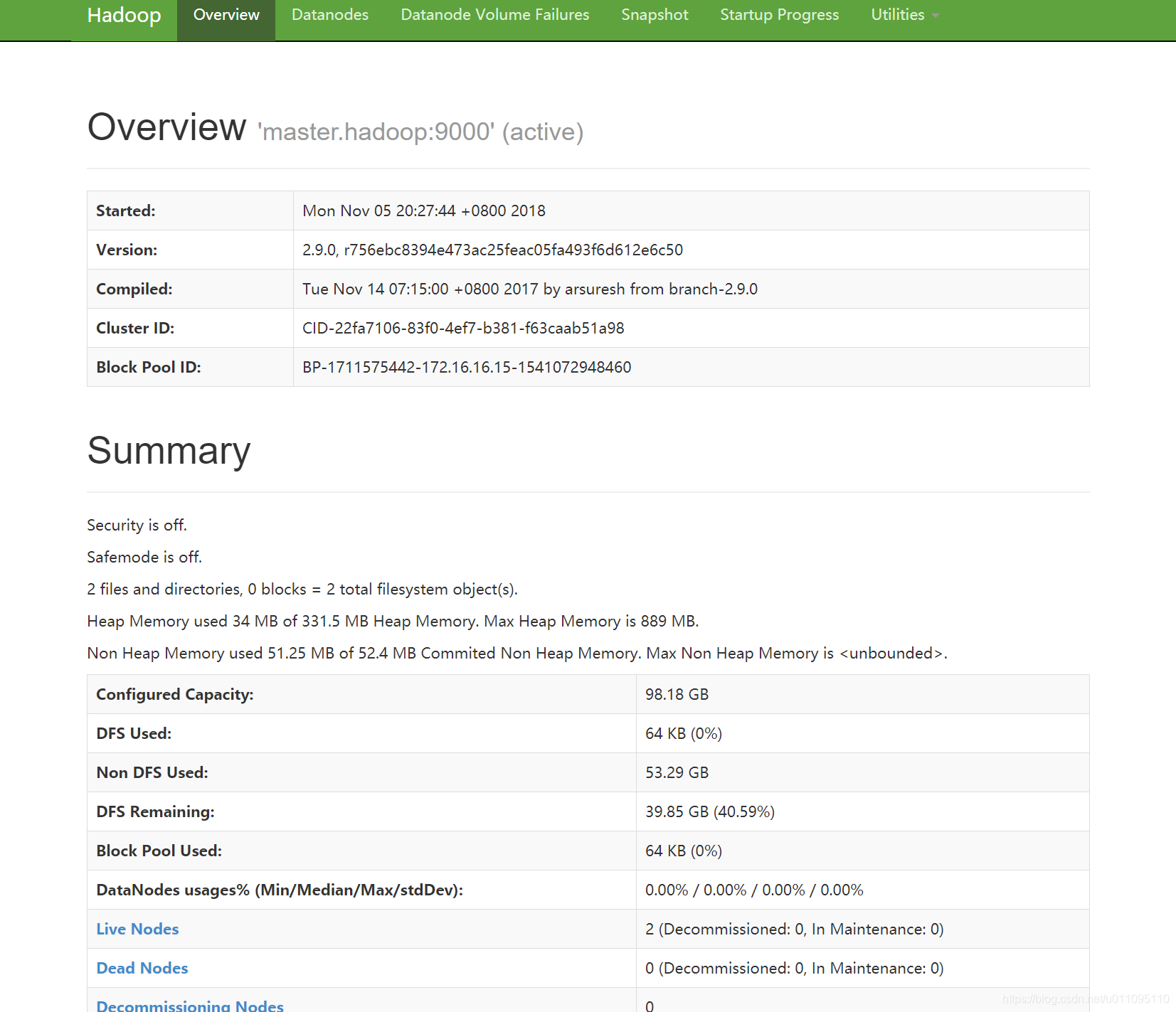
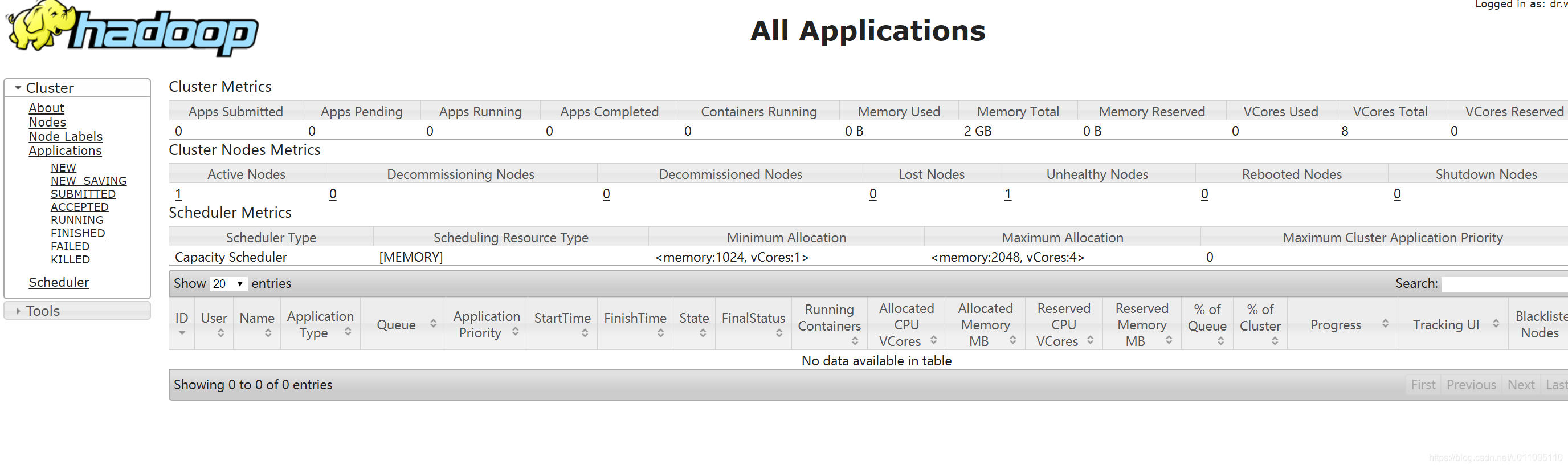
九、web查看集群信息