目录
Centos7下Hadoop完全分布式安装
- 电脑系统:macOS 10.15.4
- 虚拟机软件:Parallels Desktop14
- Hadoop各节点节点操作系统:CentOS 7
- JDK版本:jdk1.8.0_162
- Hadoop版本:hadoop-2.7.7
第一步:安装文件
准备好工具,虚拟机,3个centos,jdk安装包,Hadoop安装包
先在centos中的/opt/目录下新建一个文件夹Hadoop
然后上传Hadoop 和jdk
上传方式:
scp 本机的文件绝对路径 [email protected]:/opt/Hadoop
解压文件:
tar -zxvf jdk-8u162-linux-x64.tar.gz
tar -zxvf hadoop-2.7.7.tar.gz
创建软连接:
ln -s hadoop-2.7.7 hadoop
ln -s jdk1.8.0_162 jdk
第二步:免密登录配置
(1)vim 的安装
如果centos没有安装好vim,需要安装vim
yum install vim -y
(2)host配置
开启虚拟机,host配置文件在根目录下的 etc 文件夹下,给三台虚拟机均进行配置。
注意,下面的host配置,一定要根据自己的主机名和ip进行配置,三台主机的配置均一样。在根目录下输入
sudo vim /etc/hosts
在每一台文件末尾添加以下内容
10.211.55.59 node1
10.211.55.60 node2
10.211.55.61 node3
(3)关闭防火墙
每一台服务器都要关闭防火强

- 查看防火墙状态
firewall-cmd --state
- 停止防火墙
systemctl stop firewalld.service
- 禁止防火墙开机启动
systemctl disable firewalld.service
- 关闭selinux
sudo vim /etc/selinux/config
注释掉 SELINUX=enforcing ,添加如下内容:
SELINUX=disabled
也可以直接将enforcing修改为disabled。
(4)实现免密登陆
配置每一台服务器本身公钥和免密:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
将公钥追加到”authorized_keys”文件
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
免密登录公钥分发
node1 分发给:node1、node2、node3
ssh-copy-id -i ~/.ssh/id_dsa.pub node1
ssh-copy-id -i ~/.ssh/id_dsa.pub node2
ssh-copy-id -i ~/.ssh/id_dsa.pub node3
node2 分发给:node1、node2、node3
ssh-copy-id -i ~/.ssh/id_dsa.pub node1
ssh-copy-id -i ~/.ssh/id_dsa.pub node2
ssh-copy-id -i ~/.ssh/id_dsa.pub node3
node3 分发给:node1、node2、node3
ssh-copy-id -i ~/.ssh/id_dsa.pub node1
ssh-copy-id -i ~/.ssh/id_dsa.pub node2
ssh-copy-id -i ~/.ssh/id_dsa.pub node3
免密登录配置,已经完成,可以进行测试
验证免密码登陆:在node1主机中输入以下命令验证
ssh node1
ssh node2
ssh node3
(5)安装NTP时间同步服务
三台虚拟机都要安装,需要进入root权限下:
sudo -i
- 安装ntp
yum install -y ntp
- 设置NTP服务开机启动
chkconfig ntpd on
- 查看ntp进程是否启动
ps aux | grep ntp
显示:
root 12650 0.0 0.0 112728 968 pts/0 S+ 11:56 0:00 grep --color=auto ntp
第三步:配置环境变量
配置jdk、Hadoop环境变量:
sudo vim ~/.bashrc
在文件末尾添加如下代码
export JAVA_HOME=/opt/Hadoop/jdk1.8.0_162
export CLASSPATH=${JAVA_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
export HADOOP_HOME=/opt/Hadoop/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
上面这个地方根据自己的实际要求填写
保存并退出
是设置生效:
source ~/.bashrc
检验java -version和whereis hdfs
能输出Java版本号的即为配置环境变量成功
第四步:设置Hadoop配置文件
在node1进行文件配置
进入hadoop目录
cd /opt/Hadoop/hadoop-2.7.7/etc/hadoop
(1)配置hadoop-env.sh文件
设置hadoop-env.sh文件
vim hadoop-env.sh
找到export JAVA_HOME,修改如下:
export JAVE_HOME=/opt/Hadoop/jdk1.8.0_162
(2)配置core-site.xml文件
vim core-site.xml
修改core-site.xml文件
<configuration>cd
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/Hadoop/hadoop-2.7.7/tmp</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>caizhengjie</value>
</property>
</configuration>
(3)配置hdfs-site.xml文件
vim hdfs-site.xml
修改hdfs-site.xml文件
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
(4)配置mapred-site.xml文件
将 mapred-site.xml.template 复制为文件名是 mapred-site.xml 的文件
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
修改mapred-site.xml文件
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
如果在测试mapreduce出现问题,请见这篇文章
https://blog.csdn.net/weixin_45366499/article/details/103752447
(5)配置yarn-site.xml文件
vim yarn-site.xml
修改yarn-site.xml文件
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
(6)修改 slaves 文件
这是分配datanode,如果想配置三台datanode则需要在slaves文件里添加三台主机名
将原有的内容删去,加以上内容:
node1
node2
node3
或者
node2
node3
这里会出现一个问题:当重新启动服务的时候,会出现“卡住不动的情况”,这种情况千万不要ctrl+c给停止掉,这是让你输入node1的密码,因为字比较小我经常会忽略掉,以为是个报错,其实不是报错,是想让你输入密码而已!这个坑我卡了三天!
第五步:分发配置到 node2、node3 虚拟机
- 方案一:如果第一步上传文件只上传在node1中,node2,node3没有上传,则可以将整个Hadoop文件传给node2,node3。但是,上传完之后需要在node2,node3中配置环境变量。
scp -r Hadoop caizhengjie@node2:/opt/
scp -r Hadoop caizhengjie@node3:/opt/
- 方案二:如果在node2,node3中均已上传文件并配置好环境变量,则只需要将 hadoop/etc目录下的 hadoop 文件夹分发给另外两台虚拟机
scp -r hadoop caizhengjie@node2:/opt/Hadoop/hadoop-2.7.7/etc/hadoop
scp -r hadoop caizhengjie@node3:/opt/Hadoop/hadoop-2.7.7/etc/hadoop
第六步:运行Hadoop及测试
在运行初次运行hadoop之前,需要在 node1 格式化 hdfs
hdfs namenode -format
- 启动HDFS:
start-dfs.sh - 启动YARN:
start-yarn.sh - 启动all:
start-all.sh - 关闭Hadoop服务:stop-all.sh
检验Hadoop进程:jps
node1中出现:
[caizhengjie@node1 ~]$ jps
2166 NameNode
2523 ResourceManager
2363 SecondaryNameNode
2782 Jps
node2中出现:
[caizhengjie@node2 ~]$ jps
2370 Jps
2133 DataNode
2247 NodeManager
node3中出现:
[caizhengjie@node3 ~]$ jps
2144 DataNode
2257 NodeManager
2403 Jps
访问网页:
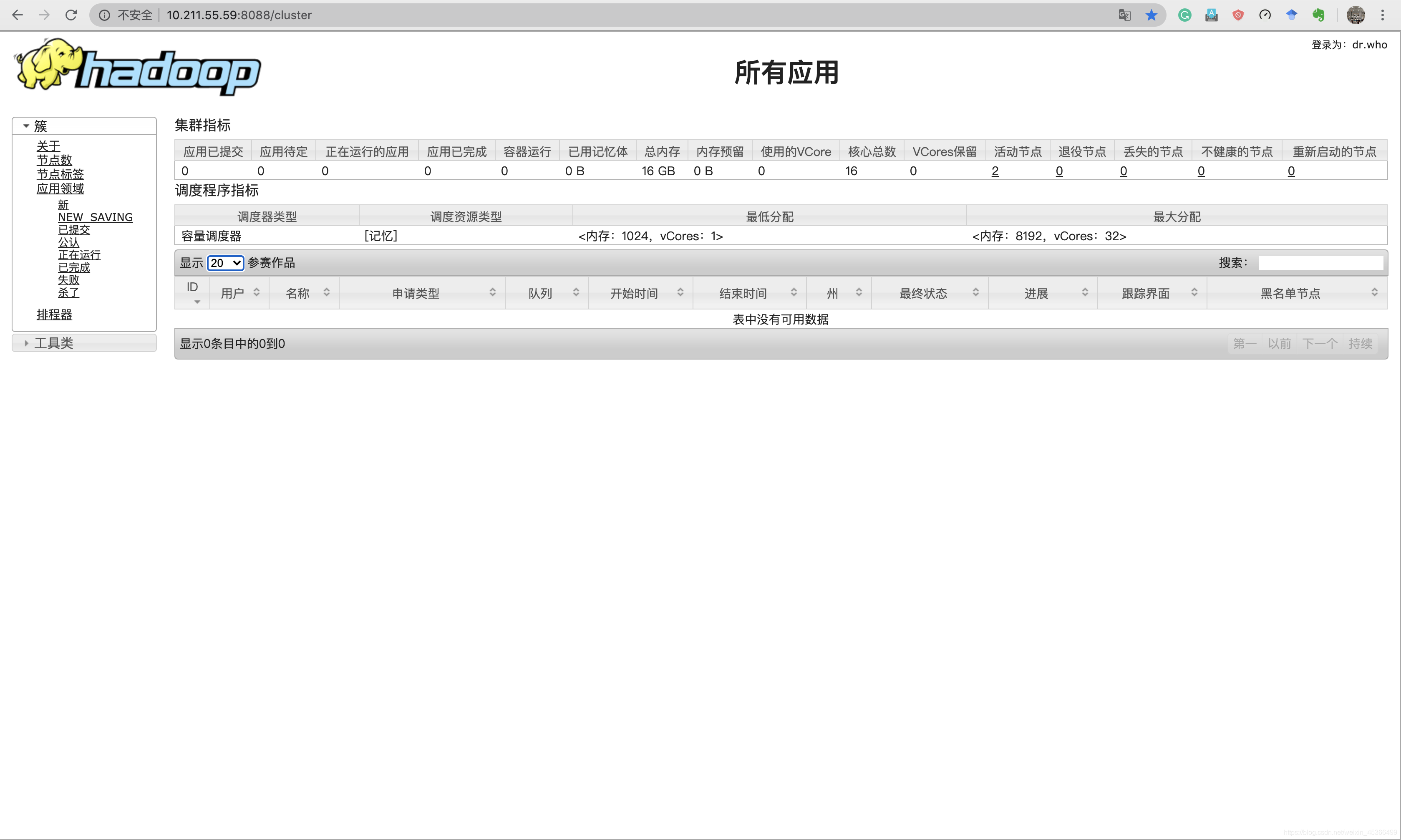
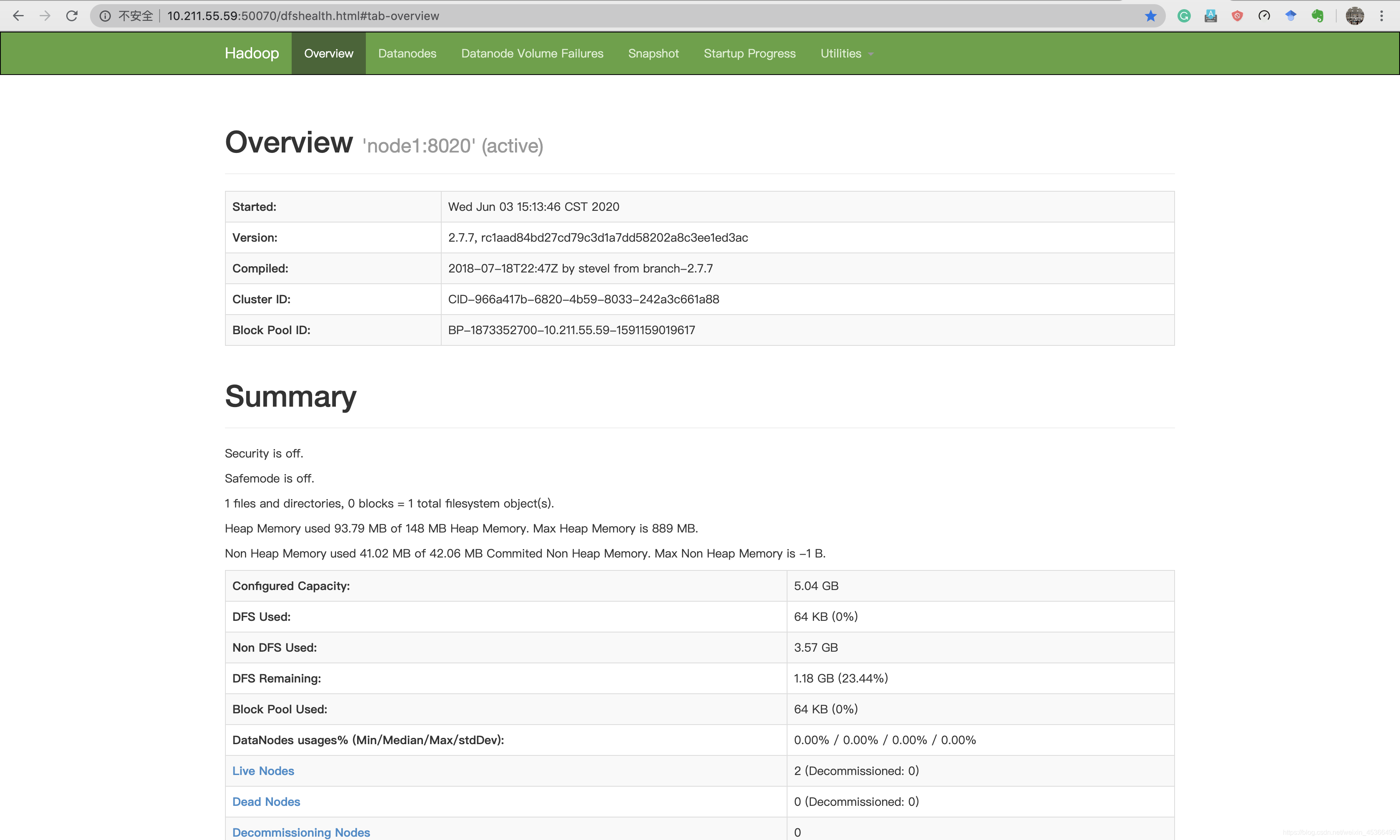
测试Hadoop集群中自带的mapreduce程序
20/06/03 16:42:32 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
20/06/03 16:42:32 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
20/06/03 16:42:32 INFO input.FileInputFormat: Total input paths to process : 1
20/06/03 16:42:32 INFO mapreduce.JobSubmitter: number of splits:1
20/06/03 16:42:33 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local602249199_0001
20/06/03 16:42:33 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
20/06/03 16:42:33 INFO mapreduce.Job: Running job: job_local602249199_0001
20/06/03 16:42:33 INFO mapred.LocalJobRunner: OutputCommitter set in config null
20/06/03 16:42:33 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
20/06/03 16:42:33 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
20/06/03 16:42:33 INFO mapred.LocalJobRunner: Waiting for map tasks
20/06/03 16:42:33 INFO mapred.LocalJobRunner: Starting task: attempt_local602249199_0001_m_000000_0
20/06/03 16:42:33 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
20/06/03 16:42:33 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
20/06/03 16:42:33 INFO mapred.MapTask: Processing split: hdfs://node1:8020/input/123.txt:0+466
20/06/03 16:42:33 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
20/06/03 16:42:33 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
20/06/03 16:42:33 INFO mapred.MapTask: soft limit at 83886080
20/06/03 16:42:33 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
20/06/03 16:42:33 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
20/06/03 16:42:33 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
20/06/03 16:42:33 INFO mapred.LocalJobRunner:
20/06/03 16:42:33 INFO mapred.MapTask: Starting flush of map output
20/06/03 16:42:33 INFO mapred.MapTask: Spilling map output
20/06/03 16:42:33 INFO mapred.MapTask: bufstart = 0; bufend = 852; bufvoid = 104857600
20/06/03 16:42:33 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26214008(104856032); length = 389/6553600
20/06/03 16:42:33 INFO mapred.MapTask: Finished spill 0
20/06/03 16:42:33 INFO mapred.Task: Task:attempt_local602249199_0001_m_000000_0 is done. And is in the process of committing
20/06/03 16:42:33 INFO mapred.LocalJobRunner: map
20/06/03 16:42:33 INFO mapred.Task: Task 'attempt_local602249199_0001_m_000000_0' done.
20/06/03 16:42:33 INFO mapred.Task: Final Counters for attempt_local602249199_0001_m_000000_0: Counters: 23
File System Counters
FILE: Number of bytes read=296198
FILE: Number of bytes written=615022
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=466
HDFS: Number of bytes written=0
HDFS: Number of read operations=5
HDFS: Number of large read operations=0
HDFS: Number of write operations=1
Map-Reduce Framework
Map input records=1
Map output records=98
Map output bytes=852
Map output materialized bytes=846
Input split bytes=96
Combine input records=98
Combine output records=77
Spilled Records=77
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=327
Total committed heap usage (bytes)=372768768
File Input Format Counters
Bytes Read=466
20/06/03 16:42:33 INFO mapred.LocalJobRunner: Finishing task: attempt_local602249199_0001_m_000000_0
20/06/03 16:42:33 INFO mapred.LocalJobRunner: map task executor complete.
20/06/03 16:42:33 INFO mapred.LocalJobRunner: Waiting for reduce tasks
20/06/03 16:42:33 INFO mapred.LocalJobRunner: Starting task: attempt_local602249199_0001_r_000000_0
20/06/03 16:42:33 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
20/06/03 16:42:33 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
20/06/03 16:42:33 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@483200b9
20/06/03 16:42:33 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=334338464, maxSingleShuffleLimit=83584616, mergeThreshold=220663392, ioSortFactor=10, memToMemMergeOutputsThreshold=10
20/06/03 16:42:33 INFO reduce.EventFetcher: attempt_local602249199_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
20/06/03 16:42:33 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local602249199_0001_m_000000_0 decomp: 842 len: 846 to MEMORY
20/06/03 16:42:33 INFO reduce.InMemoryMapOutput: Read 842 bytes from map-output for attempt_local602249199_0001_m_000000_0
20/06/03 16:42:33 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 842, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->842
20/06/03 16:42:33 WARN io.ReadaheadPool: Failed readahead on ifile
EBADF: Bad file descriptor
at org.apache.hadoop.io.nativeio.NativeIO$POSIX.posix_fadvise(Native Method)
at org.apache.hadoop.io.nativeio.NativeIO$POSIX.posixFadviseIfPossible(NativeIO.java:267)
at org.apache.hadoop.io.nativeio.NativeIO$POSIX$CacheManipulator.posixFadviseIfPossible(NativeIO.java:146)
at org.apache.hadoop.io.ReadaheadPool$ReadaheadRequestImpl.run(ReadaheadPool.java:206)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
20/06/03 16:42:33 INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning
20/06/03 16:42:33 INFO mapred.LocalJobRunner: 1 / 1 copied.
20/06/03 16:42:33 INFO reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs
20/06/03 16:42:33 INFO mapred.Merger: Merging 1 sorted segments
20/06/03 16:42:33 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 838 bytes
20/06/03 16:42:33 INFO reduce.MergeManagerImpl: Merged 1 segments, 842 bytes to disk to satisfy reduce memory limit
20/06/03 16:42:33 INFO reduce.MergeManagerImpl: Merging 1 files, 846 bytes from disk
20/06/03 16:42:33 INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce
20/06/03 16:42:33 INFO mapred.Merger: Merging 1 sorted segments
20/06/03 16:42:33 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 838 bytes
20/06/03 16:42:33 INFO mapred.LocalJobRunner: 1 / 1 copied.
20/06/03 16:42:33 INFO Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
20/06/03 16:42:33 INFO mapred.Task: Task:attempt_local602249199_0001_r_000000_0 is done. And is in the process of committing
20/06/03 16:42:33 INFO mapred.LocalJobRunner: 1 / 1 copied.
20/06/03 16:42:33 INFO mapred.Task: Task attempt_local602249199_0001_r_000000_0 is allowed to commit now
20/06/03 16:42:33 INFO output.FileOutputCommitter: Saved output of task 'attempt_local602249199_0001_r_000000_0' to hdfs://node1:8020/output/_temporary/0/task_local602249199_0001_r_000000
20/06/03 16:42:33 INFO mapred.LocalJobRunner: reduce > reduce
20/06/03 16:42:33 INFO mapred.Task: Task 'attempt_local602249199_0001_r_000000_0' done.
20/06/03 16:42:33 INFO mapred.Task: Final Counters for attempt_local602249199_0001_r_000000_0: Counters: 29
File System Counters
FILE: Number of bytes read=297922
FILE: Number of bytes written=615868
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=466
HDFS: Number of bytes written=532
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
Map-Reduce Framework
Combine input records=0
Combine output records=0
Reduce input groups=77
Reduce shuffle bytes=846
Reduce input records=77
Reduce output records=77
Spilled Records=77
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=0
Total committed heap usage (bytes)=372768768
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Output Format Counters
Bytes Written=532
20/06/03 16:42:33 INFO mapred.LocalJobRunner: Finishing task: attempt_local602249199_0001_r_000000_0
20/06/03 16:42:33 INFO mapred.LocalJobRunner: reduce task executor complete.
20/06/03 16:42:34 INFO mapreduce.Job: Job job_local602249199_0001 running in uber mode : false
20/06/03 16:42:34 INFO mapreduce.Job: map 100% reduce 100%
20/06/03 16:42:34 INFO mapreduce.Job: Job job_local602249199_0001 completed successfully
20/06/03 16:42:34 INFO mapreduce.Job: Counters: 35
File System Counters
FILE: Number of bytes read=594120
FILE: Number of bytes written=1230890
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=932
HDFS: Number of bytes written=532
HDFS: Number of read operations=13
HDFS: Number of large read operations=0
HDFS: Number of write operations=4
Map-Reduce Framework
Map input records=1
Map output records=98
Map output bytes=852
Map output materialized bytes=846
Input split bytes=96
Combine input records=98
Combine output records=77
Reduce input groups=77
Reduce shuffle bytes=846
Reduce input records=77
Reduce output records=77
Spilled Records=154
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=327
Total committed heap usage (bytes)=745537536
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=466
File Output Format Counters
Bytes Written=532
以上内容仅供参考学习,如有侵权请联系我删除!
如果这篇文章对您有帮助,左下角的大拇指就是对博主最大的鼓励。
您的鼓励就是博主最大的动力!