文章目录
1. 环境准备
1.1 虚拟机安装
在虚拟机安装一个Centos 7系统,安装教程参考链接。
虚拟机的ip是192.168.126.11,如下图:
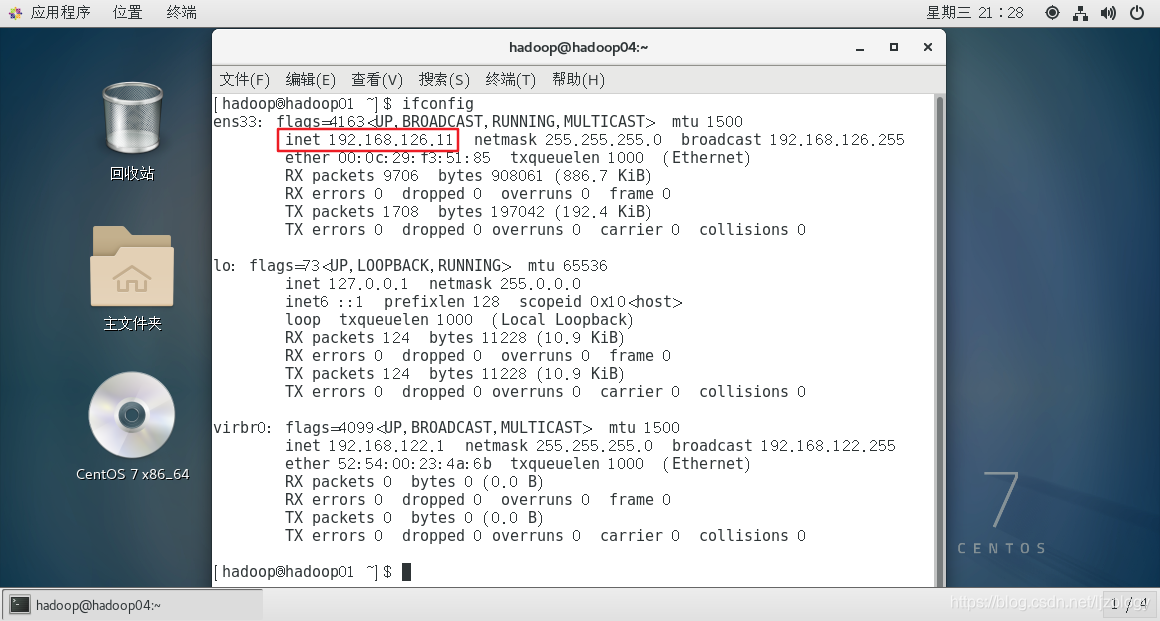
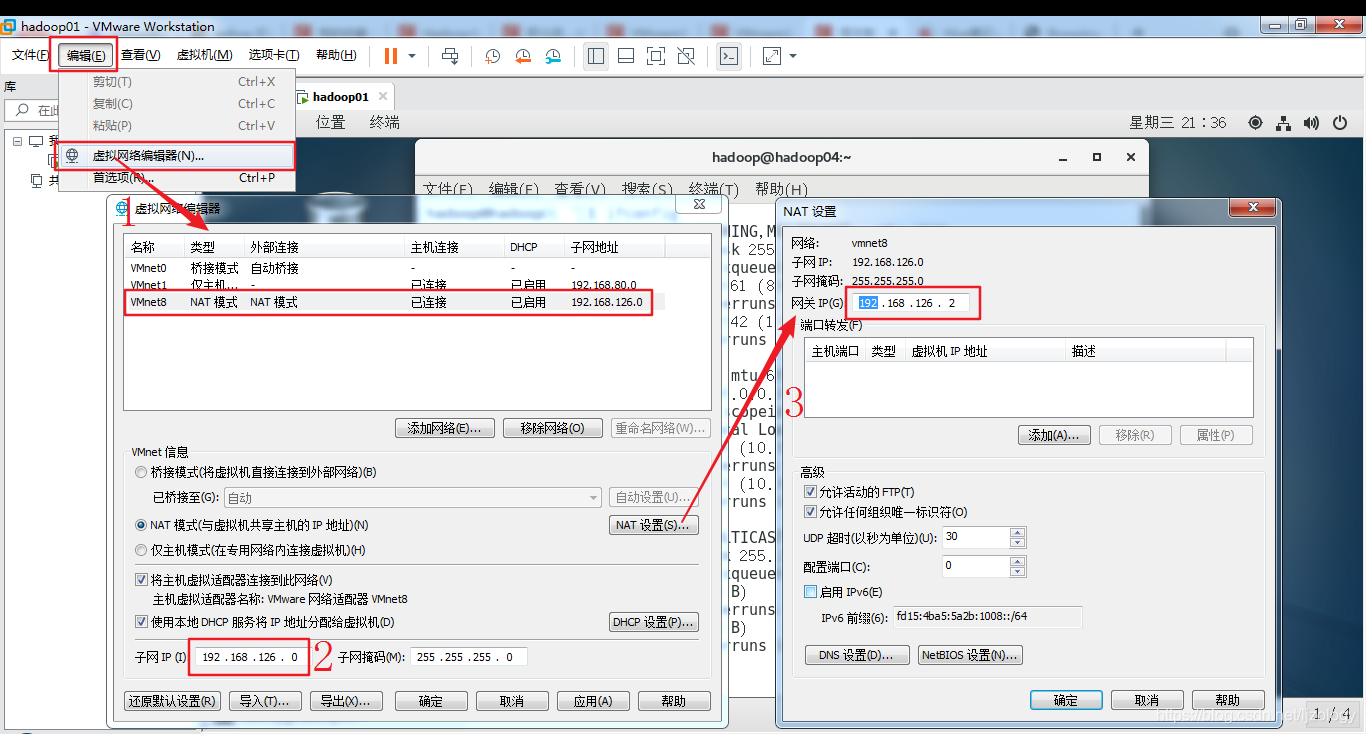
为了记忆方便,把虚拟机ip改成192.168.1.101(也可以不修改,直接进行克隆),首先需要修改一下虚拟网络编辑器,把网关改成192.168.1.2,修改方法:
- 编辑->虚拟网络编辑器
- 点击“VMnet8”,修改子网ip为192.168.1.0
- 点击“NAT设置”,修改网关为:192.168.1.2
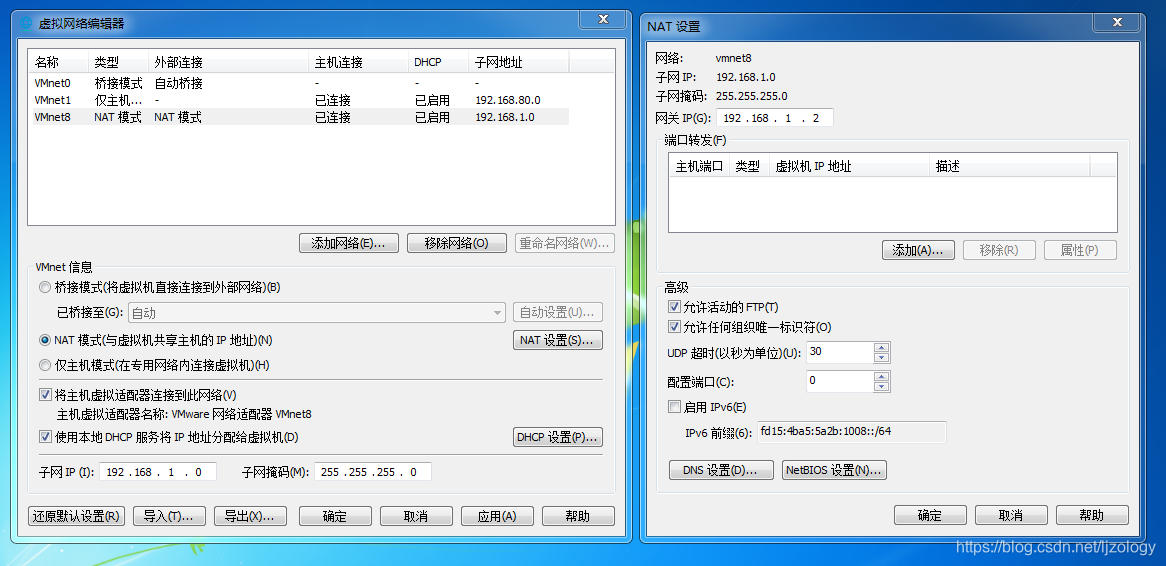
修改之后的效果:
然后修改虚拟机ip,修改命令: vi /etc/sysconfig/network-scripts/ifcfg-ens33
如果提示“W10: 警告: 正在修改一个只读文件”,使用su - root命令切换到root用户进行修改。修改结果为:
TYPE=Ethernet
BOOTPROTO=static
NAME=ens33
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.1.101
NETMASK=255.255.255.0
GATEWAY=192.168.1.2
DNS1=192.168.1.2
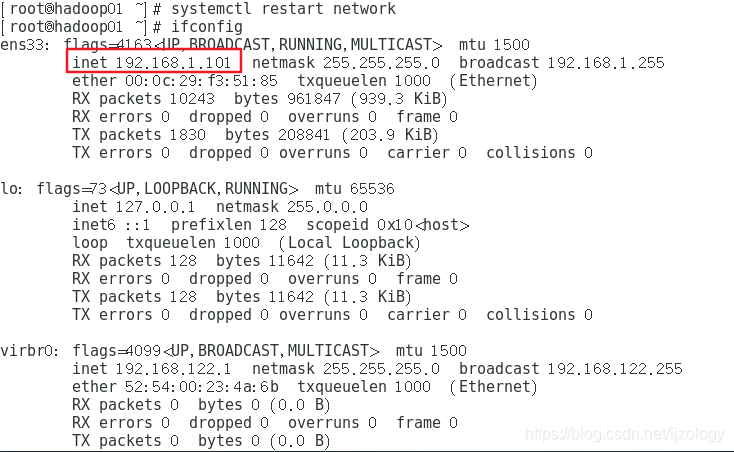
修改完后,使用“systemctl restart network”命令重启网络,重启后ifconfig查看是否重启成功:
使用下面命令停止和禁用防火墙:
systemctl stop firewalld
systemctl disable firewalld
禁用以后用命令systemctl status firewalld查看状态,确认禁用成功:

用MobaXterm连接虚拟机:
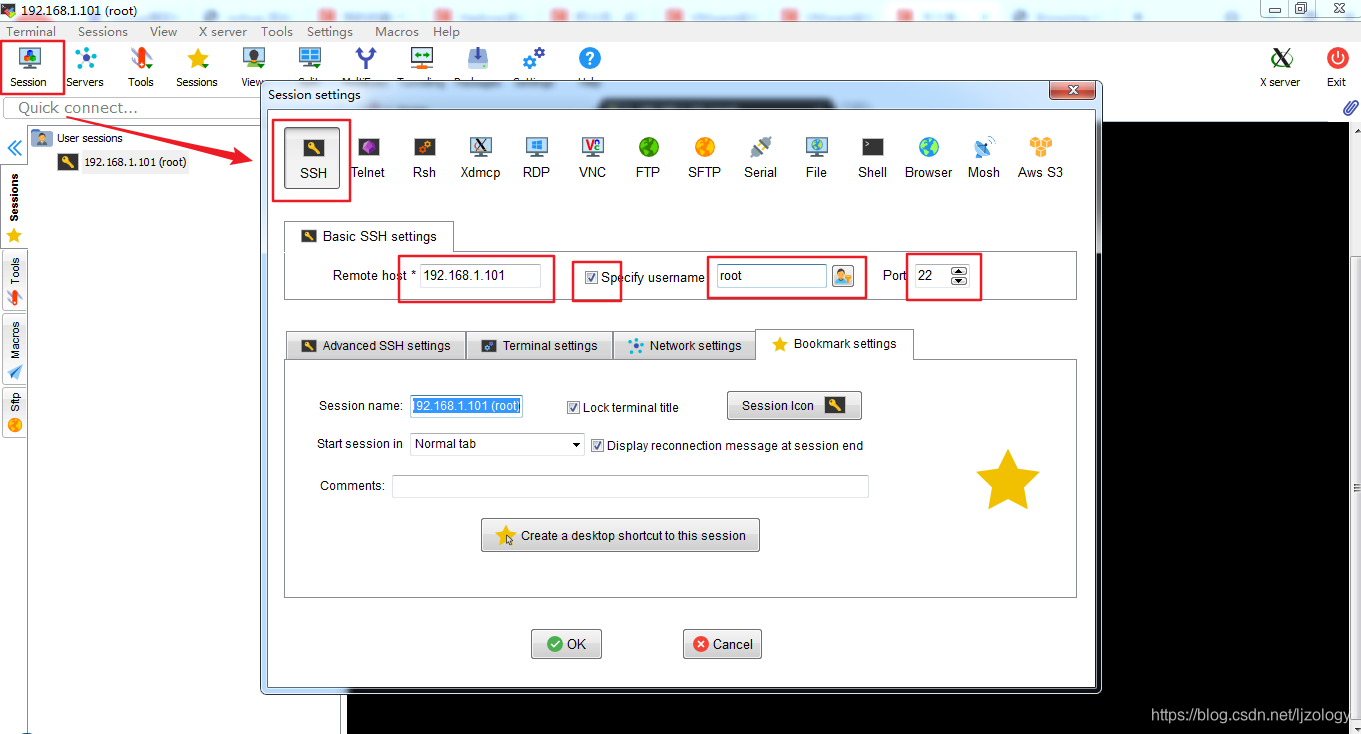
点击OK,双击打开(第一次连的时候比较慢,超时连接失败的话,多连几次),输入密码,下面是连接成功的界面:
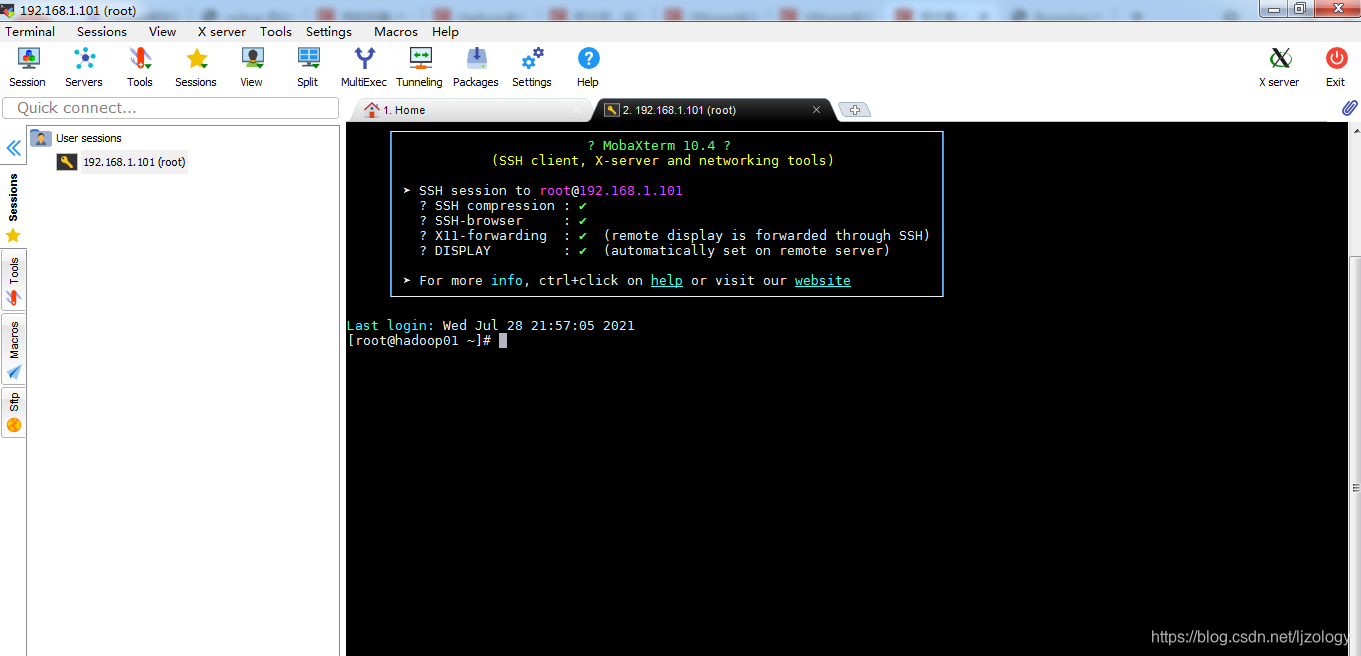
1.2 ip、主机名规划
全分布式Hadoop至少三台节点,ip和主机名规划如下:
| 虚拟机ip | 主机名 |
|---|---|
| 192.168.1.101 | hadoop101 |
| 192.168.1.102 | hadoop102 |
| 192.168.1.103 | hadoop103 |
(1) 修改主机名
临时修改命令:hostname hadoop101
永久修改命令:vi /etc/hostname,把里面的内容修改为hadoop101
修改完成后重新打开终端可看到主机名已经修改:
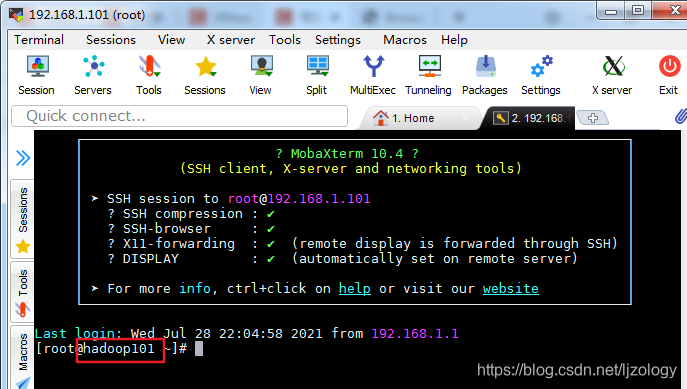
(2) 修改hosts文件
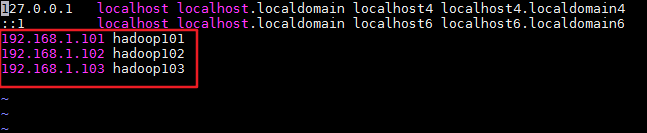
hosts文件是Linux的系统文件,用来映射ip和主机名,用vi /etc/hosts添加如下三行:
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
1.3 安装jdk
下载JDK和Hadoop参考链接
下载完成后拖动到虚拟机:
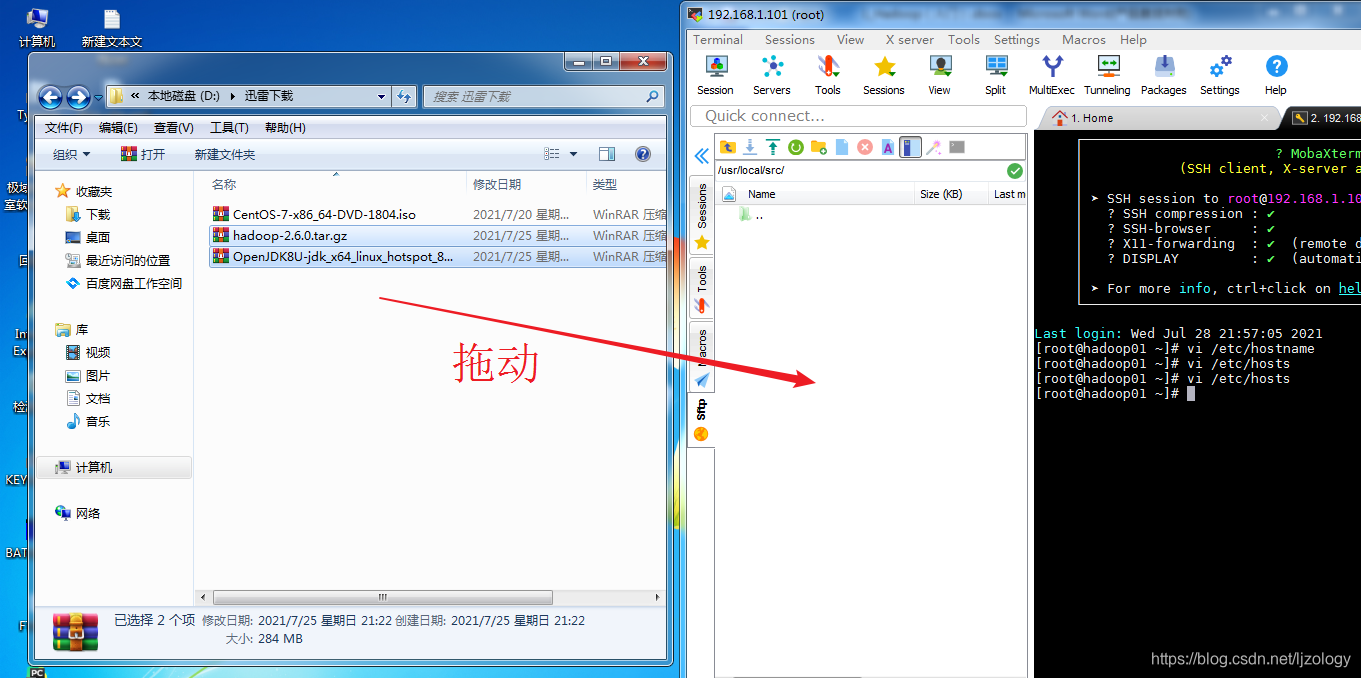
安装
解压JDK和Hadoop:
[root@hadoop101 ~]# cd /usr/local/src/
[root@hadoop101 src]# ls
hadoop-2.6.0.tar.gz OpenJDK8U-jdk_x64_linux_hotspot_8u292b10.tar.gz
[root@hadoop101 src]# tar zxvf OpenJDK8U-jdk_x64_linux_hotspot_8u292b10.tar.gz
[root@hadoop101 src]# tar zxvf hadoop-2.6.0.tar.gz
解压完成后,会多出两个文件夹:

添加环境变量
添加之前查看是否已经安装了jdk,查看命令:java -version
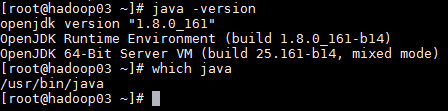
如果出现jdk的版本号,说明已经安装了jdk,命令which java查看jdk的安装路径。如果没有安装,则直接安装下载好的JDK。
如果已经安装,为了后期方便修改和配置,把自带的JDK卸载,重新安装JDK。
卸载方法:
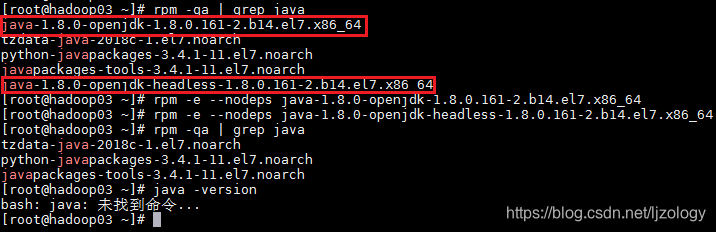
首先查看已经安装的JDK,查看命令:rpm -qa | grep java
如下:红框圈起来的是已经安装的jdk,卸载命令是:rpm -e --nodeps 包名
卸载后才用命令java -version查看,显示“未找到命令”说明卸载成功。如下图:
卸载完成后,安装自己下载的JDK,有两种配置环境变量的方法:
- 修改/etc/profile,这个文件对所有的用户都生效。
- 修改用户家目录下的.bash_profile文件,直对当前用户生效。
我采用的方法2,修改root用户家目录下的.bash_profile(/root/.bash_profile)。
命令vi /root/.bash_profile(vi编辑器的使用参考链接)
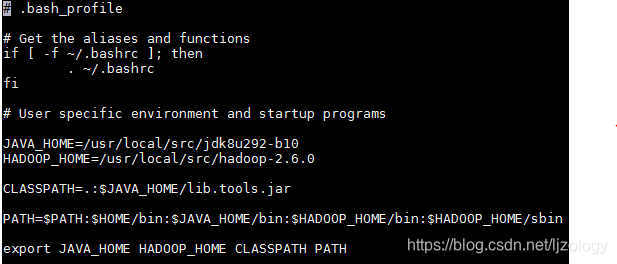
在最下面添加如下内容:
JAVA_HOME=/usr/local/src/jdk8u292-b10
HADOOP_HOME=/usr/local/src/hadoop-2.6.0
CLASSPATH=.:$JAVA_HOME/lib.tools.jar
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_HOME HADOOP_HOME CLASSPATH PATH
修改完以后用命令 source /root/.bash_profile,使其生效。
java -version查看java版本,检查是否安装成功:

hadoop version查看Hadoop版本:

如果提示如下错,是说明jdk配置错误,检查jdk的配置。

1.4 克隆
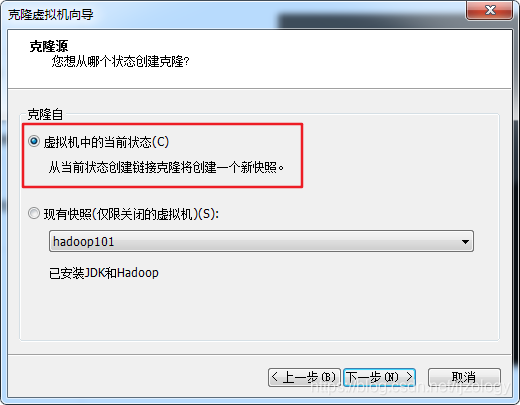
这时候已经安装好JDK和单机模式的Hadoop,部署全分布式模式的Hadoop需要再克隆两台虚拟机,克隆之前先做一个快照,方便后期安装出现问题进行恢复,快照方法如下:
快照之前关闭虚拟机,可以通过
shutdown -h now命令进行关机,也可以通过VMware上的关机按钮。
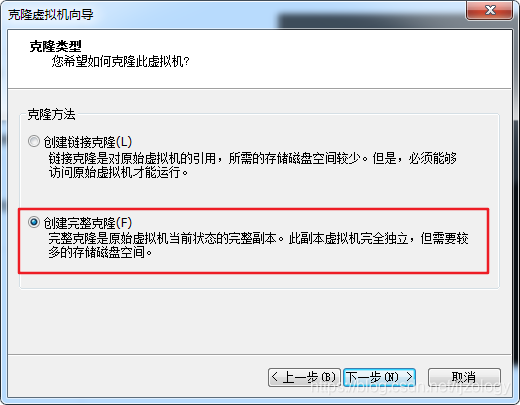
克隆方法如下:
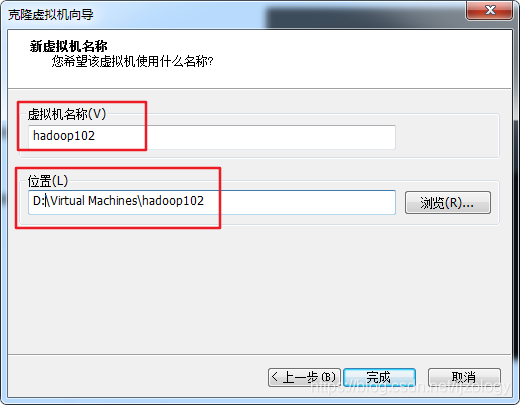
在D盘创建一个Virtual Machines文件夹存放虚拟机,方便后期管理。
注意不要放在系统盘,因为虚拟机后期会越来越大撑爆系统盘
用同样的方法在克隆一台虚拟机名字为hadoop103。


配置hadoop102和hadoop103的网络
克隆完成后,克隆机和原始虚拟机是完全一样的,会产生ip冲突,所以需要修改克隆机的ip和主机名:
su root
vi /etc/sysconfig/network-scripts/ifcfg-ens33
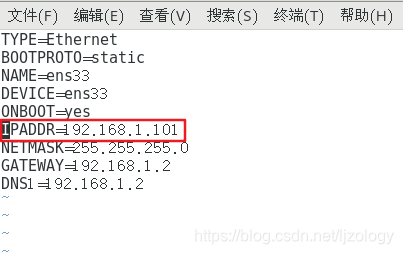
/etc/sysconfig/network-scripts/ifcfg-ens33是网络配置文件,contos 7默认使用ifcfg-ens33网络。
hadoop102的ip修改为192.168.1.102
hadoop103的ip修改为192.168.1.103
修改完以后重启网络、关闭并禁用防火墙:
systemctl restart network
systemctl stop firewalld
systemctl disable firewalld
修改hadoop102和hadoop103的主机名
临时修改命令:hostname hadoop102
永久修改命令:vi /etc/hostname,把里面的内容修改为hadoop102


关闭终端,再重新打开,主机名就会变成hadoop102:
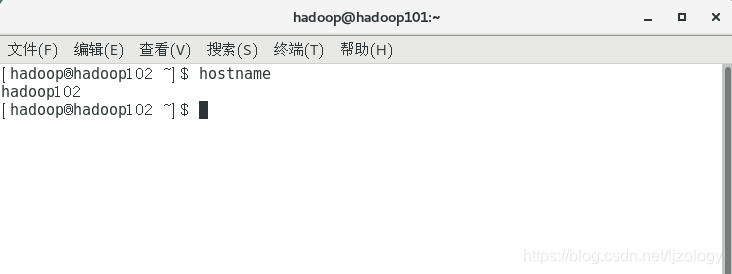
先执行临时修改,在执行永久修改,不用重启虚拟机,如果仅仅执行永久修改,需要重启虚拟机
用同样的方法修改克隆机hadoop103的主机名为hadoop103
2.配置Hadoop
2.1 集群部署规划
NameNode和SecondaryNameNode不要安装在同一台服务器
ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。

2.2 配置集群
全分布式模式需要修改6个配置文件:
1.hadoop-env.sh
2.core-site.xml
3.hdfs-site.xml
4.yarn-site.xml
5.mapred-site.xml
6.slaves
其中hadoop-env.sh告知hadoop一些系统的环境变量,如JAVA_HOME;
core-site.xml和hdfs-site.xml是hdfs相关的配置文件;
yarn-site.xml和mapred-site.xml是yarn相关的配置文件;
slaves是配置安装DataNode节点的主机名或ip
(1)修改hadoop-env.sh
vim hadoop-env.sh
添加如下一句(由自己jdk安装路径确定)
export JAVA_HOME=/usr/local/src/jdk8u292-b10
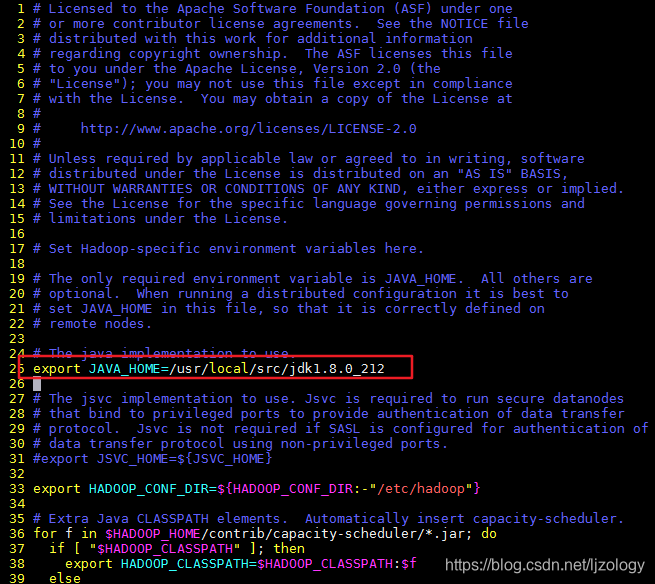
注意:最左边是行号,#表示注释
(2)核心配置文件
配置core-site.xml
cd $HADOOP_HOME/etc/hadoop
vim core-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<!-- 指定hdfs中NameNode的位置 -->
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:9820</value>
</property>
<!-- hadoop.data.dir是自定义的变量,下面的配置文件会用到 -->
<property>
<name>hadoop.data.dir</name>
<value>/usr/local/src/hadoop-2.6.0/data</value>
</property>
</configuration>
(3)HDFS配置文件
配置hdfs-site.xml
vim hdfs-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- namenode数据存放位置 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.data.dir}/name</value>
</property>
<!-- datanode数据存放位置 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.data.dir}/data</value>
</property>
<!-- secondary namenode数据存放位置 -->
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file://${hadoop.data.dir}/namesecondary</value>
</property>
<!-- datanode重启超时时间是30s,解决兼容性问题,跳过 -->
<property>
<name>dfs.client.datanode-restart.timeout</name>
<value>30</value>
</property>
<!-- 设置web端访问namenode的地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop101:9870</value>
</property>
<!-- 设置web端访问secondary namenode的地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:9868</value>
</property>
<!-- 关闭权限校验,开发学习时可开启,默认为true -->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
(4)YARN配置文件
配置yarn-site.xml
vim yarn-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
(5)MapReduce配置文件
配置mapred-site.xml
vim mapred-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(6)slaves配置文件
slaves是配置datanode节点的,也就是实际存储数据的节点,伪分布式部署的话不需要修改这个文件,全分布式需要修改,把规划的DataNode节点的主机名写到slaves中:
vi slaves
添加内容如下:
hadoop101
hadoop102
hadoop103
注意:此文件中不可有空格和换行,否则会报错
现在hadoop101上的hadoop已经配置完毕,需要配置另外两台克隆机的hadoop,为了方便,我们直接把hadoop101上的配置文件直接复制到hadoop102和hadoop103。
跨机器复制的方法有两种:scp和rsync
scp是覆盖式拷贝,把所有文件都拷过去;
rsync 只对差异性文件做更新,拷贝速度比scp更快;
我用的是rsync:
[root@hadoop101 tt]# cd $HADOOP_HOME
[root@hadoop101 hadoop-2.6.0]# rsync -r etc/hadoop root@hadoop103:/usr/local/src/hadoop-2.6.0/etc/
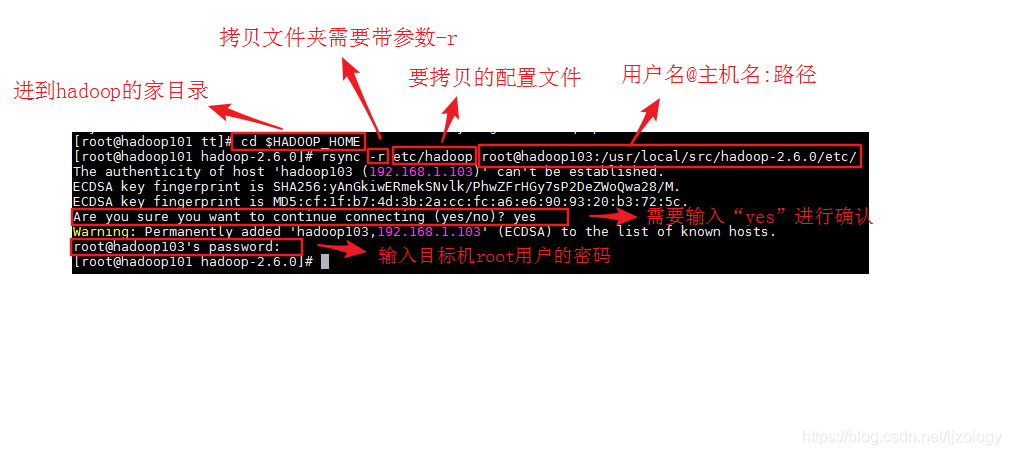
同样的方法拷贝配置文件到hadoop102。
拷贝完成后看hadoop102和hadoop103的配置文件是否修改成功。
3. 格式化并单点启动
3.1 格式化
在NameNode节点进行格式化:
[root@hadoop101 ~]# hdfs namenode -format
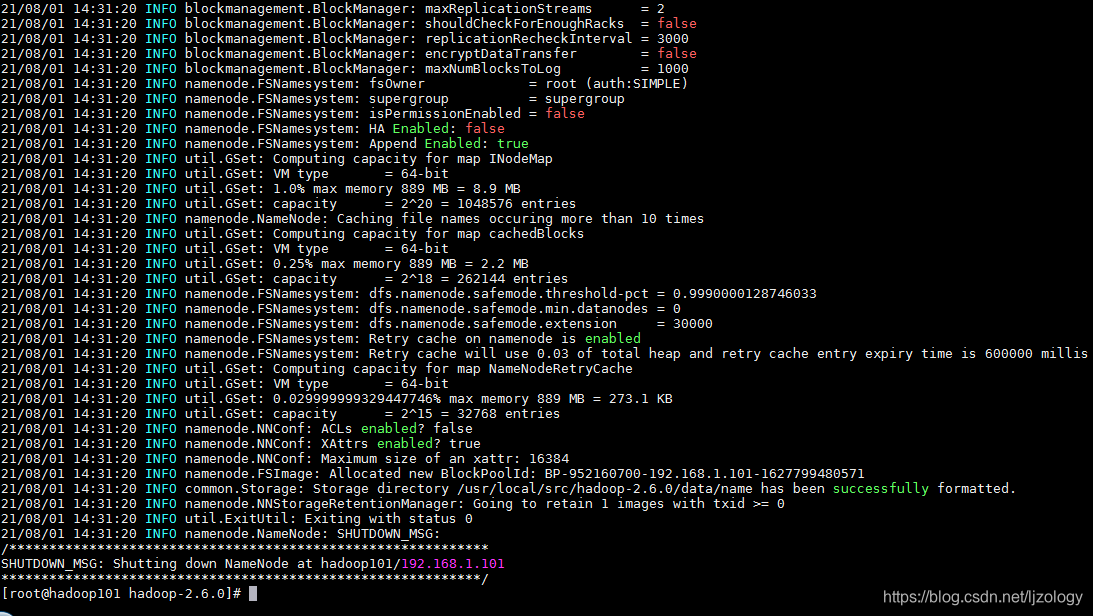
没有报错表示格式化成功。
3.2 单点启动
单点启动可以不操作,直接进行群启动的配置,单点启动有助于理解hdfs和yarn的关系。
(1) 启动hdfs
启动NameNode命令:hadoop-daemon.sh start namenode
启动 DataNode 命令:hadoop-daemon.sh start datanode
hadoop3.0和hadoop2.0的启动命令不同,在安装3.0是注意区分
根据集群部署规划表:
在hadoop101上启动NameNode;
在hadoop101、hadoop102、hadoop103上启动DataNode;
启动以后用jps命令查看启动的进程:
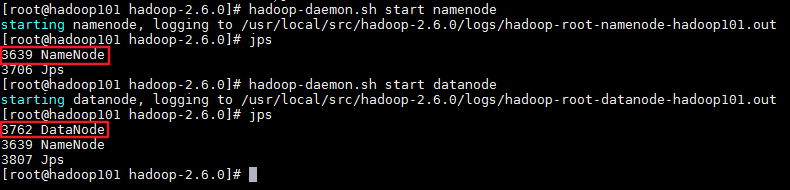
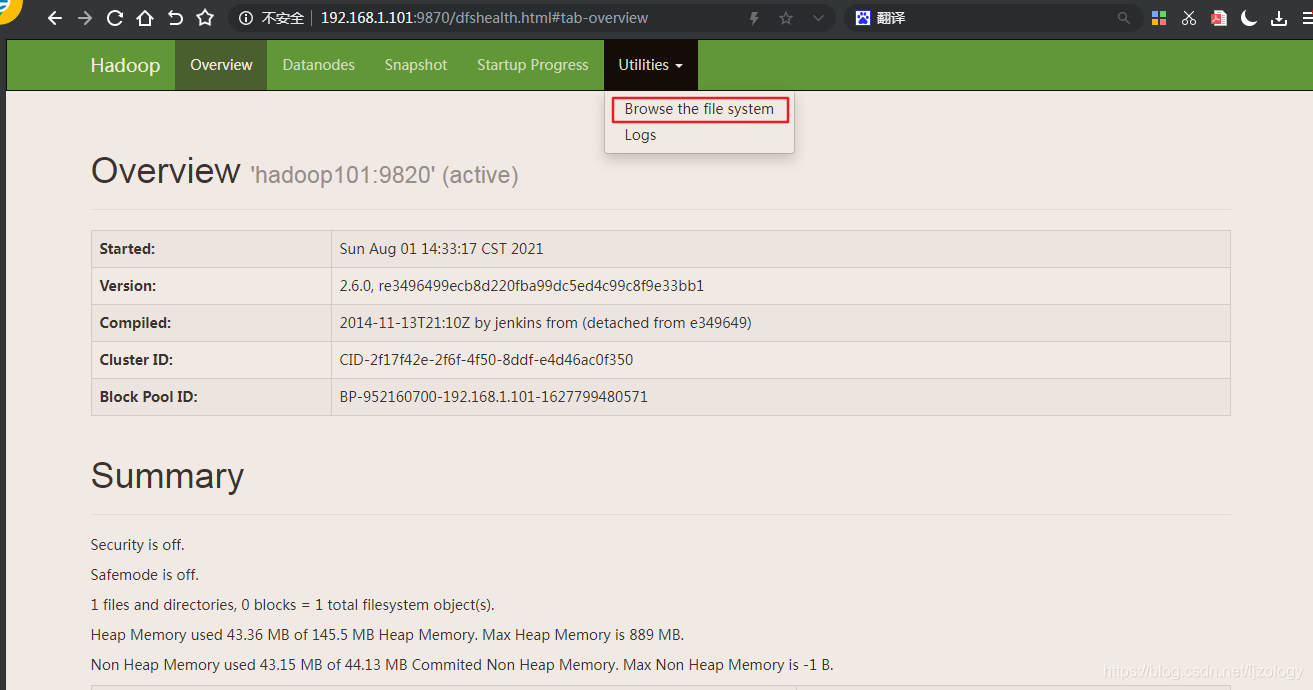
这时候就可以登录hdfs的web端查看集群的状态:
http://192.168.1.101:9870
或http://192.168.1.101:50070
Hadoop2.0跟Hadoop3.0默认端口不同。
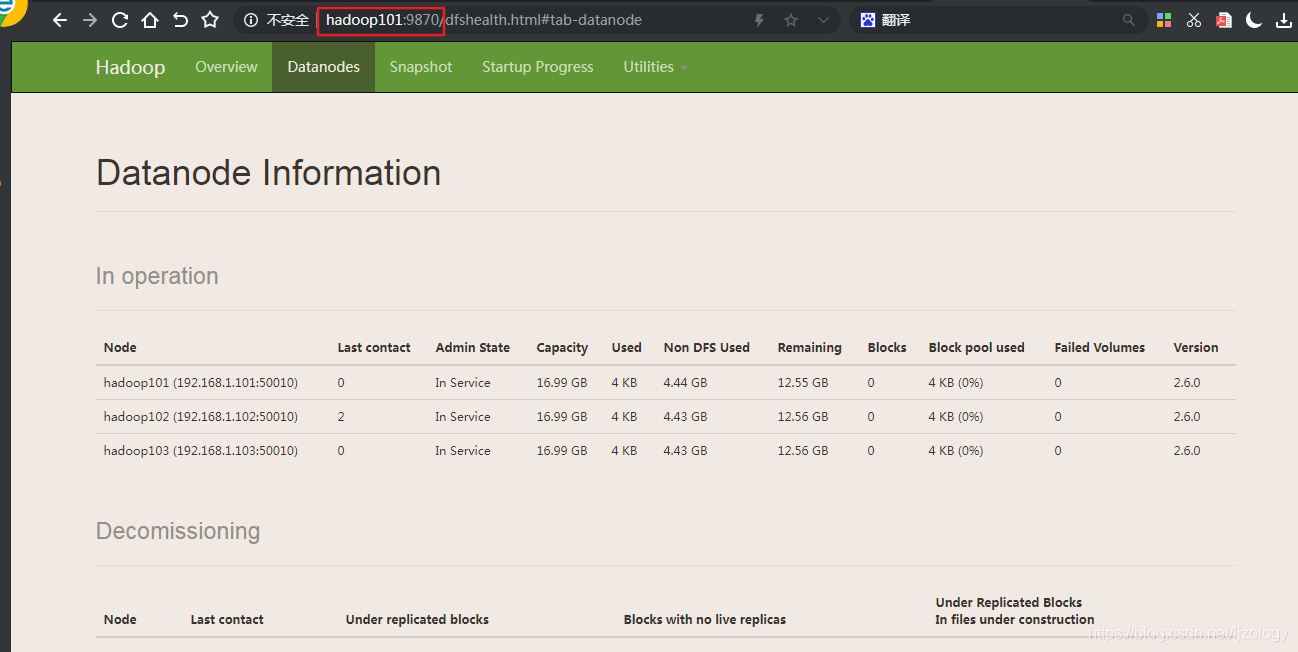
配置本地window的ip和主机名映射关系:
用记事本打开C:\Windows\System32\drivers\etc\hosts文件,在最下面添加以下内容:
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
建立了映射关系就可以通过网址http://hadoop101:9870进行访问了。
(2) 启动yarn
启动ResourceManager命令:yarn-daemon.sh start resourcemanager
启动NodeManager命令:yarn-daemon.sh start nodemanager
hadoop3.0和hadoop2.0的启动命令不同,在安装3.0是注意区分
根据规划表:
在hadoop102上启动ResourceManager;
在hadoop101、hadoop102、hadoop103上启动NodeManager;
jps命令查看启动后的进程:
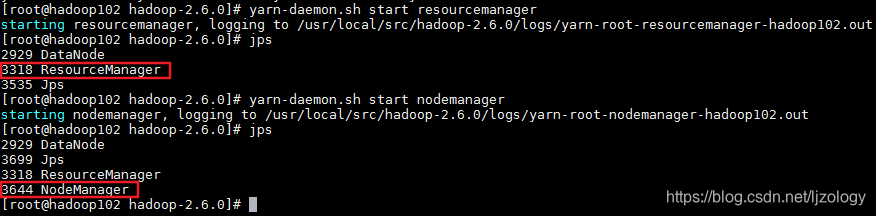
启动成功后可以通过web端查看yarn中任务和nodemanager节点的状态:
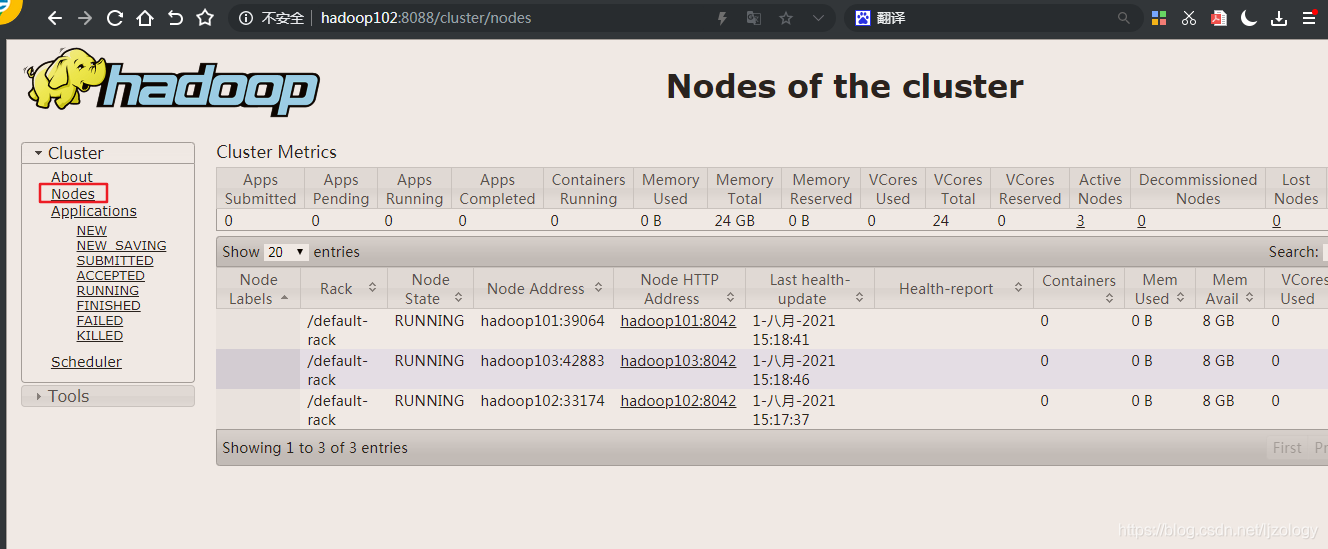
http://192.168.1.102:8088
注:192.168.1.102是ResourceManager所在的节点ip
4. 配置免密登陆,群启动
4.1 免密登录
当集群中节点很多时,步骤3中单点启动的方式就会很麻烦,需要到每个节点进行相应服务的启动,我们可以通过配置ssh免密码登录来进行群启动。
设置SSH免密登录的流程:
有两台机器A和B,A想免密登录B,A需要做两件事:
第一,通过ssh-keygen产生公钥和私钥;
第二,A把产生的公钥发送给B,发送的时候需要输入一次B的密码,发送成功A就可以免密登录B了。
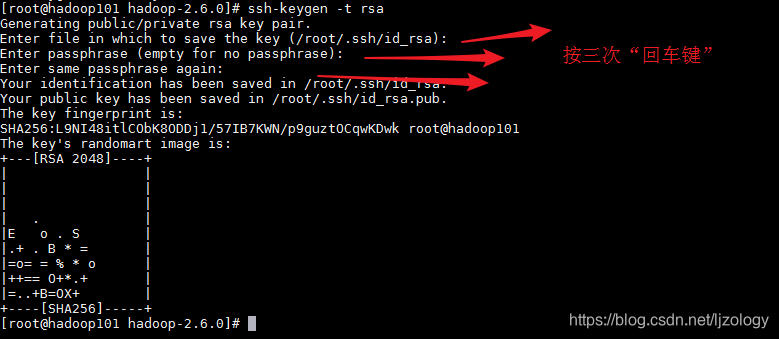
用ssh-keygen -t rsa命令产生公钥和私钥,-t rsa参数是指定加密方式,不指定的话默认也是rsa
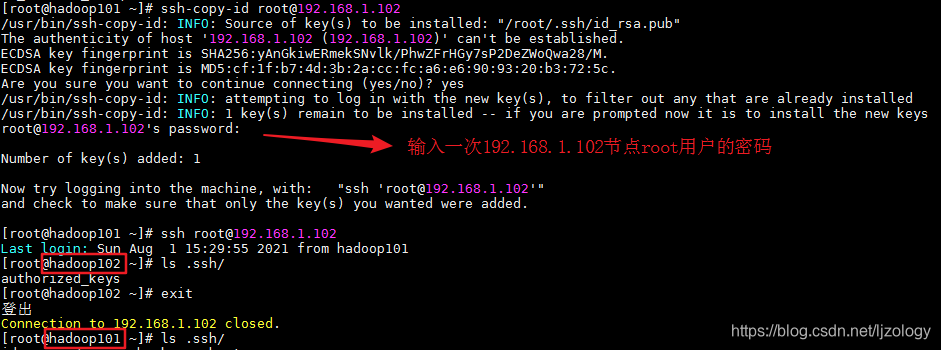
把公钥拷贝给要免密登录的节点:ssh-copy-id [email protected]
也可以用:ssh-copy-id root@hadoop102
拷贝成功后登录命令:ssh [email protected]
退出命令:exit
注意
需要在每个节点执行如下命令,实现两两相互免密登录
ssh-keygen -t rsa
ssh-copy-id root@hadoop101
ssh-copy-id root@hadoop102
ssh-copy-id root@hadoop103
4.2 群启动hdfs和yarn
配置完免密登录就可以进行群启动了。
启动hdfs
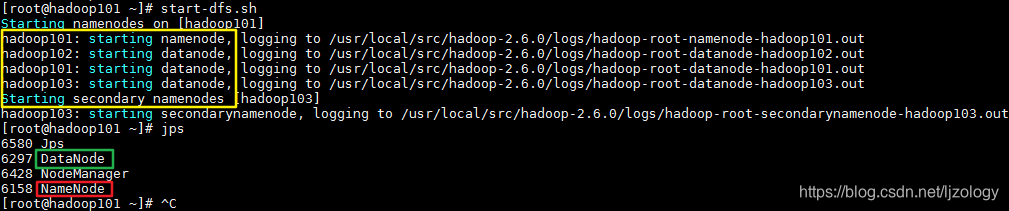
在NameNode节点启动hdfs:start-dfs.sh
从启动信息里可看到:
在hadoop101上启动了namenode;
在hadoop101、hadoop102、hadoop103上启动了datanode;
在hadoop103上启动了secondary namenode;
跟前面规划的一样。
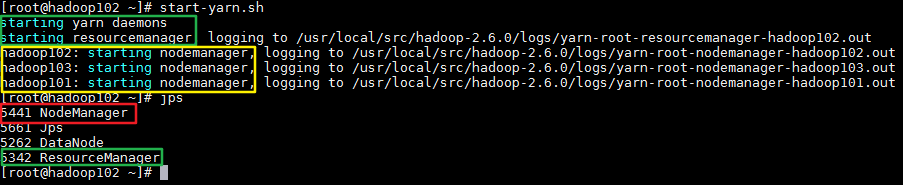
在ResourceManager节点启动yarn:start-yarn.sh
从启动日志可看到
在hadoop102上启动了resourcemanager
在hadoop101、hadoop102、hadoop103上启动了nodemanager
5. 测试
5.1 HDFS简单操作
- 创建文件夹:
hdfs dfs -mkdir /input
hdfs dfs -ls /

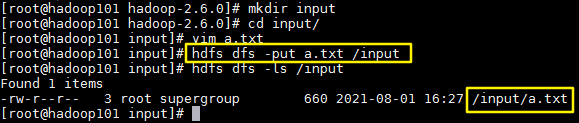
2. 上传文件:
在hadoop的家目录创建input文件夹,创建文件a.txt,内容为:
apple orange banana cat dog apple apple dog dog cat cat cat
apple orange banana cat dog apple apple dog dog cat cat cat
apple orange banana cat dog apple apple dog dog cat cat cat
apple orange banana cat dog apple apple dog dog cat cat cat
apple orange banana cat dog apple apple dog dog cat cat cat
apple orange banana cat dog apple apple dog dog cat cat cat
apple orange banana cat dog apple apple dog dog cat cat cat
apple orange banana cat dog apple apple dog dog cat cat cat
apple orange banana cat dog apple apple dog dog cat cat cat
apple orange banana cat dog apple apple dog dog cat cat cat
apple orange banana cat dog apple apple dog dog cat cat cat
上传命令:hdfs dfs -put a.txt /input
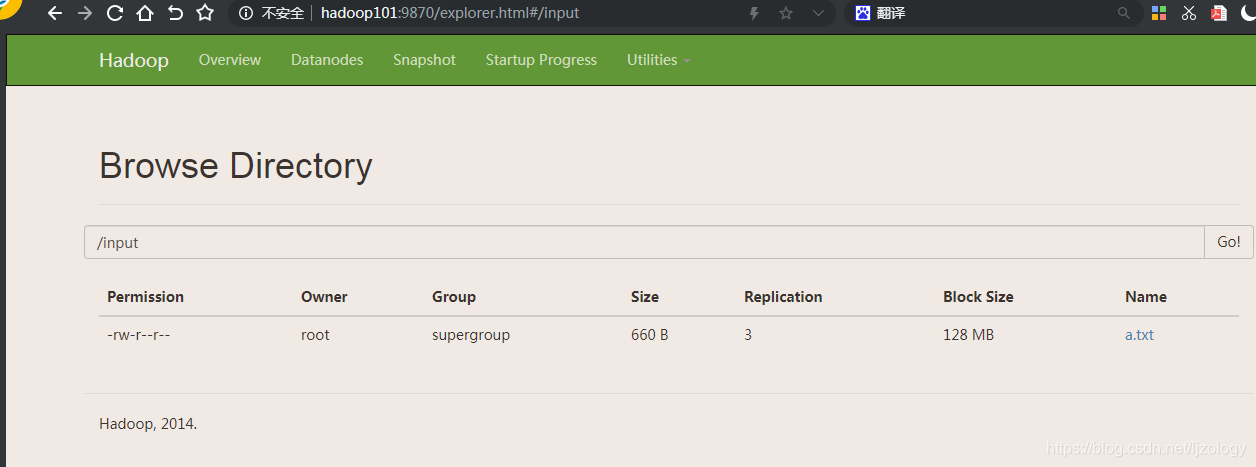
在web端也能看到,hadoop2.0不能再web端上传文件,hadoop3.0增加了此功能。
5.2. 运行Wordcount
此时安装了hdfs,并配置了yarn,此时的操作是对hdfs路径上的文件,任务调度和资源管理是yarn负责的。
运行命令(在任何一个节点都可以):
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount /input/a.txt /output
注:/input/a.txt 和/output都是hdfs上的路径
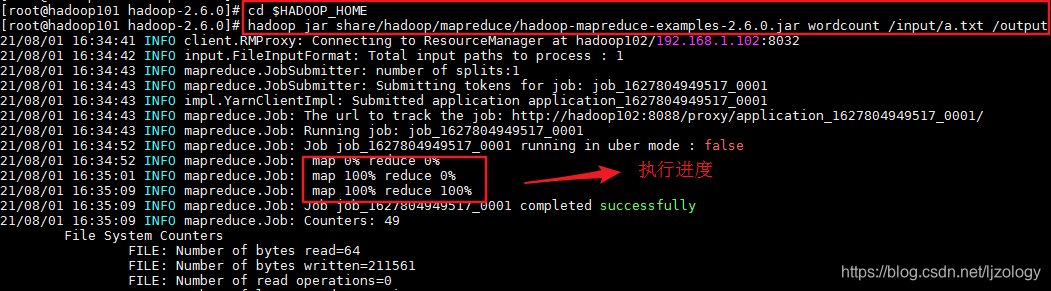
在yarn上能看到该任务的执行状态:
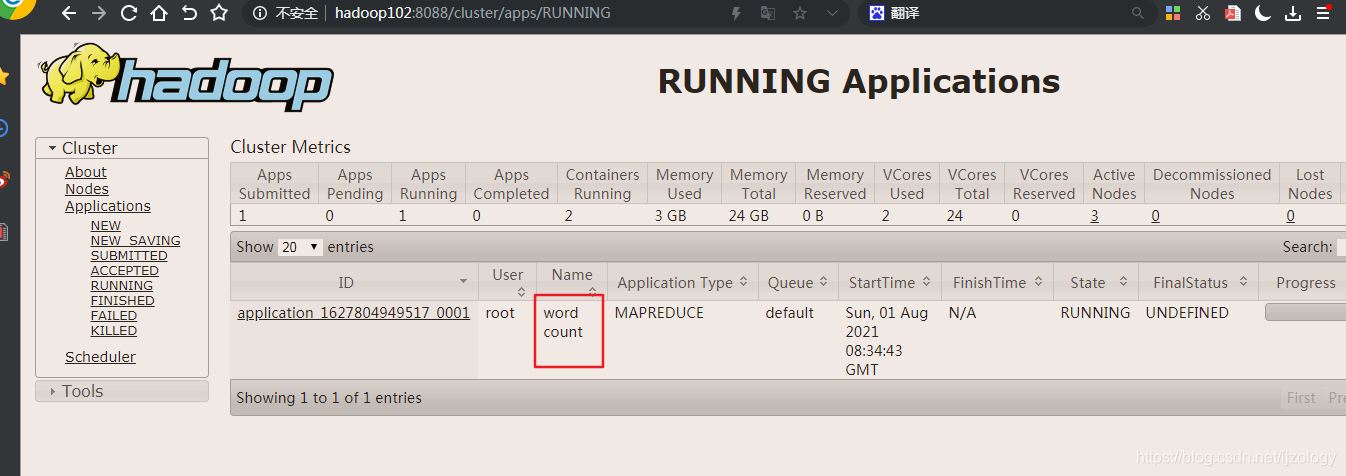
查看执行结果:
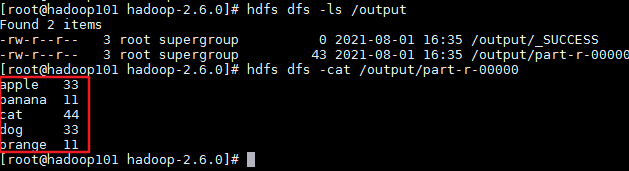
也可在hdfs的web端进行查看。