①
1.1 name,无[0],无循环——打印出列表
import requests
from lxml import etree
url="https://movie.douban.com/top250"
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}
html = requests.get(url, headers=header).text
selector=etree.HTML(html)
name=selector.xpath('//ol[@class="grid_view"]/li/div/div[2]/div[1]/a/span[1]/text()')
print(name)
# ['肖申克的救赎', '霸王别姬'..(省去21条记录)..'怦然心动','触不可及']
1.2 name,有[0],无循环———返回列表中第一个元素
import requests
from lxml import etree
url="https://movie.douban.com/top250"
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}
html = requests.get(url, headers=header).text
selector=etree.HTML(html)
name=selector.xpath('//ol[@class="grid_view"]/li/div/div[2]/div[1]/a/span[1]/text()')[0]
print(name)
# 肖申克的救赎
1.3 name,有.extract()或者.extract()[0],无循环——均报错
import requests
from lxml import etree
url="https://movie.douban.com/top250"
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}
html = requests.get(url, headers=header).text
selector=etree.HTML(html)
name=selector.xpath('//ol[@class="grid_view"]/li/div/div[2]/div[1]/a/span[1]/text()').extract()[0]
print(name)
# .extract() .extract()[0] 均报错
②
2.1 name,score,无[0],无循环——打印出两个列表
import requests
from lxml import etree
url="https://movie.douban.com/top250"
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}
html = requests.get(url, headers=header).text
selector=etree.HTML(html)
name=selector.xpath('//ol[@class="grid_view"]/li/div/div[2]/div[1]/a/span[1]/text()')
score=selector.xpath('//ol[@class="grid_view"]/li/div/div[2]/div[2]/div/span[2]/text()')
print(name,score)
# ['肖申克的救赎', '霸王别姬'..(省去21条记录)..'怦然心动','触不可及']['9.7','9.6'..(省去21条记录).. '9.1','9.2']
2.2.1 name,score,有[0],无循环——分别返回两个列表中的第一个元素
import requests
from lxml import etree
url="https://movie.douban.com/top250"
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}
html = requests.get(url, headers=header).text
selector=etree.HTML(html)
name=selector.xpath('//ol[@class="grid_view"]/li/div/div[2]/div[1]/a/span[1]/text()')[0]
score=selector.xpath('//ol[@class="grid_view"]/li/div/div[2]/div[2]/div/span[2]/text()')[0]
print(name,score)
# 肖申克的救赎 9.7
2.2.2 name,score,有[1],无循环——分别返回两个列表中的第二个元素
import requests
from lxml import etree
url="https://movie.douban.com/top250"
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}
html = requests.get(url, headers=header).text
selector=etree.HTML(html)
name=selector.xpath('//ol[@class="grid_view"]/li/div/div[2]/div[1]/a/span[1]/text()')[1]
score=selector.xpath('//ol[@class="grid_view"]/li/div/div[2]/div[2]/div/span[2]/text()')[1]
print(name,score)
# 霸王别姬 9.6
③有循环
3.1.1 name,score,无[0],有循环——打印出每次循环的结果
import requests
from lxml import etree
url="https://movie.douban.com/top250"
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}
html = requests.get(url, headers=header).text
selector=etree.HTML(html)
lis=selector.xpath('//ol[@class="grid_view"]/li')
for oneSelector in lis:
name=oneSelector.xpath("div/div[2]/div[1]/a/span[1]/text()")
score=oneSelector.xpath("div/div[2]/div[2]/div/span[2]/text()")
print(name,score)
# ['肖申克的救赎'] ['9.7'] ----第一次循环后的结果
# ['霸王别姬'] ['9.6'] ----第二次循环后的结果
# .....中间省去21条记录
# ['怦然心动'] ['9.1']
# ['触不可及'] ['9.2']
3.1.2 name,score,有[0],有循环——打印出每次循环的结果
import requests
from lxml import etree
url="https://movie.douban.com/top250"
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}
html = requests.get(url, headers=header).text
selector=etree.HTML(html)
lis=selector.xpath('//ol[@class="grid_view"]/li')
for oneSelector in lis:
name=oneSelector.xpath("div/div[2]/div[1]/a/span[1]/text()")[0]
score=oneSelector.xpath("div/div[2]/div[2]/div/span[2]/text()")[0]
print(name,score)
# 肖申克的救赎 9.7 ----第一次循环后的结果
# 霸王别姬 9.6 ----第二次循环后的结果
# .....中间省去21条记录
# 怦然心动 9.1
# 触不可及 9.2
3.1.3 name,score,有[0],有循环——打印出最终结果
import requests
from lxml import etree
url="https://movie.douban.com/top250"
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}
html = requests.get(url, headers=header).text
selector=etree.HTML(html)
lis=selector.xpath('//ol[@class="grid_view"]/li')
for oneSelector in lis:
name=oneSelector.xpath("div/div[2]/div[1]/a/span[1]/text()")[0]
score=oneSelector.xpath("div/div[2]/div[2]/div/span[2]/text()")[0]
print(name,score)
# 触不可及 9.2
④
4.1.1 name,score,people无[0],有循环,存入一个元组中——打印出每次循环的结果
import requests
from lxml import etree
url="https://movie.douban.com/top250"
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}
html = requests.get(url, headers=header).text
selector=etree.HTML(html)
lis=selector.xpath('//ol[@class="grid_view"]/li')
allMovieList=[]
for oneSelector in lis:
name=oneSelector.xpath("div/div[2]/div[1]/a/span[1]/text()")
score=oneSelector.xpath("div/div[2]/div[2]/div/span[2]/text()")
people=oneSelector.xpath("div/div[2]/div[2]/div/span[4]/text()")
oneMovieList=[name,score,people]
print(oneMovieList)
# [['肖申克的救赎'], ['9.7'], ['1918400人评价']] ----第一次循环后的结果
# [['霸王别姬'], ['9.6'], ['1411167人评价']] ----第二次循环后的结果
# ..(省去20条记录)..
# [['怦然心动'], ['9.1'], ['1193590人评价']]
# [['触不可及'], ['9.2'], ['677191人评价']]
4.1.2 name,score,people有[0],有循环,存入一个元组中——打印出每次循环的结果
import requests
from lxml import etree
url="https://movie.douban.com/top250"
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}
html = requests.get(url, headers=header).text
selector=etree.HTML(html)
lis=selector.xpath('//ol[@class="grid_view"]/li')
allMovieList=[]
for oneSelector in lis:
name=oneSelector.xpath("div/div[2]/div[1]/a/span[1]/text()")[0]
score=oneSelector.xpath("div/div[2]/div[2]/div/span[2]/text()")[0]
people=oneSelector.xpath("div/div[2]/div[2]/div/span[4]/text()")[0]
oneMovieList=[name,score,people]
print(oneMovieList)
# ['肖申克的救赎', '9.7', '1918400人评价']
# ['霸王别姬', '9.6', '1411167人评价']
# ..(省去20条记录)..
# ['怦然心动', '9.1', '1193590人评价']
# ['触不可及', '9.2', '677191人评价']
4.2.2 name,score,people无[0],有循环,存入一个元组中后逐一添加到一个大的元组中——打印每次循环的结果
import requests
from lxml import etree
url="https://movie.douban.com/top250"
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}
html = requests.get(url, headers=header).text
selector=etree.HTML(html)
lis=selector.xpath('//ol[@class="grid_view"]/li')
allMovieList=[]
for oneSelector in lis:
name=oneSelector.xpath("div/div[2]/div[1]/a/span[1]/text()")
score=oneSelector.xpath("div/div[2]/div[2]/div/span[2]/text()")
people=oneSelector.xpath("div/div[2]/div[2]/div/span[4]/text()")
oneMovieList=[name,score,people]
allMovieList.append(oneMovieList)
print(allMovieList)
# [[['肖申克的救赎'], ['9.7'], ['1918400人评价']]]
# [[['肖申克的救赎'], ['9.7'], ['1918400人评价']], [['霸王别姬'], ['9.6'], ['1411167人评价']]]
# [[['肖申克的救赎'], ['9.7'], ['1918400人评价']], [['霸王别姬'], ['9.6'], ['1411167人评价']], [['阿甘正传'], ['9.5'], ['1458464人评价']]]
4.2.3 name,score,people有[0],有循环,存入一个元组中后逐一添加到一个大的元组中——打印每次循环的结果
import requests
from lxml import etree
url="https://movie.douban.com/top250"
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}
html = requests.get(url, headers=header).text
selector=etree.HTML(html)
lis=selector.xpath('//ol[@class="grid_view"]/li')
allMovieList=[]
for oneSelector in lis:
name=oneSelector.xpath("div/div[2]/div[1]/a/span[1]/text()")[0]
score=oneSelector.xpath("div/div[2]/div[2]/div/span[2]/text()")[0]
people=oneSelector.xpath("div/div[2]/div[2]/div/span[4]/text()")[0]
oneMovieList=[name,score,people]
allMovieList.append(oneMovieList)
print(allMovieList)
# [['肖申克的救赎', '9.7', '1918400人评价']]
# [['肖申克的救赎', '9.7', '1918400人评价'], ['霸王别姬', '9.6', '1411167人评价']]
# [['肖申克的救赎', '9.7', '1918400人评价'], ['霸王别姬', '9.6', '1411167人评价'], ['阿甘正传', '9.5', '1458464人评价']]
4.3.1 name,score,people无[0],有循环,存入一个元组中后逐一添加到一个大的元组中——打印最终结果
import requests
from lxml import etree
url="https://movie.douban.com/top250"
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}
html = requests.get(url, headers=header).text
selector=etree.HTML(html)
lis=selector.xpath('//ol[@class="grid_view"]/li')
allMovieList=[]
for oneSelector in lis:
name=oneSelector.xpath("div/div[2]/div[1]/a/span[1]/text()")
score=oneSelector.xpath("div/div[2]/div[2]/div/span[2]/text()")
people=oneSelector.xpath("div/div[2]/div[2]/div/span[4]/text()")
oneMovieList=[name,score,people]
allMovieList.append(oneMovieList)
print(allMovieList)
# [[['肖申克的救赎'], ['9.7'], ['1918400人评价']], [['霸王别姬'], ['9.6'],...... ['1411167人评价']], [['阿甘正传'], ['9.5'], ['1458464人评价']]]
4.3.2 name,score,people有[0],有循环,存入一个元组中后逐一添加到一个大的元组中——打印最终结果
import requests
from lxml import etree
url="https://movie.douban.com/top250"
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}
html = requests.get(url, headers=header).text
selector=etree.HTML(html)
lis=selector.xpath('//ol[@class="grid_view"]/li')
allMovieList=[]
for oneSelector in lis:
name=oneSelector.xpath("div/div[2]/div[1]/a/span[1]/text()")[0]
score=oneSelector.xpath("div/div[2]/div[2]/div/span[2]/text()")[0]
people=oneSelector.xpath("div/div[2]/div[2]/div/span[4]/text()")[0]
oneMovieList=[name,score,people]
allMovieList.append(oneMovieList)
print(allMovieList)
# [['肖申克的救赎', '9.7', '1918400人评价'], ['霸王别姬', '9.6', '1411167人评价'],...... ['触不可及', '9.2', '677191人评价']]
进入Debug调试:
第一次循环:
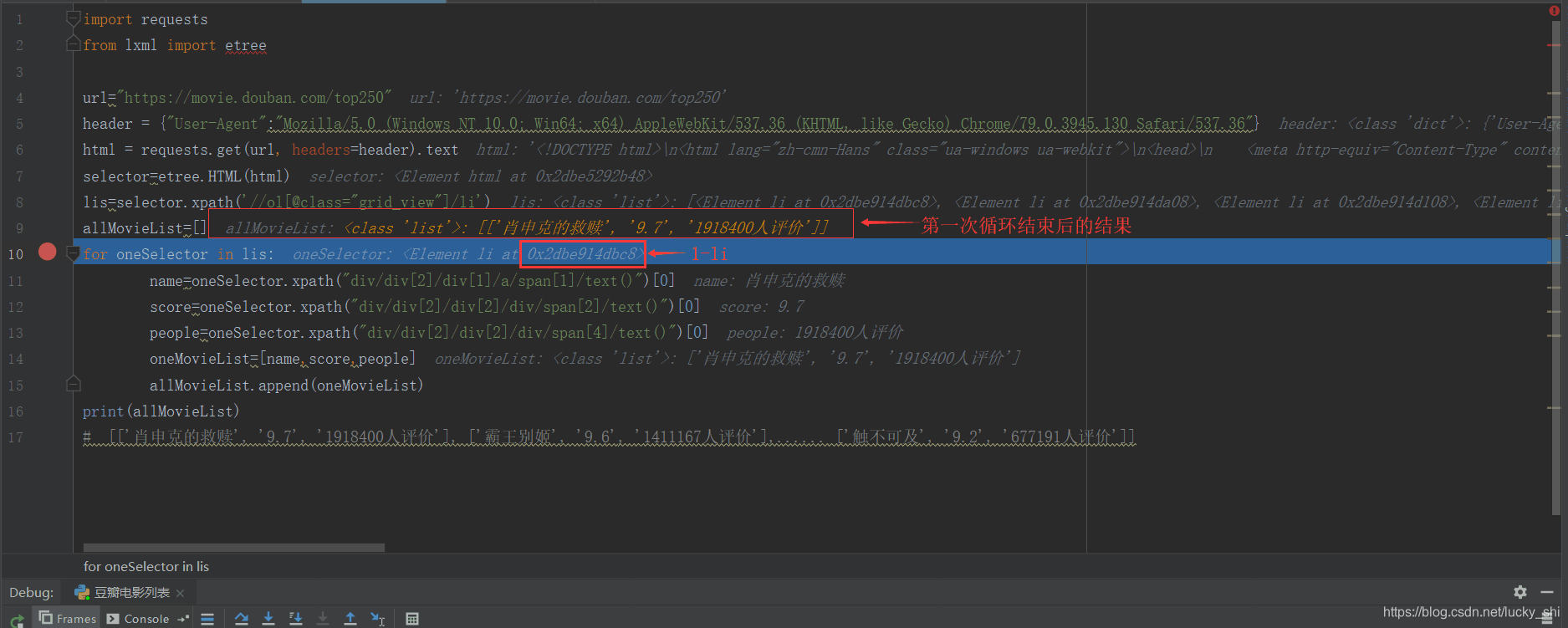
第二次循环:
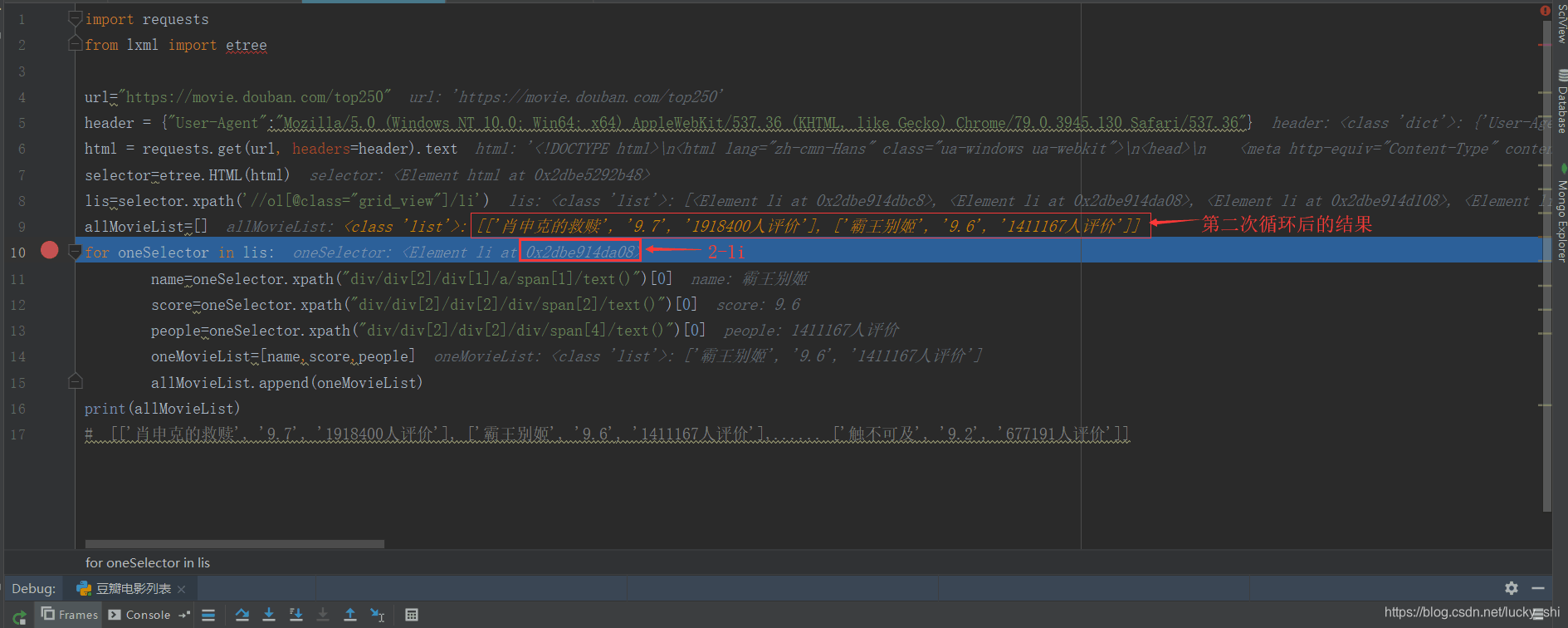
第三次循环:
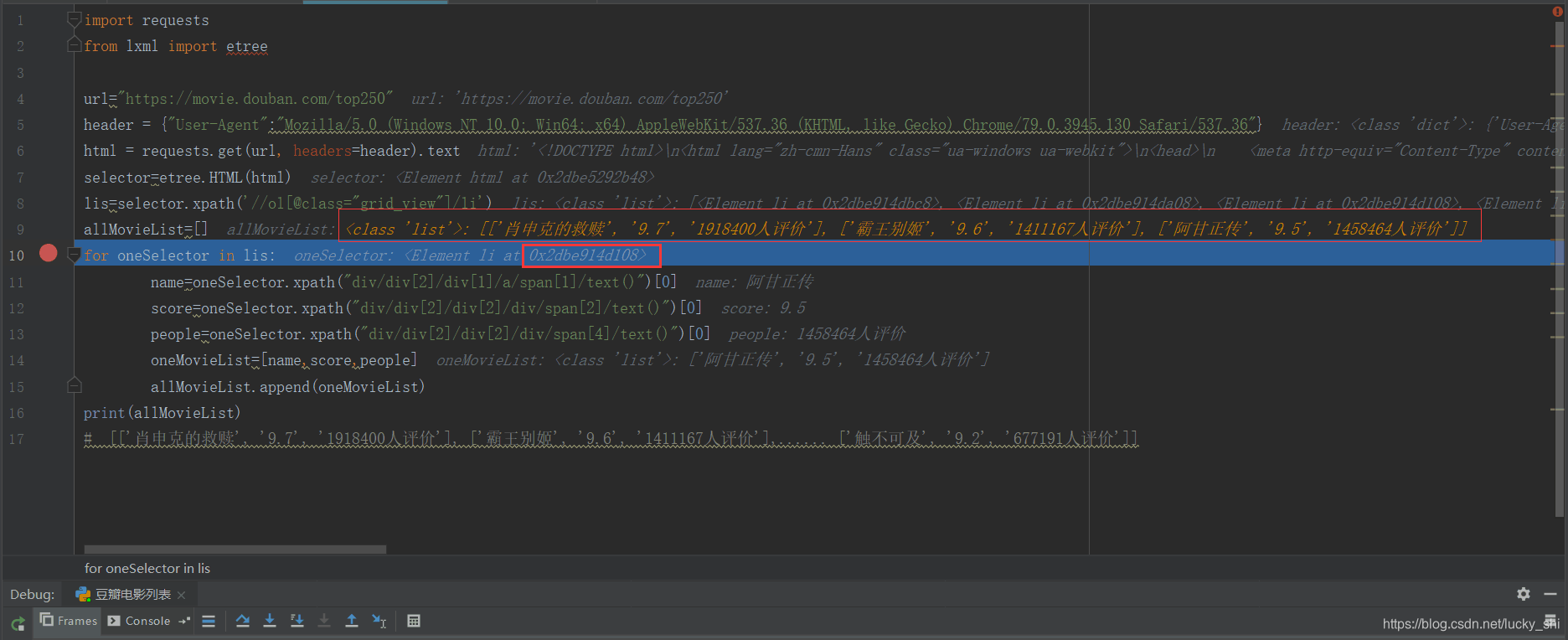
依次类推得出最总结果。
总结:
无[0]时返回的是一个列表,有[0]时返回的是列表中的第一个元素,熟练运用Debug模式进行调试。
