Python爬虫-xpath
说明
关于Python爬虫请求数据方面的知识点基本讲完,但请求到数据之后呢?
当然是提取数据,抓出对我们有价值的内容是整个爬虫流程的关键步骤之一。现下流行方法有:xapth,BeautifulSoup,正则,PyQuery。如无意外,我会一一笔记下来。今天说说我的最爱吧。
——xpath
再说明
一般情况下,我们爬到的是整个静态网页页面,得到的是html源码,包含各种标签。但那些标签并非我们想要,如:
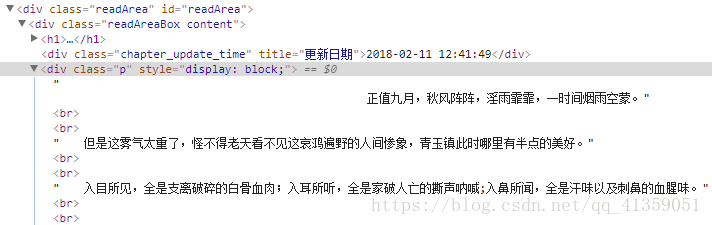
我们只需要里边的文字,这种时候就可以xpath了。如上所说,类似的解决方法包括正则以及BeautifulSoup,前者难度较大,后者广受追捧。从解析速度上说,正则最快,xpath次之,BeautifulSoup再次之;从上手难度来说,BeautifulSoup最易,xpath次之,正则再次之。综合考虑,我偏爱xpath。也有人推崇PyQurey,认为比起繁琐的“美丽汤”语法,它短小精悍,而且如果使用者是前端工程师,掌握起来不需要耗费任何学习成本。这大概因为PyQurey的语法源于JQurey吧。
插件推荐
基于chrome浏览器的插件,它可以让我们提前看到提取效果,使用快捷键ctrl+shift+x

语法讲述
只说常用的:
1. /从根节点开始
2. //从任意位置开始
可以这样理解两个的区别,前者从顶端开始,且前者的左右必须是紧邻的标签;后者任意位置开始,且左右间的标签允许存在间隔
3. div/p div标签下的p标签
4. 提取标签中某个属性的值 div/img/@某个属性
5. 确定带有a属性且值为b的div标签//div[@a="b"]
6. 如果需要取出标签中的文字//span/text()
7. 模糊查询 //div/a[contains(@某属性, "对应属性的部分值")]
8. 多个相同标签用索引方式定位,表示div下div下的第3个a标签 ://div/div/a[3]
举栗子
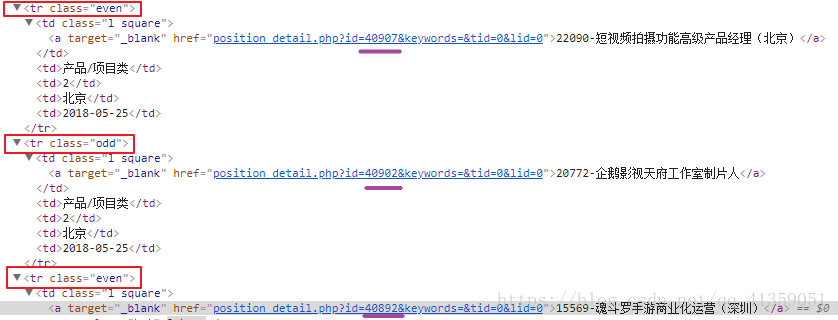
- 以腾讯社招为例
可以发现tr的class值不同,而属性href只有数字部分不同,此时想要获取a标签中的字符串两种方法
a) 模糊查询
//tbody/tr/td/a[contains(@href, "position")]
b) “|”或
//tbody/tr[@class="even"]//a | //tbody/tr[@class="odd"]//a


代码里使用
from lxml import etree
# 实例化一个对象
selector = etree.HTML(response.text)
# 通过选择器进行筛选
result = selector.xpath("规则")说明:返回的result是列表类型,如果没有提取到符合规则的信息会返回空列表
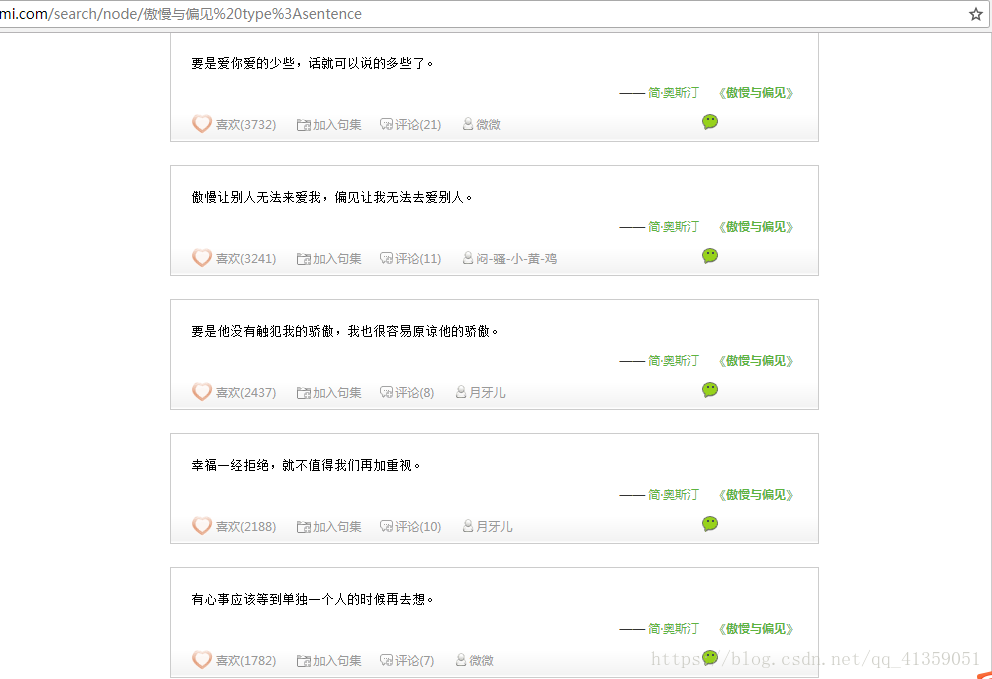
实战句子迷
页面呈现如下,要求:获取每个句子,以及“喜欢”量,以及“评论”数
import requests
from lxml import etree
import json
url = "http://www.juzimi.com/search/node/%E5%82%B2%E6%85%A2%E4%B8%8E%E5%81%8F%E8%A7%81%20type%3Asentence"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
"Referer": "http://www.juzimi.com/search/node/%E5%82%B2%E6%85%A2%E4%B8%8E%E5%81%8F%E8%A7%81%20type%3Asentence",
}
def get_html(params):
"""
获取html页面
"""
try:
response = requests.get(url, params=params, headers=headers)
response.raise_for_status()
print(response.url)
print(response.status_code)
except :
print("connection error")
return None
response.encoding = response.apparent_encoding
return response.text
def parse_html(html):
"""
处理html页面,提取需要数据
"""
data = {}
selector = etree.HTML(html)
# 构建xpath规则
ruler = '//div[@class="view-content"]/div[contains(@class, "views-row")]'
roots = selector.xpath(ruler) #拿到根对象的列表,可以对这个列表中的成员继续xpath
# 由于这次是在win上测试,所以文件打开设定编码方式为utf-8
with open("sentence.txt", "a", encoding="utf-8") as ob:
for root in roots:
try:
data["sentence"] = root.xpath('./div/div[1]/a/text()')[0] #句子
data["loved"] = root.xpath('./div/div[3]/a/text()')[0] # 喜欢
data["comment"] = root.xpath('./div/div[5]/a/text()')[0] # 评论
except IndexError:
# 处理第一页的杂质问题
continue
# 关闭默认的ascii编码
ob.write(json.dumps(data, ensure_ascii=False))
ob.write("\n")
def main():
for i in range(4):
if i:
params = {"page":i}
else:
# 第一页的url地址比较特别,所以单独处理
params ={}
html = get_html(params)
if html:
parse_html(html)
print("结束")
if __name__ == "__main__":
main()结果:
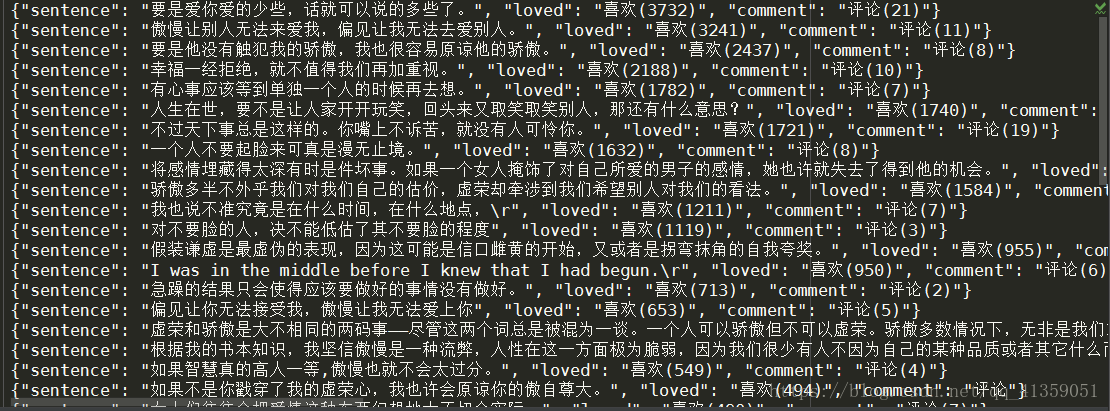
需要的总结:
原本没打算总结的。原本只是做一次用xpath提取数据的示范。以为像句子迷这样的小网站爬起来会很容易,确实是,却也不是。
网页静态呈现,需要的数据都可以通过xpath直接拿到。主要遇到的问题是该网站设置了重定向,就是说直接访问我设置的url地址时,会被重定向到另一个地址去。根据xpath没拿到返回值这一现象,我打印了实际请求地址,结果显示的确被重定向了。我当然第一反应关闭了 get请求中的重定向开关。这之后拿不到数据,状态码返回302。特地百度一下,302是暂时性重定向的意思,它的危害性比较大,主要是可能被黑客利用进行url劫持,也可能恶意刷网站排名,被建议尽量不用或少用。
正确处理方式:请求报文头中一定要加Referer值。老实说,之前也爬过一些大型网站,Referer值从来不带的,这次是长知识了。