最近要找工作,个人比较心仪的岗位当然是DL&CV,大概是因为硕士期间对这些研究的比较多。有时接触的东西多了,但是很多看了一次就忘记了,就算是看过多次的也留不下多少记忆。原因当然是没有系统地进行总结过,没有把知识点串联起来。
第一次接触到机器学习(同时也是第一次听说机器学习),还是在大四那年寒假左右,大概是2016年初。当时好像是在别人的百度云盘分享里面看到了一本叫做《机器学习实战》的书。那时候只是觉得那玩意很厉害,为什么自己现在才发现?而且里面推荐使用的语言是Python,正好那时也接触了Python这门语言,也算是入门了。可是当时并没有过多地去研究机器学习。不过当时的本科毕业设计做的是与图像相关的,图像视觉安全质量评估。那时候也是刚刚接触图像。之前没有接触过。那个时候我是用的OpenCV和C++做的毕业设计。而其中用到的核心函数大概就是OpenCV自带的Canny函数了。当时其实可以选择用Matlab实现的,但考虑到总总原因,还是选择了C++,因为自己当时对Matlab不感冒(现在也是,摊手笑哭)。毕竟C佳佳要显得高大上些。这个毕业设计是跟着一个博士师兄做的。实现他发表的一篇论文里面的算法。大概就是提取图像的边缘特征以及纹理特征,然后算出图像的视觉安全得分。好了,闲话大概就到这个地方吧。
后面再次接触机器学习还是研一上学期,那时候实验室开了一门讨论班,讲的就是机器学习,那时用的教材是CMU的Mitchell写的黑皮《机器学习》。自己也参与讲了几节。研一寒假(2017年初),在别人的推荐下,入手了李航博士的那本《统计学习基础》,当时还把书带回了家,希望寒假能够读完,遗憾的是第一页都没有翻开过(今年寒假也带回家了,一样的没有读完)。后来研一下学期,学习了那门课,用的是西瓜书。研二上学期学习了花书《深度学习》(17年暑假刚刚出版),也讲了机器学习那个部分,以及深度学习的卷积神经网络(CNN)。同时研二上学期也开始写小论文,涉及到的就是深度学习和计算机视觉。具体是使用卷积神经网络对图像进行质量评估(没错,整个研究生期间,入的就是这个坑)。所以对于机器学习和深度学习、计算机视觉还是有很多要总结的。
1、机器学习
关于机器学习,其实它和统计学是息息相关的。机器学习的一些方法都可以归纳为:模型+策略+算法。机器学习分为监督学习、非监督学习和半监督学习。而任务可以分为:分类和回归。模型类别可以分为:生成模型和判别模型。这些都是最基本的概念。
分类或是回归,无非是通过计算 或是 进行预测的。其中, 为样本, 为具体的分类或回归预测结果,而 给出的是一个概率,它其实更多地是用来分类的。
从最简单的感知机模型说起(它属于二类分类线性分类模型)。它的模型其实很简单,就是一个线性模型: ,其中 为权重,而 为偏置。如果仔细观察的话。你会发现,后面的很多模型都是基于此。比如逻辑回归模型,支持向量机(SVM),神经网络(NN)。
机器学习的任务就是进行学习,所以它需要数据。而且数据量越大越好。数据集分为训练集和测试集,当然也有细分出验证集的。对于训练集,假设我们有N个样本。我们把第 个样本记作 ,而对于每一个样本,它都有很多个属性组成。再假设每一个样本有n个属性,记一个样本的第 个属性为 。
那么刚刚的线性模型其实就是: ,我们可以让 的取值为 ,当右边计算结果为负,取-1;当结果为正,取+1。分别代表正类和负类。其实它可以简化写成: 。好的,有了模型,下面我们来看策略,所谓策略指的是,我们怎么来评判这个模型的好坏,那么我们自然会想到,看它预测的准确性了。所以就有了损失函数。用它来衡量模型的好坏。
机器学习中常见的损失函数有以下几种,注意的是:在设计损失函数的时候,一定要遵循越是不准确,其损失函数的值越大,我们在后面用算法进行优化的过程其实就是找到最优解(或次优解),使得损失函数最小。
0-1损失函数:
绝对损失函数:
平方损失函数:
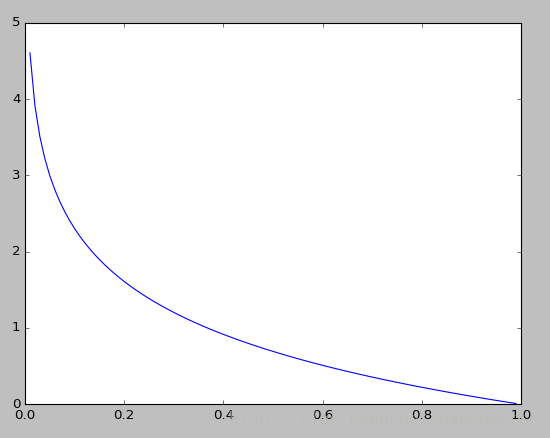
负对数(对数似然)损失函数:
,这个地方我们稍微考虑一下,为什么要加负号?
因为它给出的是一个概率。概率越大,说明准确率越高,也就是损失值应该越小。见下图:
对于感知机而言。我们可以定义误分类点到分离平面的距离作为损失函数值。
。
2.决策树
这是一个判别模型,树型模型。
3.logistic模型
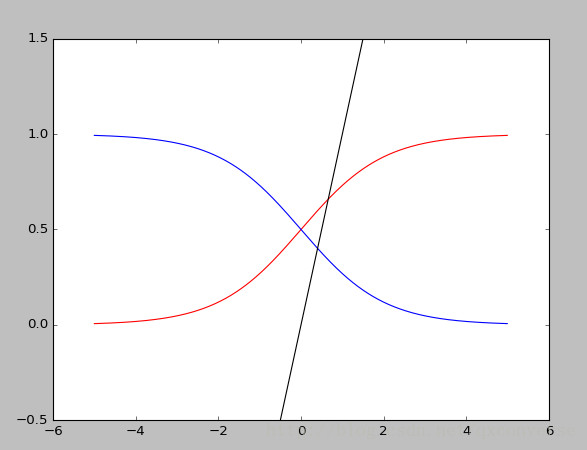
这是一个对数线性模型,函数定义为:
。这是一个sigmoid函数。它具有一个很好的性质
,在后面的深度学习中,它不再被用作激活函数了,原因就是因为它会导致梯度消失。
其中红线和蓝线分别为
取0和1的情况。而黑线为对数几率。可以看到它其实是线性的。
那么接下来,我们讨论该模型用什么损失函数。谈到这里。不得不提一下大名鼎鼎的交叉熵函数。其实这个我们不用去死记硬背,慢慢推导。从最原始的开始来。首先我们会计算
这个线性公式。接着把它带入到sigmoid函数中去。那么有:
现在我们来计算它的损失函数,即真实值
与预测值的偏离程度。对于单个样本,当
时,
越大,说明越准确,所以取个负对数为
;当
时,
越大,说明越准确,所以取个负对数为
。再把它们相加,为什么可以相加,因为
与
非0即1,所以不会影响到损失函数。
综合有:
而对于所有的N个样本,只需要求和再平均即可:
现在回过头来,发现很容易把机器学习和深度学习中的一些东西混淆起来,比如
1。reLU函数是干嘛的,它在机器学习里面有涉及到吗?貌似在机器学习里面只有LR中涉及到Sigmoid这个激活函数。
2。关于正则化,它会不会出现在神经网络中的任意一层,还是说只是在最后的输出层。
3。损失函数呢?机器学习中的损失函数和神经网络中损失函数,分别用在什么时候?
4。batch normalization,这个东西的提出是在2015年,那么最新的keras、caffe等框架有对应的实现吗?还有它为什么是放在激活层前面,而不是后面。正常思路,应该是在进入下一层之前,而如果放在激活层前面的话,已经统一化了,不是又被激活函数搞乱了吗?
还是让我们回到原始点。机器学习是一块比较大范围的领域。事实上,深度学习属于机器学习的一部分,对于神经网络,如果层比较深的话,就把它叫做深度学习了。深度学习也叫作特征学习。
有了这一宏观认识后,再来看看机器学习里面到底有什么。首先机器学习的任务是进行学习,然后给出预测。而常见的预测无非就是回归与分类。分类,顾名思义就是给出一个样本,预测它属于哪一类。而回归,就是给出一个样本,预测它的估计值,这是一个连续的值。而分类则是离散的。事实上,在某些情况下,回归也可以转换成分类。例如,如果对一个产品的星级进行预测,使用5个独立的分类器来对1-5星进行打分的效果一般比使用一个回归损失要好很多。好了,这个是题外话。对于机器学习,分为监督学习、半监督学习和无监督学习。目前最常见的还是监督学习。即给出样本的标签值,即它的
值。在机器学习中,有很多种模型可以用来学习预测。拿分类来说,常见的有:
1。感知机分类(它和svm在线性可分的情况下极其相似)
2。逻辑回归(别被它的名称误导,它其实是用于分类的。而且属于对数线性二元分类器)
这个时候,有必要扩充一下:在深度学习中经常用到的softmax分类器是它的一般情况。也就是说softmax分类用于多分类,而逻辑回归为二分类。它们都是基于sigmoid函数的,而它们的损失函数,都是基于交叉熵损失函数(负对数似然函数)。
3。SVM(支持向量机)
它既可以做分类,也可以做回归。它基于最大间隔化。其实也可以理解为带正则化的合页损失函数的最小化。
4。决策树
5。朴素贝叶斯分类
6。K-近邻分类
主要就是以上几种。其实它们是相互联系的。都是基于统计理论。模型和策略联系紧密。后面有机会再谈谈它们与统计的关系。
其实我在上面故意避开了神经网络。之所以避开,就是因为把它放在深度学习中来讲。神经网络同样地,也可以做分类和回归。它定义了很多层,每一层由若干个神经元组成。这样就形成了一个网络。而对于一个简单的神经元。它有输入,有输出。权重和输入进行内积,再加上一个偏置,就计算出了一个结果,后面再加上一个激活函数(非线性的,为什么不用线性的?因为用线性的就和一般的线性方法没有区别了。使用非线性为的是多样化。理论上可以模拟出任意的函数)。
重点来了。激活函数只出现在神经网络(深度学习)中,在一般的机器学习(除了神经网络)中,是不会出现这个概念的。而激活函数又会有很多种。常见的有sigmoid函数,tanh函数,softplus函数,ReLu函数,maxout函数等等。稍加联系,我们就会发现:逻辑回归,其实就是一个单层(只有一个隐藏层)的以sigmoid函数作为激活函数的神经网络。
在神经网络中,我们不会使用线性的激活函数,而是使用非线性的,而sigmoid就是过去经常使用到的一个,但是由于它会导致梯度消失以及它的非零对称性质,导致不再使用它。tanh都要比它好一些。更多地是使用Relu函数等其它改进的函数作为激活函数。
那么还有一个问题,激活函数是不是要用在神经网络中的任意一层上。理论上是这样的,但是在深度学习的某些网络中,这不是必须的。也就是说,在某一层中,你可以不使用激活函数。甚至可以不使用偏置。这些在keras的实现中可以发现。
关于前向传播、后向传播与梯度下降,也经常混淆。其实前向传播和后向传播只是神经网络所特有的概念。相信在机器学习中(这里我说的机器学习默认不包含神经网络,因为我现在的目的就是区分它们中容易混淆的地方)并未出现到。再看看梯度下降。是不是很熟悉。其实它是机器学习中的概念。当然深度学习中也会用到。那么区别在哪儿呢?我们说机器学习有了模型和策略之后,剩下的就是如何求出最优的参数,使得模型效果最好(泛化能力强)。梯度下降法就是优化方法中的一种。它在更新参数的时候,始终沿着梯度下降最快的方向走。而前向传播与后向传播,可以理解为神经网络中的数据流走向。前向传播,顾名思义,就是从输入层开始一层一层地往前走,计算数值。最后输出。而后向传播呢?它是为了计算梯度的。从输出开始一层一层地计算导数(梯度),它是反方向传播的。而这些梯度的计算就是为了配合梯度下降法。那么具体是什么呢?这里就不得不提到损失函数。最优化是针对损失函数来优化的。而不是优化模型输出的值。也就是说,梯度是以损失函数的值来计算的。损失函数衡量的就是预测值与真实值的不接近程度。如果预测值与真实值相差很大,说明模型预测的效果不好,于是需要求得损失函数的最小值。于是用到了梯度下降法。
在机器学习中常见的损失函数包括:0-1损失函数(在kNN中用到过),绝对值损失函数(L1损失,mean_absolute_error或MAE,通常用在回归任务中),平方差损失函数(L2损失,mean_squared_error或mse,通常用在回归任务中),负对数似然损失函数(binary_crossentropy,交叉熵损失函数,用在逻辑回归,而categorical_crossentropy:亦称作多类的对数损失,用在softmax回归中),合页损失函数(hinge,主要用在SVM二分类中):
或
多分类合页损失函数(categorical_hinge,主要用在SVM多分类中, 为超参数)
所以看到了吧。要优化的是这些损失函数计算出来的值。真实的优化目标函数是在各个数据点得到的损失函数值之和的均值。
现在再回到深度学习的神经网络中去。当到了最后的输出层,是什么样子的?在输出层,我们会得出最后的结果,如果是分类,那么最后一层就会有多个节点;而如果是回归,就只有一个节点。后面的事情,就交给损失函数和优化器了。
这个时候,重点来了,为什么神经网络可以使用那么多的损失函数,而这些损失函数都来自于某些机器学习模型的。所以,我们要记住,损失函数是独立于模型的,就像优化算法也是独立于模型的一样。也就是说,那些损失函数不是某个模型特有的。比如,交叉熵损失既可以用于逻辑回归,softmax回归,也可以用于神经网络。而合页损失函数既可以用于SVM,当然也可以用于神经网络。
到了这里,相信大家对模型+策略+算法有了更加深入的理解了。从而就不会再把机器学习和深度学习中的某些东西弄混淆了。其实,只需要多思考一些为什么,我们往往自己也就能得出原因了。当然以上的内容其实并不全面。深度学习中除了一般的深度神经网络,还有CNN、RNN等。但是把最基本的东西弄清楚了,其它的也就可以理解了。