Word2Vec模型原理
0.什么是Word2Vec?
- 一个进行词嵌入的开源工具
2013年,Google开源了一款用于词向量计算的工具——word2vec,引起了工业界和学术界的关注。首先,word2vec可以在百万数量级的词典和上亿的数据集上进行高效地训练;其次,该工具得到的训练结果——词向量(word embedding),可以很好地度量词与词之间的相似性。word2vec是一个计算word vector的开源工具。
下面会介绍一些Word2Vec的准备知识。
0.1 Ngram模型
- 如何计算连续词语在文档出现的概率
计算一段文本序列在某种语言下出现的概率?之所为称其为一个基本问题,是因为它在很多NLP任务中都扮演着重要的角色。例如,在机器翻译的问题中,如果我们知道了目标语言中每句话的概率,就可以从候选集合中挑选出最合理的句子做为翻译结果返回。
统计语言模型给出了这一类问题的一个基本解决框架。对于一段文本序列
S=w1,w2,…,wT
它的概率可以表示为:
P(S)=P(w1,w2,…,wT)=∏t=1Tp(wt|w1,w2,…,wt−1)
即将序列的联合概率转化为一系列条件概率的乘积。问题变成了如何去预测这些给定previous words下的条件概率:
p(wt|w1,w2,…,wt−1)
由于其巨大的参数空间,这样一个原始的模型在实际中并没有什么用。我们更多的是采用其简化版本——Ngram模型:
p(wt|w1,w2,…,wt−1)≈p(wt|wt−n+1,…,wt−1)
常见的如bigram模型(N=2)和trigram模型(N=3)。事实上,由于模型复杂度和预测精度的限制,我们很少会考虑N>3的模型。
我们可以用最大似然法去求解Ngram模型的参数——等价于去统计每个Ngram的条件词频。
0.2 Ngram的问题及Distributed Representation
Ngram模型有很大的局限性。首先,由于参数空间的爆炸式增长,它无法处理更长程的context(N>3)。其次,它没有考虑词与词之间内在的联系性。例如,考虑"the cat is walking in the bedroom"这句话。如果我们在训练语料中看到了很多类似“the dog is walking in the bedroom”或是“the cat is running in the bedroom”这样的句子,那么,即使我们没有见过这句话,也可以从“cat”和“dog”(“walking”和“running”)之间的相似性,推测出这句话的概率[3]。然而, Ngram模型做不到。
这是因为,Ngram本质上是将词当做一个个孤立的原子单元(atomic unit)去处理的。这种处理方式对应到数学上的形式是一个个离散的one-hot向量(除了一个词典索引的下标对应的方向上是1 ,其余方向上都是0)。例如,对于一个大小为5的词典:{“I”, “love”, “nature”, “luaguage”, “processing”},“nature”对应的one-hot向量为:[0,0,1,0,0] 。显然,one-hot向量的维度等于词典的大小。这在动辄上万甚至百万词典的实际应用中,面临着巨大的维度灾难问题(The Curse of Dimensionality)

于是,人们就自然而然地想到,能否用一个连续的稠密向量去刻画一个word的特征呢?这样,我们不仅可以直接刻画词与词之间的相似度,还可以建立一个从向量到概率的平滑函数模型,使得相似的词向量可以映射到相近的概率空间上。这个稠密连续向量也被称为word的distributed representation(分布式表示)。
0.3 VSM与统计语意假说
这里有两个代表性派别,词袋假说:主张词频代表文档主题(词出现的次数)。分布假说:相同上下文的词有相近意思。
VSM是基于一种Statistical Semantics Hypothesis:语言的统计特征隐藏着语义的信息(Statistical pattern of human word usage can be used to figure out what people mean)。例如,两篇具有相似词分布的文档可以被认为是有着相近的主题。这个Hypothesis有很多衍生版本。其中,比较广为人知的两个版本是Bag of Words Hypothesis和Distributional Hypothesis。前者是说,一篇文档的词频(而不是词序)代表了文档的主题;后者是说,上下文环境相似的两个词有着相近的语义。后面我们会看到,word2vec算法也是基于Distributional的假设。
那么,VSM是如何将稀疏离散的one-hot词向量映射为稠密连续的Distributional Representation的呢?
简单来说,基于Bag of Words Hypothesis,我们可以构造一个term-document矩阵A:矩阵的行Ai,:: 对应着词典里的一个word;矩阵的列A:,j对应着训练语料里的一篇文档;矩阵里的元素Ai,j代表着wordwi在文档Dj中出现的次数(或频率)。那么,我们就可以提取行向量做为word的语义向量(不过,在实际应用中,我们更多的是用列向量做为文档的主题向量)。
类似地,我们可以基于Distributional Hypothesis构造一个word-context的矩阵。此时,矩阵的列变成了context里的word,矩阵的元素也变成了一个context窗口里word的共现次数。
注意,这两类矩阵的行向量所计算的相似度有着细微的差异:term-document矩阵会给经常出现在同一篇document里的两个word赋予更高的相似度;而word-context矩阵会给那些有着相同context的两个word赋予更高的相似度。后者相对于前者是一种更高阶的相似度,因此在传统的信息检索领域中得到了更加广泛的应用。
不过,这种co-occurrence矩阵仍然存在着数据稀疏性和维度灾难的问题。为此,人们提出了一系列对矩阵进行降维的方法(如LSI/LSA等)。这些方法大都是基于SVD的思想,将原始的稀疏矩阵分解为两个低秩矩阵乘积的形式。
1.Word2Vec用来干什么?
1.1词嵌入
发现很多教程直接上来说one-hot,分布式表示,然后给word2Vec数学推导式,但就是不说Word2Vec用来干什么,只见树木,不见森林,这让人感觉很迷惑。而且根据其名字,新手很容易认为其是语言的一种数学表达技巧,很多问题会陷入迷茫。根据看的资料,这里说一下Word2Vec是干什么的。
- Word2Vec表示一种词语到数学空间的转换,也称词嵌入。
数学模型,输入和输出都是数值,如果要处理非数值数据,则需要将该数据映射到一个数学空间中。在NLP中,词语映射到数学空间的过程也叫词嵌入。
详细解释:
NLP 里的词语,是人类的抽象总结,是符号形式的(比如中文、英文、拉丁文等等),所以需要把他们转换成数值形式,或者说——嵌入到一个数学空间里,这种嵌入方式,就叫词嵌入(word embedding),而 Word2vec,就是词嵌入( word embedding) 的一种。
总结:Word2vec是词嵌入( word embedding) 的一种
1.2 神经网络权重与降维
- Word2Vec是如何进行映射的?这里主要借助神经网络中的权重。
在 NLP 中,把 x 看做一个句子里的一个词语,y 是这个词语的上下文词语,那么这里的 f,便是 NLP 中经常出现的『语言模型』(language model),这个模型的目的,就是判断 (x,y) 这个样本,是否符合自然语言的法则,更通俗点说就是:词语x和词语y放在一起,是不是人话。
Word2vec 正是来源于这个思想,但它的最终目的,不是要把 f 训练得多么完美,而是只关心模型训练完后的副产物——模型参数(这里特指神经网络的权重),并将这些参数,作为输入 x 的某种向量化的表示,这个向量便叫做——词向量
总结:Word2Vec借助预测模型,将模型的权重参数作为映射矩阵,将输入词语的onehot编码映射到一个维度更小的空间中。
因此Word2Vec本质为将维,即把词语从 one-hot encoder 形式的表示降维到 Word2vec 形式的表示。
1.3 Word2Vec两种算法及技巧
Word2Vec包括两种算法,两种训练技巧方法。
- 两种算法:CBOW和SK。
- 两种训练优化方法:负采样和分层Softmax。
两种算法:
1.推导缺失单个词,这时候叫CBOW(Continuous Bag-of-Words),即根据上下文,推导中间缺失的一个词。
2.推导上下文,这时候叫SG模型(Skip-Gram),即输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。
由于推导上下文,需要我们做出更多推测,因此SG在大型语料库中表现更好。
总结:CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。这里有个形象的解释:CBOW 可以理解为一个老师教多个学生,skip-gram 可以理解为一个学生被多个老师教。
- 两种训练优化方法:
分层Softmax:
Hierarchical Softmax是一种对输出层进行优化的策略,输出层从原始模型的利用softmax计算概率值改为了利用Huffman树计算概率值。一开始我们可以用以词表中的全部词作为叶子节点,词频作为节点的权,构建Huffman树,作为输出。从根节点出发,到达指定叶子节点的路径。Hierarchical Softmax正是利用这条路径来计算指定词的概率,而非用softmax来计算。
- [优化一]
把 N 分类问题变成 log(N)次二分类,利用哈夫曼树构造很多二分类(sigmoid);
( 使用原始的softmax计算,是N分类,N代表词典个数,所以softmax计算量非常大需要对N个分类下的各自输出值)
Hierarchical softmax的缺点就是:虽然我们使用huffman树代替传统的神经网络,可以提高模型训练的效率,但是如果我们训练样本中的中心词w是一个很生僻的词,那么就需要沿着huffman树往下走很多,因为越是高频的词,越是靠近根节点
- [优化二]
层次化softmax不必求神经网络隐藏层中的权值矩阵, 而是改求哈弗曼树中每个节点的权值向量, 这样就减少了计算
负采样:
这是Noise-Contrastive Estimation(简写NCE,噪声对比估计)的简化版本:把语料中的一个词串的中心词替换为别的词,构造语料 D 中不存在的词串作为负样本。在这种策略下,优化目标变为了:较大化正样本的概率,同时最小化负样本的概率;
- [优化]
在训练每个样本时, 原始神经网络隐藏层权重的每次都会更新, 而负采样只挑选部分权重做小范围更新
词汇表的大小决定了我们skip-gram 神经网络将会有一个非常大的权重参数,并且所有的权重参数会随着数十亿训练样本不断调整。negative sampling 每次让一个训练样本仅仅更新一小部分的权重参数,从而降低梯度下降过程中的计算量。
如果 vocabulary 大小为1万时, 当输入样本 ( “fox”, “quick”) 到神经网络时, “ fox” 经过 one-hot 编码,在输出层我们期望对应 “quick” 单词的那个神经元结点输出 1,其余 9999 个都应该输出 0。在这里,这9999个我们期望输出为0的神经元结点所对应的单词我们为 negative word. negative sampling 的想法也很直接 ,将随机选择一小部分的 negative words,比如选 10个 negative words 来更新对应的权重参数。
- 总结
hierarchical softmax
本质是把 N 分类问题变成 log(N)次二分类
negative sampling
本质是预测总体类别的一个子集
2.CBOW与SG算法
分两种模型解释
2.1 CBOW(Continuous Bag-of-Words)
我们都知道,模型的训练包括输入数据(训练数据),损失函数(loss)和优化方法,那么在CBOW中是如何进行的呢?
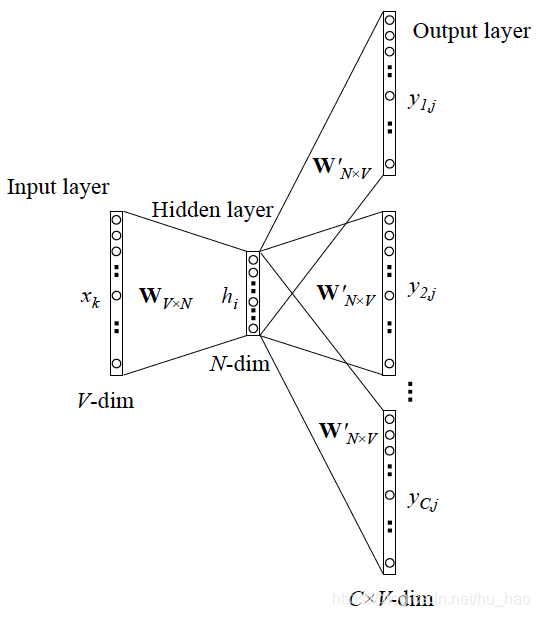
- 输入数据
1.模型的输入数据,是以onehot表示的。维数为V,上下文单词数为C.
2.所有onehot分别乘以共享的输入权重矩阵W. {VN矩阵,N为自己设定的数,初始化权重矩阵W}
注意这里W为权重矩阵,为V×N维,1×V的原数据与W相乘后,变为1×N,即为影藏层神经元个数。
3.影藏层输出,乘以输出权重矩阵W’ {NV},又变为1×V的向量了。(表示单词)
4.1×V向量,经过激活函数处理得到V-dim概率分布 {PS: 因为是onehot,其中的每一维都代表着一个单词}。
5.概率最大的index所指示的单词为预测出的中间词(target word)与true label的onehot做比较,误差越小越好(根据误差更新权重矩阵)。
CBOW的训练模型如图所示:

以上即是CBOW的工作过程。
2.2 Skip-Gram模型
1.首先我们选句子中间的一个词作为我们的输入词,例如我们选取“dog”作为input word;
2.有了input word以后,我们再定义一个叫做skip_window的参数,它代表着我们从当前input word的一侧(左边或右边)选取词的数量。如果我们设置skip_window=2,那么我们最终获得窗口中的词(包括input word在内)就是[‘The’, ‘dog’,‘barked’, ‘at’]。skip_window=2代表着选取左input word左侧2个词和右侧2个词进入我们的窗口,所以整个窗口大小span=2x2=4。另一个参数叫num_skips,它代表着我们从整个窗口中选取多少个不同的词作为我们的output word,当skip_window=2,num_skips=2时,我们将会得到两组 (input word, output word) 形式的训练数据,即 (‘dog’, ‘barked’),(‘dog’, ‘the’)。
小结:
Word2Vec模型具有以下特点:
- 1.拥有大规模语料库
- 2.词使用分布式向量表示
- 3.对于每一个文本,均有一个中心词和一个上下文。
- 4.使用相似度计算中心词和上下文的概率
参考
1.通俗理解word2vec
2.层次化softmax与负采样对比
3.[NLP] 秒懂词向量Word2vec的本质
4.NLP之——Word2Vec详解