Word2vec之CBOW 模型
CBOW模型流程举例
假设我们现在的语料库是这一个简单的只有四个单词的文本:
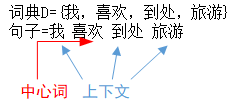
Step 1. 得到上下文词的one-hot向量作为输入,同时得到预期的输出one-hot向量(这个用来最后计算损失函数)。 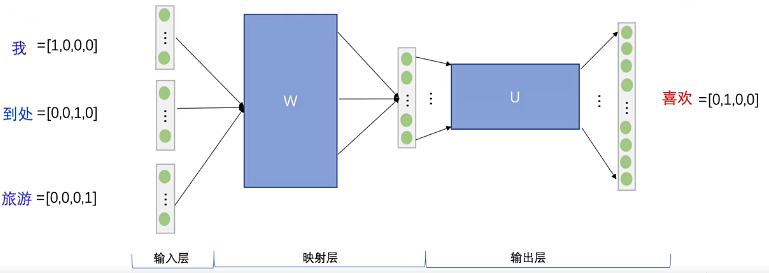
Step 2. 输入层每个词的one-hot与权重矩阵WVN相乘,得到对应的向量。(其实这就是对应词的词向量,矩阵的参数是网络通过训练得到的)。
V表示语料库中词的个数,即one-hot向量的维数是V。
N表示隐藏层神经元的数量,即希望最后得到的词向量维数为N。

得到每个词的词向量


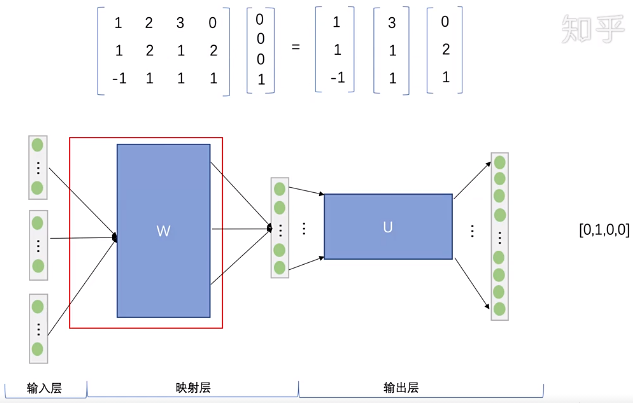
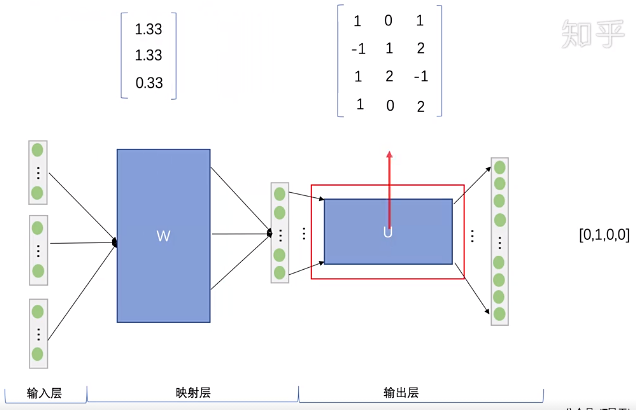
Step 3. 将得到的三个向量相加求平均,作为输出层的输入。
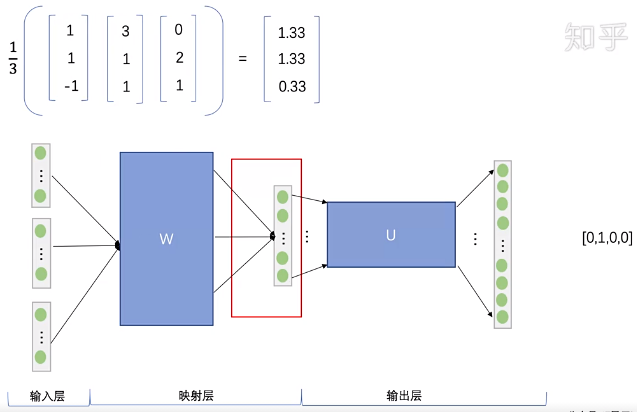
Step 4. 将向量与输出层的权重矩阵U相乘,得到输出向量。
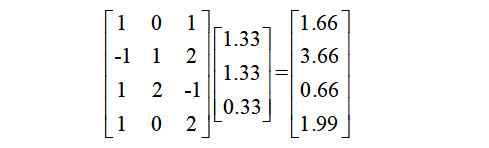
Step 5. 将softmax作用于输出向量,得到每个词的概率分布。
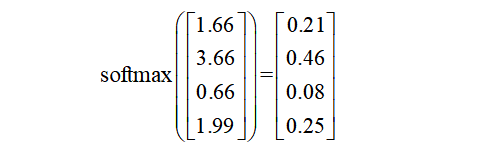
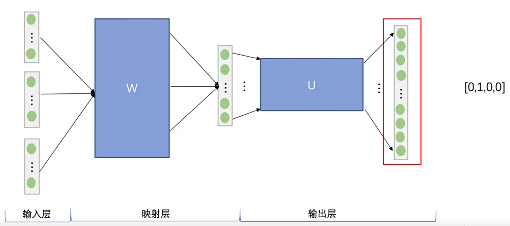
Step 6. 通过损失度量函数(如交叉熵),计算网络的输出概率分布与预期输出onehot向量的之间损失值。通过这个损失值进行反向传播,更新网络参数。
经过上述步骤的多次迭代后,矩阵W就是词向量矩阵,每个词通过one-hot查询词向量矩阵就能得到其对应的词向量。
总结
先来看着这个结构图,用自然语言描述一下CBOW模型的流程:

1.输入层:背景词的one-hot向量。
2.隐藏层:所有one-hot分别乘以输入权重矩阵W,再将所得的向量相加求平均作为隐藏层向量。
3.输出层:隐藏层向量乘以输出权重矩阵W’ 。 将softmax作用于输出向量,得到每个词的概率分布,概率最大的index所指示的单词为预测出的中心词。
它的隐藏层并没有激活函数,但是输出层却用了softmax,这是为了保证输出的向量是一个概率分布。
one-hot编码,就是有多少个不同的词,我就会创建多少维的向量。这样可能会造成维数爆炸。于是就出来了连续向量表示,word2vec就是将语料库中的词转化成向量,以便后续在词向量的基础上进行各种计算。word2vec的字、词向量,能够包涵语义信息,向量的夹角余弦能够在某种程度上表示字、词的相似度。