BM算法
BM算法的全程叫做Boyer-Moore,是工程上最常用且最高效的字符串匹配算法,有实验统计,它的性能是著名的KMP 算法的 3 到 4 倍。那么它是如何将性能提升的呢?
在上一篇博客中我介绍了BF算法和RK算法,其中也提到过如果想要优化字符串匹配的效率,就必须要减少不必要的比较,例如RK算法就是通过预匹配哈希值来完成了这一功能,但是我们也提到了,由于哈希冲突等原因,RK在最坏的情况下就会退化成BF算法。
基于上述问题的缺陷,BM、KMP(下一篇博客会写)等算法采用了大量滑动的机制来解决这一问题
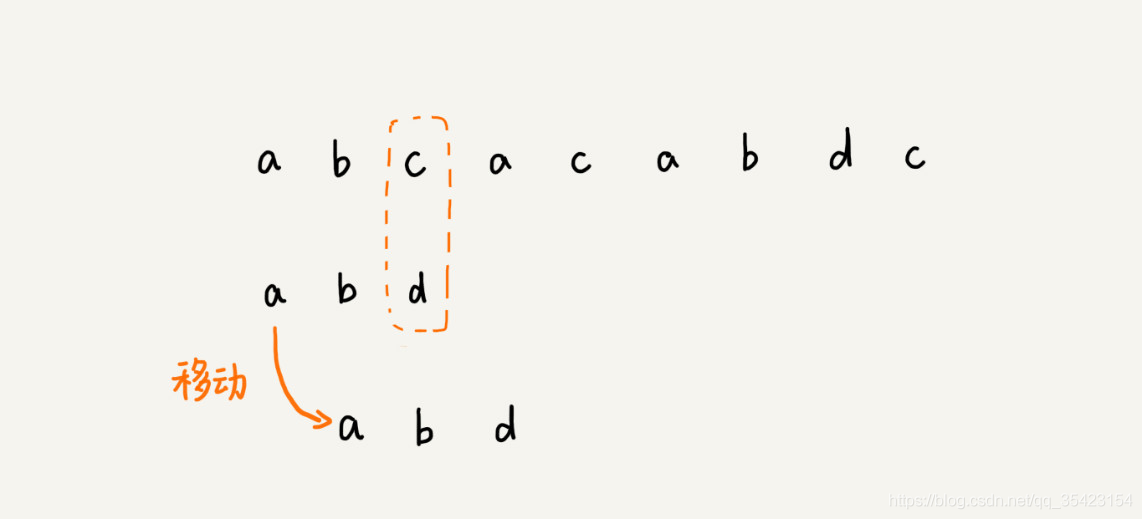
在RK和BF算法中,在字符串不匹配的时候,我们通常会将模式串滑动到主串的下一个位置继续进行匹配,这种方法存在一定的缺陷,就是即使我们滑动到的位置不可能完成匹配,我们还是会一个一个去尝试进行配对,这也就是它们效率低下的原因。
就例如上图,我们可以发现a只存在于主串的第一个位置,第四个位置,第六个位置,而其他的位置下模式串是不可能匹配成功的,所以我们滑动的时候就应该直接滑动到上述的位置,如下图
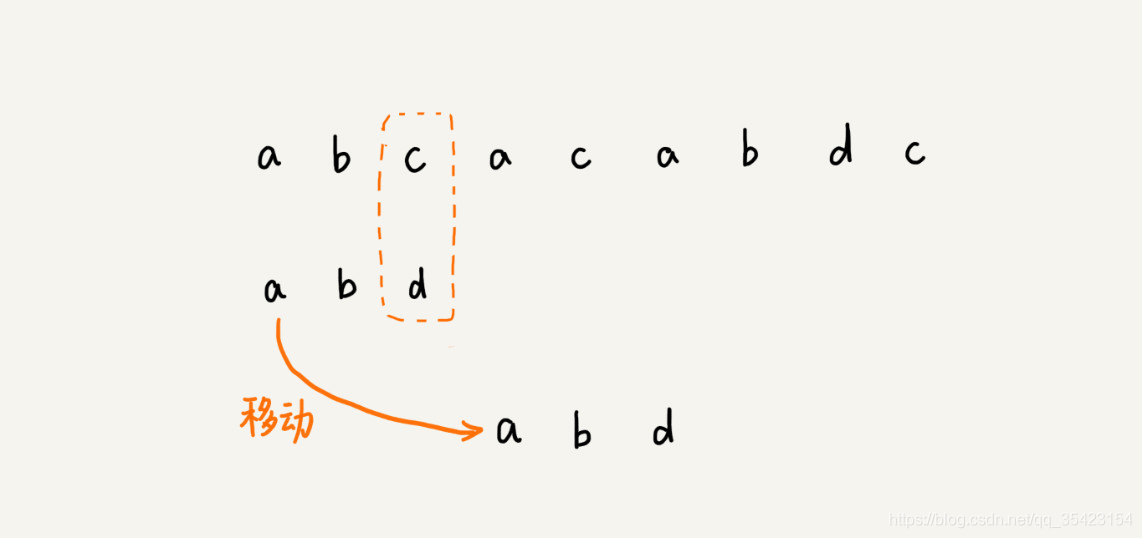
BM算法的核心就是找到这种大量滑动的规律,减少无意义的匹配。而它正是通过坏字符规则与好后缀规则来实现。
坏字符规则
因为我们的坏字符和好后缀规则都需要保证偏移量最大,所以其并非像传统的字符串比较一样从前往后,而是从后往前比较,并且我们将第一个遇见的不匹配的字符称为坏字符
当检测到坏字符后,我们就没有必要再一个一个的进行判断了,因为只有模式串与坏字符T对齐的位置也是字符T的情况下,两者才有匹配的可能。并且为了保证滑动的范围最大,我们对字符T的选择是在模式串中最后一次出现的那个
坏字符规则主要有以下三种情况,下面一一对其进行分析
- 模式串中存在与坏字符相同的字符
- 模式串中不存在与坏字符相同的字符
- 模式串中存在的其他坏字符为第一个字符
情况一:模式串中存在与坏字符相同的字符

此时的处理方法就是将坏字符与匹配字符对其,接着进行判断
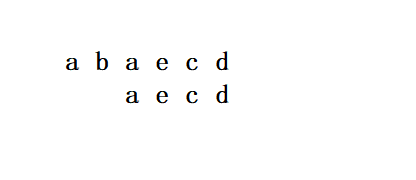
此时匹配成功
情况二:模式串中不存在与坏字符相同的字符

此时模式串中不存在可以与坏字符匹配的字符,这也就代表着在坏字符这个位置之前,不可能匹配成功,所以我们直接滑动到坏字符的下一个位置

此时,匹配成功。
情况三:倒退或者不移动
例如以下情景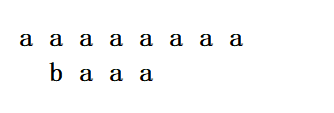
后面的全部匹配,不匹配的只有b,而坏字符又在最后面出现过,此时就会倒退。
所以我们还需要加上判断,如果滑动值小于等于0时,就直接向后滑动一步。
为了保存每个字符的最后一次出现的下标,我们使用一个数组来模拟哈希,采用ascii码来进行直接定址
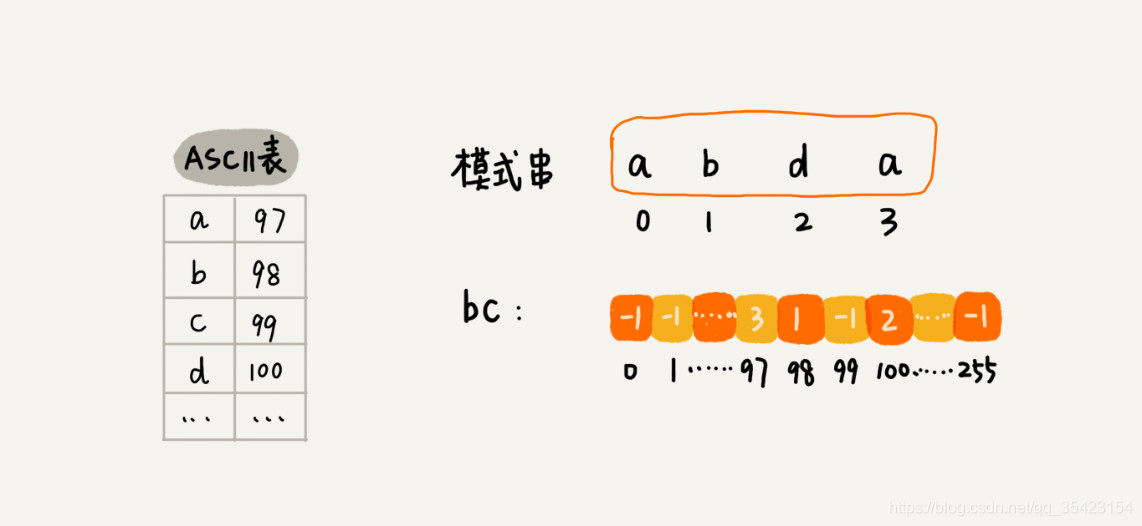
下面是基于坏字符规则实现的BM算法
//构建坏字符规则的下标数组
void generateBC(const string& pattern, int* indexArr, int len)
{
//初始化
for(int i = 0; i < len; i++)
{
indexArr[i] = -1;
}
//记录模式串中每个下标最后出现的位置
for(int i = 0; i < pattern.size(); i++)
{
indexArr[pattern[i]] = i;
}
}
int boyerMoore(const string& str, const string& pattern)
{
//不满足条件则直接返回false
if(str.empty() || pattern.empty() || str.size() < pattern.size())
{
return -1;
}
int len1 = str.size(), len2 = pattern.size();
int indexArr[128] = {
0}; //坏字符规则记录数组,记录了每一个字符最后一次出现的下标
generateBC(pattern, indexArr, 128);
int i = 0;
while(len1 - i >= len2)
{
int j;
//模式串从后往前匹配
for(j = len2 - 1; j >= 0; j--)
{
//如果当前字符不匹配,则说明该位置是坏字符
if(str[i + j] != pattern[j])
{
break;
}
}
//如果全部匹配,则返回主串起始位置
if(j < 0)
{
return i;
}
/*
如果该字符没出现过,则直接将模式串滑动到坏字符的下一个位置
如果出现过,则将模式串中对应字符滑动到坏字符处
*/
int badMove = (j - indexArr[str[i + j]]);
badMove = (badMove == 0) ? 1 : badMove; //防止倒退
i += badMove;
}
return -1;
}
从上面也可以看出,在最后一种情况下BM算法的效率就又会退化到BF算法的级别,所以为了防止这种问题,BM还有一种好前缀规则
好后缀规则
在我们进行匹配的时候,我们将第一次碰到的不匹配的字符称为坏字符,而将碰到坏字符之前所匹配到的字符串称为好后缀
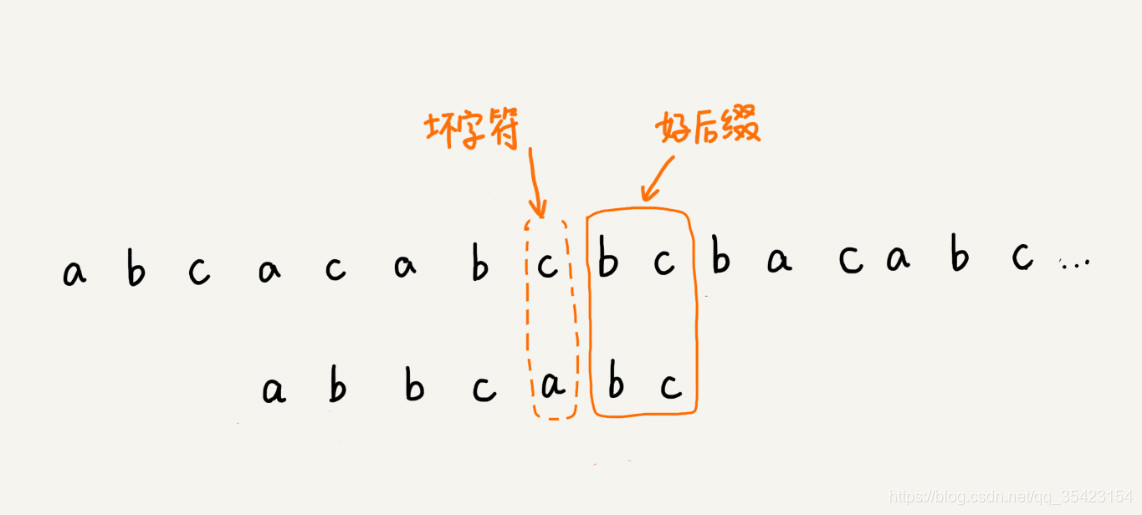
与坏字符规则一样,如果我们想要使得字符串匹配,只有模式串中存在相同子串,并与主串中好后缀对齐的情况下,两者才有匹配的可能。所以直接将对应子串滑动到好后缀的位置,如下图

如果不存在这个子串,那我们能否按照坏字符规则,则直接跳过好后缀后呢?
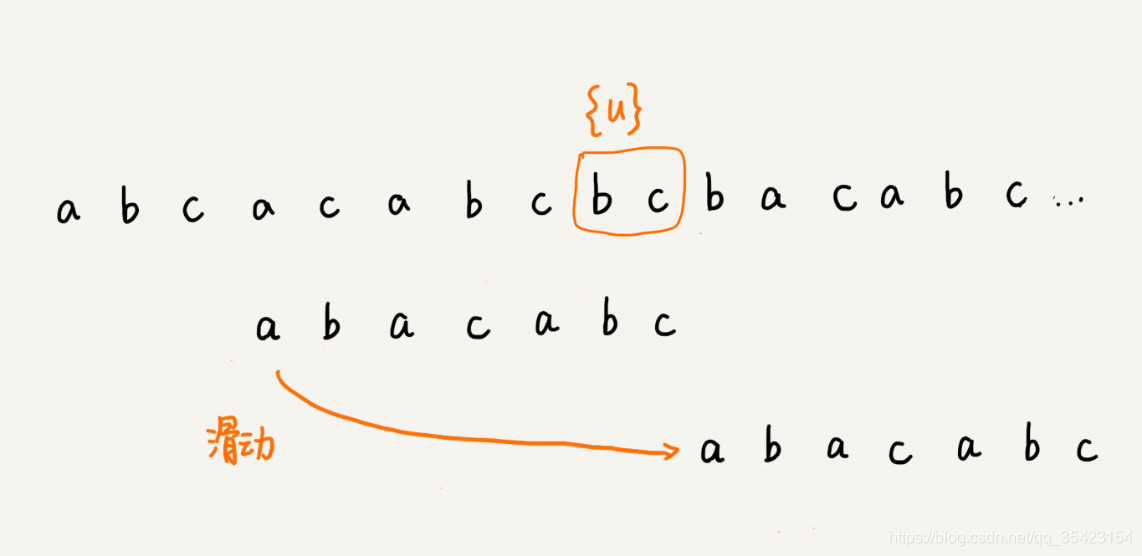
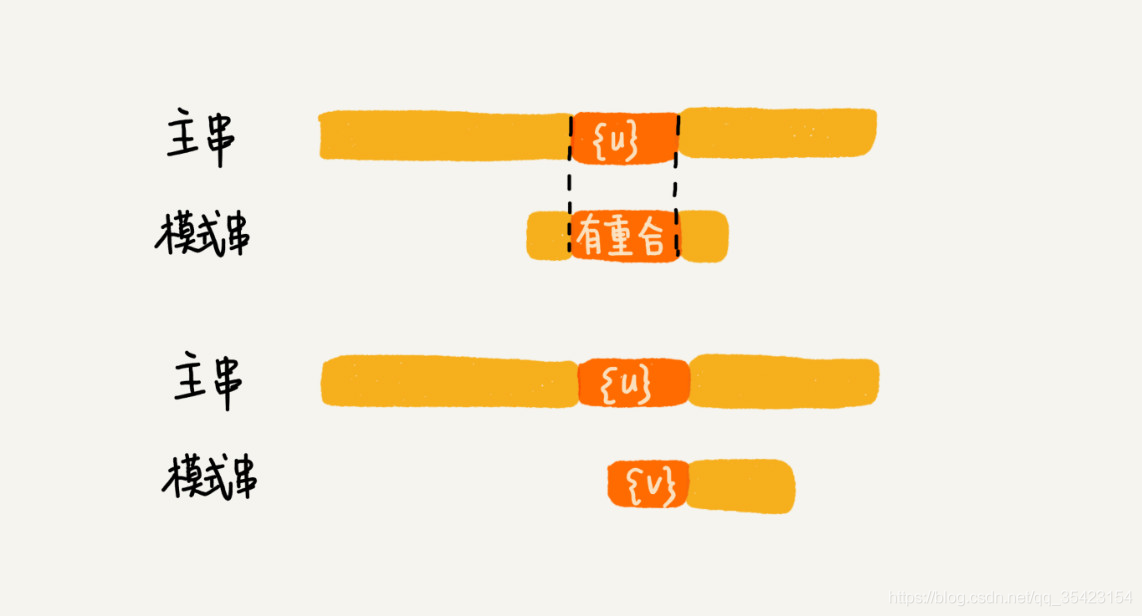
答案是否定的,如果我们因为过度滑动导致我们跳过了本身可匹配的一些字符串,如下图
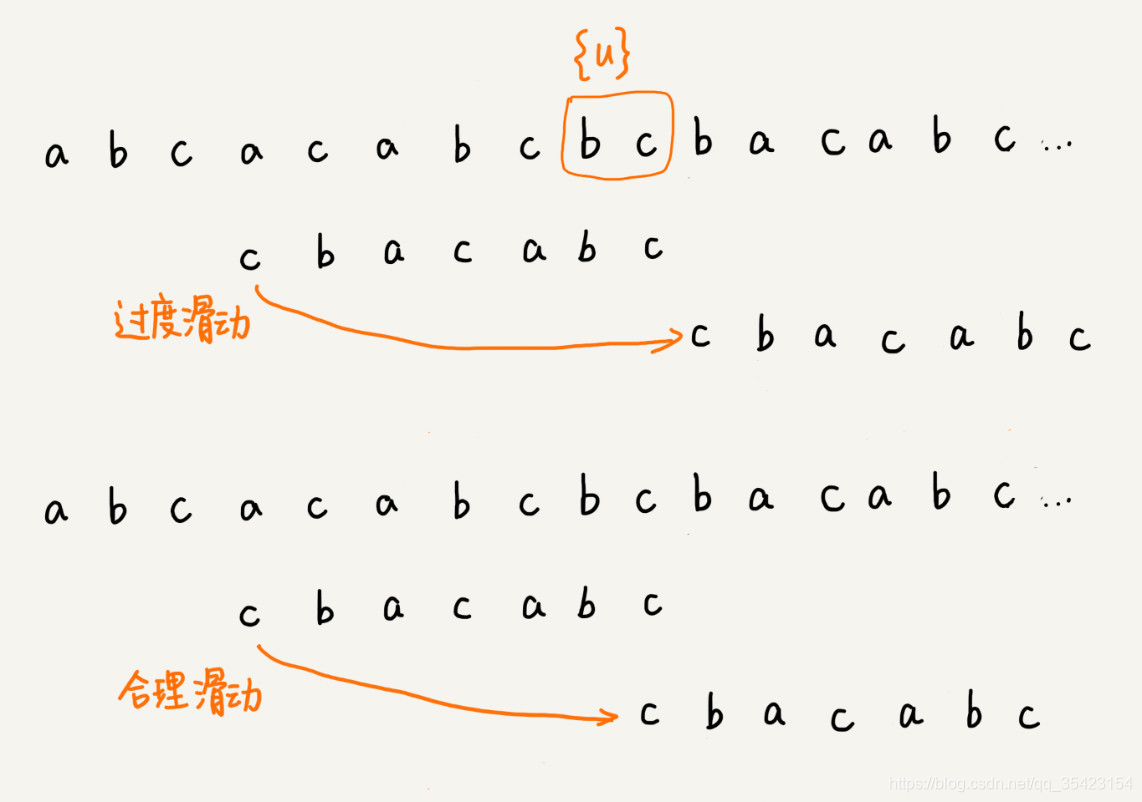
这是为什么呢?虽然我们的模式串中并不存在能够与好后缀匹配的子串,但是却存在能够与好后缀部分重合的子串,而我们的滑动就导致了跳过了这些子串
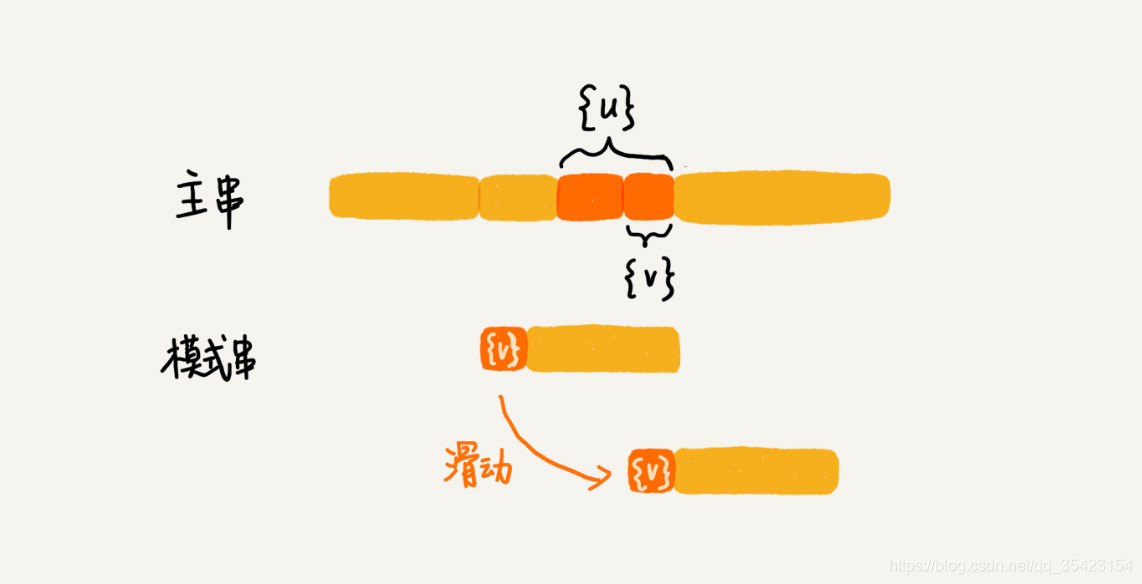
为了防止上述情况,我们此时就会寻找能够与部分好后缀子串匹配的前缀,并以它为滑动的标准,如下图
为了方便计算,我们需要保存模式串中所有前缀和后缀的匹配情况以及子串的位置,所以需要引入两个数组,一个是整型数组suffix,其用于标记能够与好后缀匹配的子串的下标。另一个是布尔数组prefix,其用于标记前缀[0, i - 1]是否能够与好后缀进行匹配。

//构建好后缀规则的前缀和后缀数组
void generateGS(const string& pattern, vector<int>& suffix, vector<bool>& prefix)
{
int len = suffix.size();
//匹配区间[0 ~ len - 1],len时即为整个模式串,不可能存在前缀
for(int i = 0; i < len - 1; i++)
{
int j = i;
int size = 0; //匹配子串的下标
while(j >= 0 && pattern[j] == pattern[len - 1 - size])
{
//继续匹配下一个位置
j--;
size++;
suffix[size] = j + 1; //记录匹配后缀的子串的位置
}
//如果子串一直匹配到开头,则说明该子串为前缀,此时前缀与后缀匹配
if(j == -1)
{
prefix[size] = true;
}
}
}
//计算出好后缀规则的偏移量
int moveByGS(int index, const vector<int>& suffix, const vector<bool>& prefix)
{
int len = suffix.size(); //模式串长度
int size = len - 1 - index; //后缀长度
//如果存在与后缀匹配的子串,则直接返回它们的偏移量
if(suffix[size] != -1)
{
return index - suffix[size] + 1;
}
//如果没有匹配的后缀,那么判断后缀中是否有部分与前缀匹配
for(int i = index + 2; i <= len - 1; i++)
{
if(prefix[len - i] == true)
{
return i;
}
}
//如果也不存在,则说明没有任何匹配,直接偏移整个模式串的长度
return len;
}
完整代码
好前缀和坏字符都实现了,因为我们希望的是尽量减少不必要的匹配,所以我们选取两者中较大的那一个作为偏移量。
将上面的好前缀规则加入前面写的坏字符规则的框架中,就是完整的BM算法,代码如下
//构建坏字符规则的下标数组
void generateBC(const string& pattern, vector<int>& indexArr)
{
//记录模式串中每个下标最后出现的位置
for(int i = 0; i < pattern.size(); i++)
{
indexArr[pattern[i]] = i;
}
}
//构建好后缀规则的前缀和后缀数组
void generateGS(const string& pattern, vector<int>& suffix, vector<bool>& prefix)
{
int len = suffix.size();
//匹配区间[0 ~ len - 1],len时即为整个模式串,不可能存在前缀
for(int i = 0; i < len - 1; i++)
{
int j = i;
int size = 0;
while(j >= 0 && pattern[j] == pattern[len - 1 - size])
{
//继续匹配下一个位置
j--;
size++;
suffix[size] = j + 1; //记录匹配后缀的子串的位置
}
//如果子串一直匹配到开头,则说明该子串为前缀,此时前缀与后缀匹配
if(j == -1)
{
prefix[size] = true;
}
}
}
int moveByGS(int index, const vector<int>& suffix, const vector<bool>& prefix)
{
int len = suffix.size(); //模式串长度
int size = len - 1 - index; //后缀长度
//如果存在与后缀匹配的子串,则直接返回它们的偏移量
if(suffix[size] != -1)
{
return index - suffix[size] + 1;
}
//如果没有匹配的后缀,那么判断后缀中是否有部分与前缀匹配
for(int i = index + 2; i <= len - 1; i++)
{
if(prefix[len - i] == true)
{
return i;
}
}
//如果也不存在,则说明没有任何匹配,直接偏移整个模式串的长度
return len;
}
int boyerMoore(const string& str, const string& pattern)
{
//不满足条件则直接返回false
if(str.empty() || pattern.empty() || str.size() < pattern.size())
{
return -1;
}
int len1 = str.size(), len2 = pattern.size();
vector<int> indexArr(128, -1); //标记匹配坏字符的字符下标
vector<int> suffix(len2, -1); //标记匹配后缀的子串下标
vector<bool> prefix(len2, false); //标记是否匹配前缀
generateBC(pattern, indexArr);
generateGS(pattern, suffix, prefix);
int i = 0;
while(len1 - i >= len2)
{
int j;
//模式串从后往前匹配
for(j = len2 - 1; j >= 0; j--)
{
//如果当前字符不匹配
if(str[i + j] != pattern[j])
{
break;
}
}
//如果全部匹配,则返回主串起始位置
if(j < 0)
{
return i;
}
int badMove = (j - indexArr[str[i + j]]); //坏字符规则偏移量
badMove = (badMove == 0) ? 1 : badMove; //防止倒退
int goodMove = 0; //好后缀规则偏移量
//如果一个都不匹配,则不存在后缀
if(j < len2 - 1)
{
goodMove = moveByGS(j, suffix, prefix); //计算出好后缀的偏移量
}
i += max(goodMove, badMove); //加上最大的那个
}
return -1;
}