字符串匹配BM算法
回顾BF和RK算法
- BF:拿模式串与主串中是所有子串匹配,看是否有能匹配的子串。时间复杂度也比较高,是 O(n*m),n、m 表示主串和模式串的长度
- RK:借助哈希算法对 BF 算法进行改造,即对每个子串分别求哈希值,然后拿子串的哈希值与模式串的哈希值比较,减少了比较的时间,时间复杂度O(n),大量散列冲突时退化为O(n*m)。
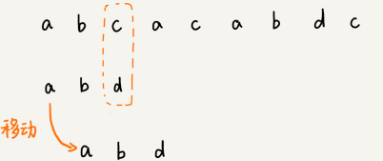
- 缺点:每次模式串往后滑动一位,然后从模式串的第一个字符开始重新匹配,效率较低。
BM的改进
- 核心思想:将模式串沿着主串大踏步的向后滑动,从而大大减少比较次数,降低时间复杂度。
- 算法的关键:如何兼顾步子迈得足够大与无遗漏,同时要尽量提高执行效率。需要模式串在向后滑动时,遵守坏字符规则与好后缀规则,同时采用一些技巧。
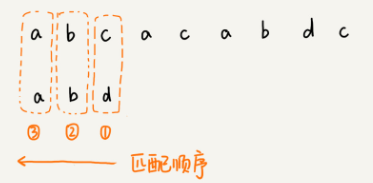
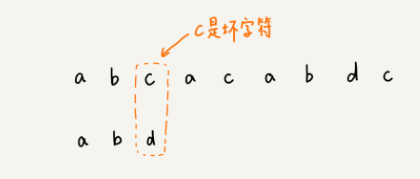
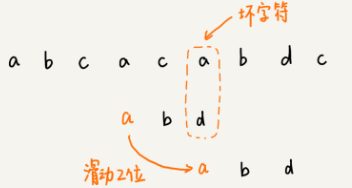
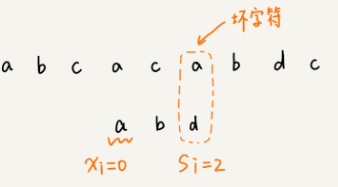
坏字符规则:
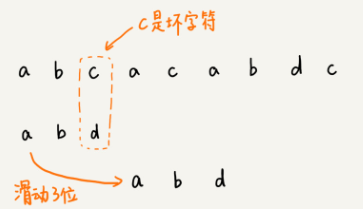
- 从后往前逐位比较模式串与主串的字符;
- 当找到不匹配的坏字符时,记录模式串的下标值si,并找到坏字符在模式串中,位于下标si前的最近位置xi(若无则记为-1),si-xi即为向后滑动距离。
- 但是坏字符规则向后滑动的步幅还不够大,还可能出现滑动为负数,也就是倒退滑动的情况,于是需要好后缀规则。
好后缀规则:
- 从后往前逐位比较模式串与主串的字符,当出现坏字符时停止。
- 若存在已匹配成功的子串{u},那么在模式串的{u}前面找到最近的{u},记作{u'}。再将模式串后移,使得模式串的{u'}与主串的{u}重叠。
- 若不存在{u'},则直接把模式串移到主串的{u}后面。
- 为了没有遗漏,需要找到最长的、能够跟模式串的前缀子串匹配的,好后缀的后缀子串(同时也是模式串的后缀子串)。
- 然后把模式串向右移到其左边界,与这个好后缀的后缀子串在主串中的左边界对齐。

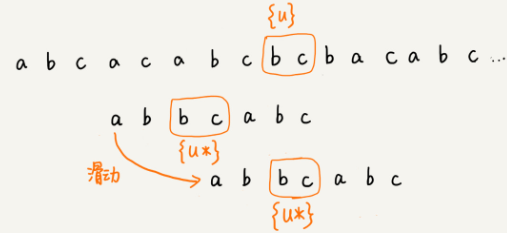
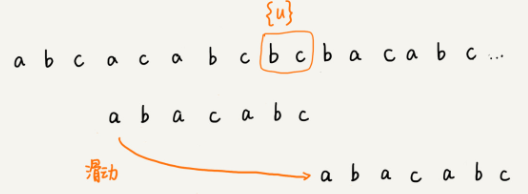
何时使用坏字符规则和好后缀规则呢?
- 首先在每次匹配过程中,一旦发现坏字符,先执行坏字符规则,
- 如果发现存在好后缀,还要执行好后缀规则,并从两者中选择后移距离最大的方案执行。
技巧:
- 通过散列表实现,坏字符在模式串中下标位置的快速查询。
- 每次执行好后缀原则时,都会计算多次能够与模式串前缀子串相匹配的好后缀的最长后缀子串。为了提高效率,可以预先计算模式串的所有后缀子串,在模式串中与之匹配的另一个子串的位置。同时预计算模式串中(同长度的)后缀子串与前缀子串是否匹配并记录。在具体操作中直接使用,大大提高效率。
- 如何快速记录模式串后缀子串匹配的另一个子串位置,以及模式串(相同长度)前缀与后缀子串石否匹配呢?
- 先用一个suffix数组,下标值k为后缀子串的长度,从模式串下标为i(0~m-2)的字符为最后一个字符,查找这个子串是否与后缀子串匹配,若匹配则将子串起始位置的下标值j赋给suffix[k]。
- 若j为0,说明这个匹配子串的起始位置为模式串的起始位置,则用一个数组prefix,将prefix[k]设为true,否则设为false。k从0到m(模式串的长度)于是就得到了模式串所有前缀与后缀子串的匹配情况。