AlexNet
(1)采用修正线性单元(ReLU)作为激活函数(替代了之前常用的Sigmoid函数),缓解了深层网络训练时的梯度消失问题。
(2)引入了局部响应归一化(Local Response Normalization,LRN)模块。
(3)应用了Dropout和数据扩充(data augmentation)技术来提升训练结果。
(4)用分组卷积来突破当时GPU的显存瓶颈。
分组卷积:其实就是将输入通道和输出通道都划分为同样的组数,然后仅让处于相同组号的输入通道和输出通道相互进行“全连接 ”。如果g为输入/输出通道所分的组数,则分组卷积能够将卷积操作的参数量和计算量都降低为普通卷积的1/g。
分组卷积有一个潜在的问题:虽然理论上它可以显著降低计算量,但对内存的访问频繁程度并未降低,且现有的GPU加速库(如cuDNN)对其优化的程度有限,因此在效率上的提升并不如理论显著。
VGGNet

(1)用多个3 X 3小卷积核代替之前的5 X 5、7 X 7等大卷积核,这样可以在更少的参数量、更小的计算量下,获得同样的感受野以及更大的网络深度。
(2)用2 x 2池化核代替之前的 3 x 3池化核。
(3)去掉了局部响应归一化模块
整个网络采用同一种卷积核尺寸(3 x 3)和池化核尺寸(2 X 2)。
GooLeNet/Inception-v1
过深或过宽的网络会导致参数量过大,会带来过拟合,梯度消失或爆炸、应用场景受限等问题。一种改进的手段是将当前网络中的全连接层和卷积层等密集结构转化为稀疏矩阵连接形式,这可以降低计算量,同时维持网络的表达能力。另外,自然界中生物的神经连接也大都是稀疏的。Inception系列网络提出了Inception模块,它将之前网络中的大通道卷积层替换成由多个小通道卷积层组成的多分支结构。其内在的数学依据是,一个大型稀疏矩阵通常可以分解为多个小的稠密矩阵。Inception模块会同时使用1 x 1、3 x 3、5 x 5的3种卷积核进行多路特征提取,这样能使网络稀疏化的同时,增强网络对多尺度特征的适应性。
(1)提出了瓶颈( bottleneck)结构,即在计算比较大的卷积层之前,先使用1x1卷积对其通道进行压缩以减少计算量(在较大卷积层完成计算之后,根据需要有时候会再次使用1x1卷积将其通道数复原)

(2)从网络中间层拉出多条支线,连接辅助分类器,用于计算损失并进行误差反向传播,以缓解梯度消失问题。
(3)修改了之前VGGNet等网络在网络末端加入多个全连接层进行分类的做法,转而将第一个全连接层换成全局平均池化层(Global Average Pooling)。
Inception-v2和Inception-v3




(1)避免表达瓶颈(representational bottleneck),尤其是在网络的前几层。具体来说,将整个网络看作由输入到输出的信息流,需要尽量让网络从前到后各个层的信息特征表达能力逐渐降低,而不能突然剧烈下降或者是在中间某些结点出现瓶颈。
(2)特征图通道越多,能表达的解耦信息就越多,从而更容易进行局部处理,最终加速网络的训练过程。
(3)如果要在特征图上做空间域的聚合操作(如3x3卷积),可以在此之前先对特征图的通道进行压缩,这通常不会导致表达能力的损失。
(4)在限定总计算量的情况下,网络结构在深度和宽度上需要平衡。
ResNet
随着网络层数的加深,网络的训练误差和测试误差都会上升。这种现象称为网格的退化(degeneration),它与过拟合显然是不同的,因为过拟合的标志之一是训练误差降低而测试误差升高。为解决这种现象,ResNet采用了跳层连接(shortcut connection),即在网络中构筑多条“近道”。
(1)能缩短误差反向传播到各个层的路径,有效抑制梯度消失的现象,从而使网络在不断加深时性能不会下降。
(2)由于有“近道”的存在,若网络在层数加深时性能退化,则它可通过控制网络中“近道”和“非近道”的组合比例来退回到之前浅层时的状态,即“近道”具备自我关闭能力。
Inception-v4
网络结构

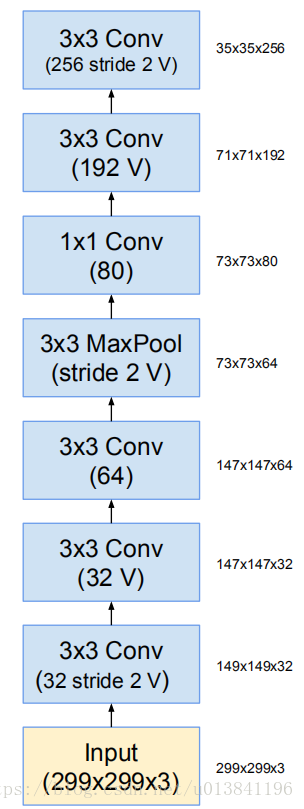
Stem
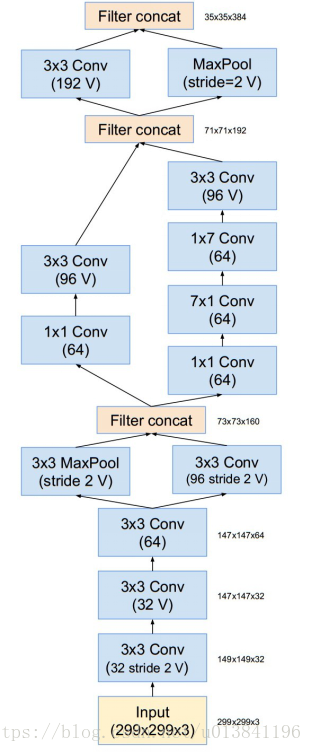





Inception-ResNet
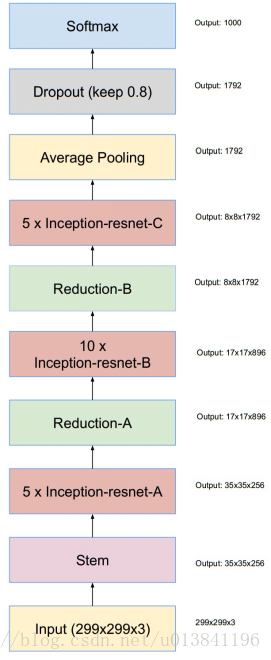








参考:
https://blog.csdn.net/u013841196/article/details/80673688
《百面深度学习》