采用python进行简易的时间序列预测流程
这篇文章主要作为自己的学习笔记,温习一下采用Python进行时间序列预测的一般步骤。
时间序列可视化——>序列平稳——>acf,pacf寻找最优参——>建立模型——>模型检验——>模型预测
涉及到的工具包如下:
代码块语法遵循标准markdown代码,例如:
# -*- coding:utf-8 -*-
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from random import randrange
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from statsmodels.tsa.arima_model import ARIMA
from statsmodels.api import tsa原始数据
时间序列是与时间相关的一组数据,这里的数据主要是生成的模拟数据,仅是为了练习一下处理【时间序列】的流程。
def generate_data(start_date, end_date):
df = pd.DataFrame([300 + i * 30 + randrange(50) for i in range(31)], columns=['income'],
index=pd.date_range(start_date, end_date, freq='D'))
return df
data = generate_data('20170601', '20170701')
# 这里要将数据类型转换为‘float64’
data['income'] = data['income'].astype('float64')数据可视化
这里主要是观察数据是否是平稳序列,如果不是则要进行处理转换为平稳序列
# 绘制时序图
data.plot()
plt.show()
# 绘制自相关图
plot_acf(data).show()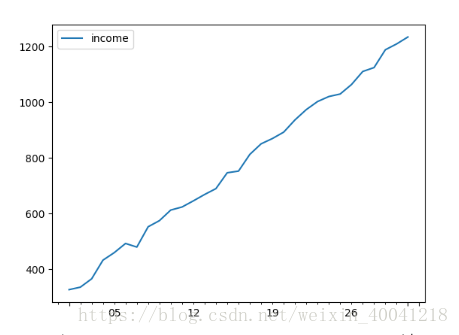
从时序图中可以看出这组序列存在明显的增长趋势。不是平稳序列
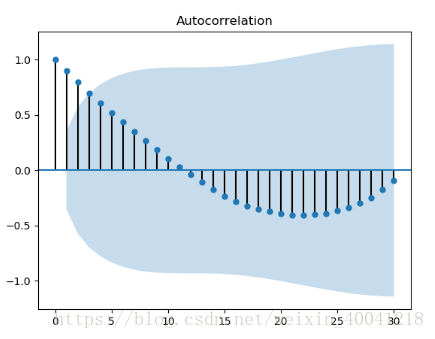
acf图呈现出三角对称趋势,进一步说明这组时间序列是一组单调趋势的非平稳序列。
差分–转换为平稳序列
# 差分运算
# 默认1阶差分
data_diff = data.diff()
# 差分后需要排空,
data_diff = data_diff.dropna()
data_diff.plot()
plt.show()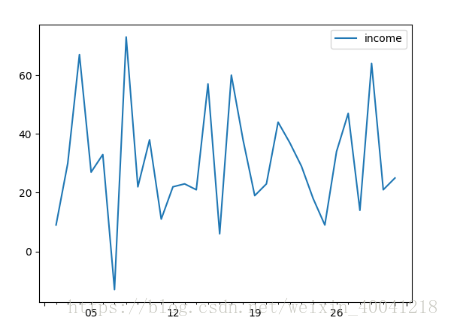
可以看到在1阶差分后序列已经转换为平稳序列。
由acf,pacf判断模型参数
plot_acf(data_diff).show()
plot_pacf(data_diff).show()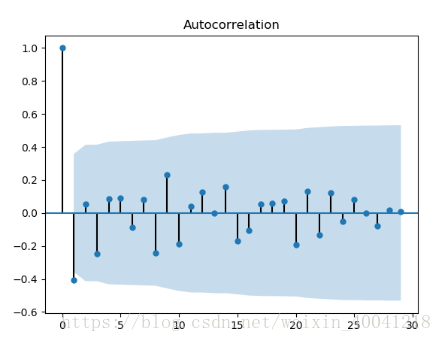
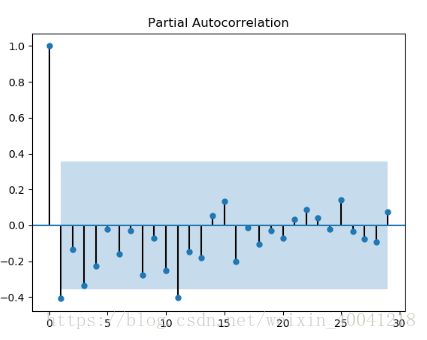
这里选用ARIMA模型,参数为(1, 1, 1)
模型训练
arima = ARIMA(data, order=(1, 1, 1))
result = arima.fit(disp=False)
print(result.aic, result.bic, result.hqic)
plt.plot(data_diff)
plt.plot(result.fittedvalues, color='red')
plt.title('ARIMA RSS: %.4f' % sum(result.fittedvalues - data_diff['income']) ** 2)
plt.show()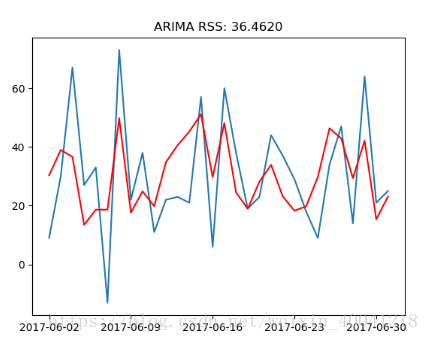
模型检验
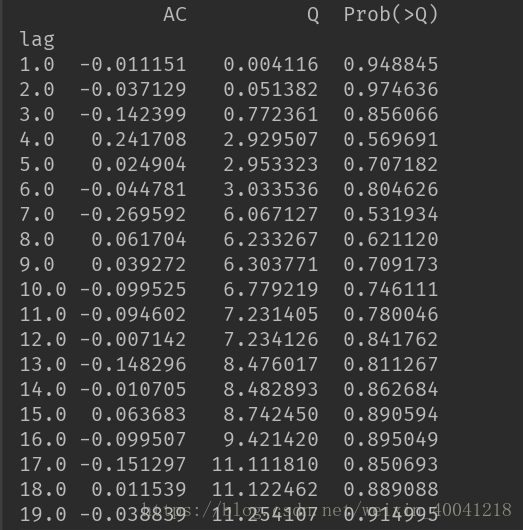
这里选择了 ‘Ljung-Box检验’,
# ARIMA Ljung-Box检验 -----模型显著性检验,Prod> 0.05,说明该模型适合样本
resid = result.resid
r, q, p = tsa.acf(resid.values.squeeze(), qstat=True)
print(len(r), len(q), len(p))
test_data = np.c_[range(1, 30), r[1:], q, p]
table = pd.DataFrame(test_data, columns=['lag', 'AC', 'Q', 'Prob(>Q)'])
print(table.set_index('lag'))检验的结果就是看最后一列前十二行的检验概率(一般观察滞后1~12阶),如果检验概率小于给定的显著性水平,比如0.05、0.10等就拒绝原假设,其原假设是相关系数为零。就结果来看,如果取显著性水平为0.05,那么相关系数与零没有显著差异,即为白噪声序列。
模型预测
# 模型预测
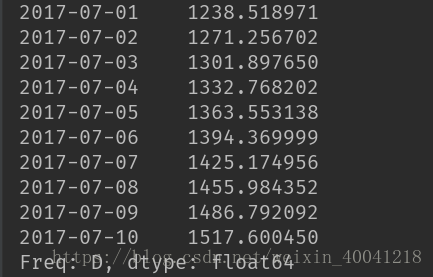
pred = result.predict('20170701', '20170710', typ='levels')
print(pred)
x = pd.date_range('20170601', '20170705')
plt.plot(x[:31], data['income'])
# lenth = len()
plt.plot(pred)
plt.show()
print('end')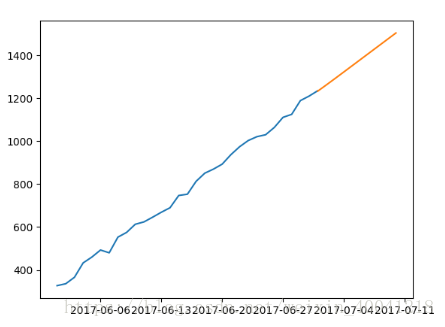
Ending
因为刚接触这快,所以还不是很完善,肯定也存在不对的地方。
练习的过程中主要借鉴了一下几篇博客,感谢博主的分享:
https://blog.csdn.net/pipisorry/article/details/62053938
https://blog.csdn.net/u010414589/article/details/49622625
https://blog.csdn.net/oh5W6HinUg43JvRhhB/article/details/78360686
完整代码:
https://github.com/rowlingz/python_learning/blob/73a61974e38a089b879b22d5c7914d81f605f5d7/DataAnalysis/Time_series_data_LSTM/ARMA_model_training.py