概念
索引是帮助MySQL高效获取数据的数据结构。
实现
在MySQL 中使用最频繁的就是 B+ 树索引,所以我们必须要知道 B+ 树的结构。而 B+ 树是借鉴了二分查找法、二叉查找树、平衡二叉树、B 树,所以我们在了解B+树前先了解这些基本概念
二分查找法
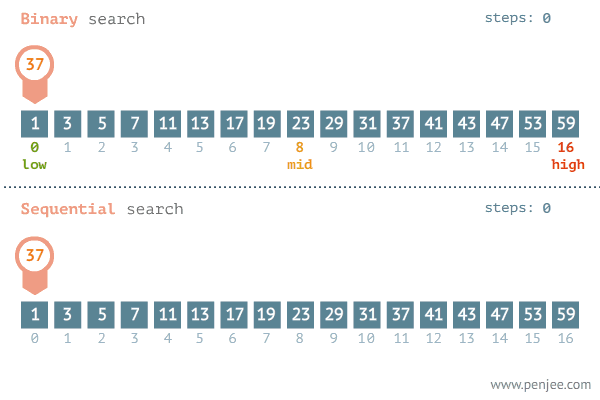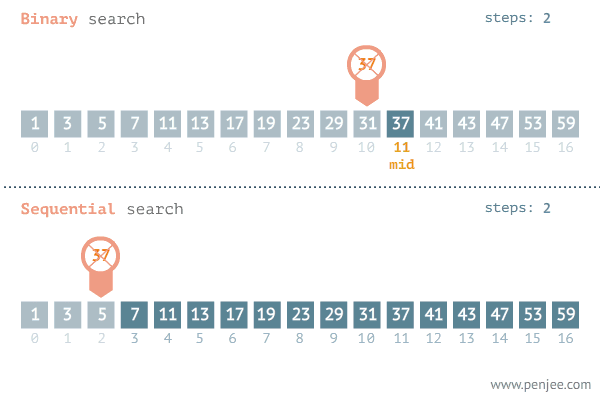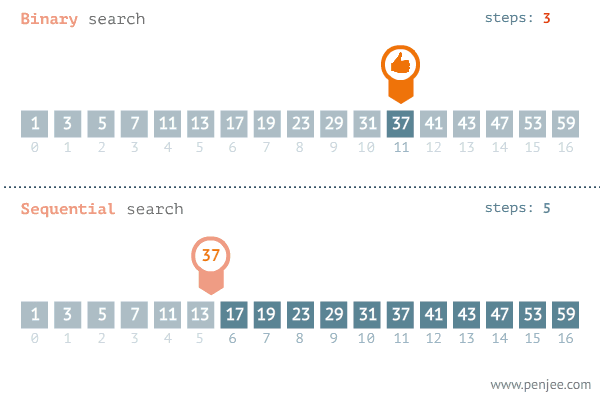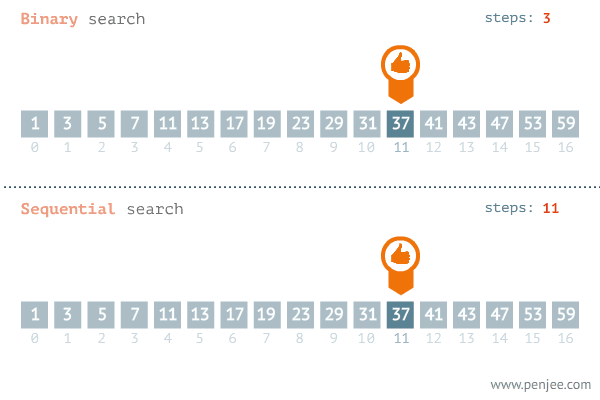
二分查找法的查找过程是:将记录按顺序排列,查找时先以有序列的中点位置为比较对象,如果要找的元素值小于该中点元素,则将查询范围缩小为左半部分;如果要找的元素值大于该中点元素,则将查询范围缩小为右半部分。以此类推,直到查到需要的值。
如下图所示我们查找37:
二叉查找树
定义:
二叉搜索树是一种节点值之间具有一定数量级次序的二叉树,对于树中每个节点:
- 若其左子树存在,则其左子树中每个节点的值都不大于该节点值;
- 若其右子树存在,则其右子树中每个节点的值都不小于该节点值。
存在问题: 可能一边会过长会导致查询效率慢,或者退化成链表
平衡二叉树
定义:
平衡二叉树也叫自平衡二叉搜索树(Self-Balancing Binary Search Tree),所以其本质也是一颗二叉搜索树,不过为了限制左右子树的高度差,避免出现倾斜树等偏向于线性结构演化的情况,所以对二叉搜索树中每个节点的左右子树作了限制,左右子树的高度差称之为平衡因子,树中每个节点的平衡因子绝对值不大于1 ,此时二叉搜索树称之为平衡二叉树。
自平衡是指,在对平衡二叉树执行插入或删除节点操作后,可能会导致树中某个节点的平衡因子绝对值超过 1,即平衡二叉树变得“不平衡”,为了恢复该节点左右子树的平衡,此时需要对节点执行旋转操作。
缺点:
每个节点最多只有两个分支,如果数据量比较大,要经历多层节点才能查询在叶子节点的数据。
B树
定义:
B树和平衡二叉树稍有不同的是B树属于多叉树又名平衡多路查找树(查找路径不只两个),数据库索引技术里大量使用者B树和B+树的数据结构
缺点:
B 树也是有缺点的,因为每个节点都包含 key 值和 data 值,因此如果 data 比较大时,每一页存储的 key 会比较少;当数据比较多时,同样会有:“要经历多层节点才能查询在叶子节点的数据” 的问题。这时,B+ 树站了出来。(这里涉及到读写缓存页,有兴趣自己去查查)

B+树
B+ 树是 B 树的变体,定义基本与 B 树一致,与 B 树的不同点:
- 所有叶子节点中包含了全部关键字的信息
- 各叶子节点用指针进行连接
- 非叶子节点上只存储 key 的信息,这样相对 B 树,可以增加每一页中存储 key 的数量。
- B 树是纵向扩展,最终变成一个 “瘦高个”,而 B+ 树是横向扩展的,最终会变成一个 “矮胖子”
两者最大的区别: 它的键一定会出现在叶子节点上,同时也有可能在非叶子节点中重复出现。而 B 树中同一键值不会出现多次。

默认大家都是知道这些数据结构,所以就简单说下,有问题可以看下面的参考链接
为什么添加索引能提高查询速度?
B+ 树的高度一般都在 2 ~ 4 层,所以查找某一行数据最多只需要 2 到 4 次 IO。而没索引的情况,需要逐行扫描,明显效率低很多
注意:B+树1层可放468行数据,2层 56.3万,3层 6.77 亿,4 层8140亿
聚集索引/非聚集索引
聚集索引
定义:索引中索引的逻辑顺序与磁盘上行的物理存储顺序相同,一个表中只能拥有一个聚集索引。
InnoDB 的主键一定是聚集索引。如果没有定义主键,聚集索引可能是第一个不允许为 null 的唯一索引,也有可能是 row id。
由于实际的数据页只能按照一颗 B+ 树进行排序,因此每张表只能有一个聚集索引(TokuDB 引擎除外)。查询优化器倾向于采用聚集索引,因为聚集索引能够在 B+ 树索引的叶子节点上直接找到数据。
聚集索引对于主键的排序查找和范围查找速度非常快。
非聚集索引
定义:索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同,一个表中能拥有多个聚集索引。
其实按照定义,除了聚集索引以外的索引都是非聚集索引,只是人们想细分一下非聚集索引,分成普通索引,唯一索引,全文索引。
参考链接
数据结构(二):二叉搜索树(Binary Search Tree)
古之立大事者,不唯有超世之才,亦必有坚韧不拔之志。----苏轼