MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。提取句子主干,就可以得到索引的本质:索引是数据结构。我们都知道数据库查询是数据库的重要功能之一,当我们查找数据的时候会用到各种查找算法,而如何选择查找算法主要依赖于存储数据的数据结构。因此数据库索引就是一种可以优化数据库查询速度的一种数据结构。那么:
1.索引在数据库是如何产生的?
2.采用索引后对数据库有哪些影响?
3.数据库索引实现的原理是什么?
4.什么是聚集索引和非聚集索引?
5.聚集索引和非聚集索引有什么区别?
索引在数据库是如何产生的
索引就像书的目录, 通过书的目录就准确的定位到了书籍具体的内容。我们平时在数据库建表时会有两种选择,添加主键和不添加主键;不填加主键时,这个表上的数据会无序的存储在磁盘存储器上,一行一列的很整齐,符合我们对“表”的认知。当添加主键后,该表在磁盘存储器上的结构就会变成一种树状结构,即平衡树,换句话说,当一个表添加主键后,该表就成了一个索引。
采用索引后对数据库有哪些影响
假如一张表有一亿条数据 ,需要查找其中某一条数据,按照常规逻辑, 一条一条的去匹配的话, 最坏的情况下需要匹配一亿次才能得到结果,用大O标记法就是O(n)最坏时间复杂度,这是无法接受的,而且这一亿条数据显然不能一次性读入内存供程序使用, 因此, 这一亿次匹配在不经缓存优化的情况下就是一亿次IO开销,以现在磁盘的IO能力和CPU的运算能力, 有可能需要几个月才能得出结果 。如果把这张表转换成平衡树结构(一棵非常茂盛和节点非常多的树),假设这棵树有10层,那么只需要10次IO开销就能查找到所需要的数据, 速度以指数级别提升,用大O标记法就是O(log n),n是记录总树,底数是树的分叉数,结果就是树的层次数。换言之,查找次数是以树的分叉数为底,记录总数的对数,用公式来表示就是

用程序来表示就是Math.Log(100000000,10),100000000是记录数,10是树的分叉数(真实环境下分叉数远不止10), 结果就是查找次数,这里的结果从亿降到了个位数。因此,利用索引会使数据库查询有惊人的性能提升。然而, 事物都是有两面的, 索引能让数据库查询数据的速度上升, 而使写入数据的速度下降,原因很简单的, 因为平衡树这个结构必须一直维持在一个正确的状态, 增删改数据都会改变平衡树各节点中的索引数据内容,破坏树结构, 因此,在每次数据改变时, DBMS必须去重新梳理树(索引)的结构以确保它的正确,这会带来不小的性能开销,也就是为什么索引会给查询以外的操作带来副作用的原因。
数据库索引实现的原理是什么
想要理解索引原理必须清楚一种数据结构「平衡树」(非二叉),也就是b tree或者 b+ tree,重要的事情说三遍:“平衡树,平衡树,平衡树”。当然, 有的数据库也使用哈希表作为索引的数据结构 , 然而, 主流的RDBMS都是把平衡树当做数据表默认的索引数据结构的。本文小编暂时不对b tree和b+ tree做出详解后续博客会对此做出更新。
聚集索引
当一个表添加了主键后,该表就变成了一个聚集索引,因为一个表只能有一个主键,所以一个表只能有一个聚集索引;主键的作用就是把这个表的数据按照索引二叉树的格式放置。
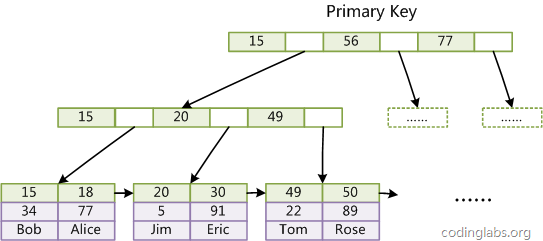
在聚集索引的存储结构中,树的非叶子节点中存储的是主键字段中的数据和指向子节点的指针,叶子节点中存储得是实际的数据。例如我们执行一条sql语句:select * from table where id =15
它的实际执行过程为:首先根据索引定位到叶子节点为15的叶子节点,然后由该叶子节点获得id等于15 的数据行,由图可知树一共有三层,从根节点到叶子节点需要找三次。
非聚集索引
非聚集索引就是在聚集索引的基础上,给给表的其他字段添加索引,此时会产生新的索引新索引的非叶子节点由别添加索引的字段里面的值组成,叶子节点则存储了该字段中值对应的主键值。整个运行过程为通过非聚集索引可以查到记录对应的主键值 , 再使用主键的值通过聚集索引查找到需要的数据。
聚集索引和非聚集索引的区别
非聚集索引和聚集索引的区别在于, 通过聚集索引可以查到需要查找的数据, 而通过非聚集索引可以查到记录对应的主键值 , 再使用主键的值通过聚集索引查找到需要的数据,不管以任何方式查询表, 最终都会利用主键通过聚集索引来定位到数据, 聚集索引(主键)是通往真实数据所在的唯一路径。