全文索引指的是:”将存储在数据库里面的整本书或者整篇文章里面的任意内容查找出来的技术“。
1、MySQL 5.6 以前的版本,只有 MyISAM 存储引擎支持全文索引;
2、MySQL 5.6 及以后的版本,MyISAM 和 InnoDB 存储引擎均支持全文索引;
3、只有字段的数据类型为 char、varchar、text 及其系列才可以建全文索引。
为什么使用全文索引?
首先对于使用字段前缀进行查找,B+树索引是支持的。比如:
SELECT * FROM table_name where content like ‘nihao%’;但是实际上大多数情况下用户使用的是下面的的查找:
SELECT * FROM table_name where content like ‘%nihao%;
也就是用户查找的不是以某个字符串开头的,而是包含某个字符串的数据,上述SQL语句,即便给content添加了B+树索引,也需要对索引进行一个一个扫描才能得到结果,这种情况下并不适合使用B+树索引。实际的使用场景包括搜索引擎查找用户输入的关键字,或者电子商务网站根据用户的查询条件来进行查询。
因此,这种情况下,全文索引就出场了!
全文索引的实现
底层的数据结构:全文索引底层使用倒排索引来实现,倒排索引和B+树索引一样,都是一种索引结构。这种索引结构会创建一个辅助表,这个“辅助表”里面存储单词和单词所在的一个或者多个文档之间的映射。这个辅助表通常使用关联数组来实现。辅助表通常有以下两种结构:
1、inverted file index关联数组
里面存储的映射关系是 :key为一个单词 ,value为这个单词出现的所有文档的id。
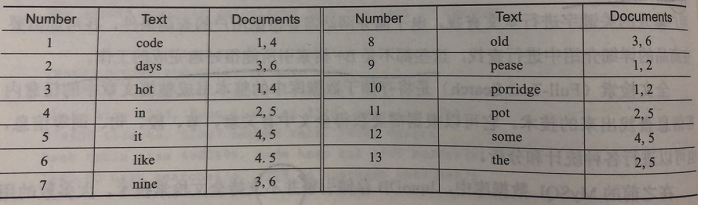
2、full inverted index关联数组
里面存储的映射关系是:key为一个单词,value为这个单词出现的文档id以及他在文档中的位置(第几个单词)。而在innoDB存储引擎里面,采用的就是这种方式。实际存储的时候,在辅助表里面,单词是对应word字段,而文档id对应DOC_ID字段,位置对应POSITION字段。并且在word字段上设置了索引。

辅助索引缓存
但是实际使用的时候,这个辅助表是存放在磁盘上的,因此innoDB存储引擎不可能每次查询都到磁盘里面查询,因此还有一个全文索引缓存(FTS index cache),用来提高全文索引的性能,这个全文索引缓存的底层是红黑树结构。
我们实际进行分词操作和更新是在“全文索引缓存”里面,innoDB会批量的把缓存里面的内容更新到辅助表里面。因此如果数据库发生宕机,缓存里面的数据可能还没有被同步到辅助表,那么下次当用户对表进行全文索引时(查询或者插入),就会自动读取未完成的文档,然后进行再次进行分词操作,把结果放入全文索引缓存。但是对于删除操作,不会删除磁盘上的内容,见下:
在innoDB里面,为了支持全文索引,需要有一个列和word进行映射,存储引擎会自动创建一个FTS Docunments ID列,这个列的类型为BIGINT UNSIGNED NOT NULL,并且会自动为他创建唯一索引(目的就是每个word都有一个唯一标识)。执行删除操作时,不会删除辅助表里面内容,而是只删除全文索引缓存里面的内容。然后会记录下这个word对应的FTS Docunments ID,然后把它保存到”删除辅助表“里面。
因此,文档的删除操作不仅不会删除索引里面的数据,还会在对应的delete辅助表里面添加数据。为了解决最后索引越来越大的问题,提供了:OPTIMIZE TABLE命令,来手工的删除索引里面的记录。
STOPWORD表
最后,全文索引里面还有一个stopword表,这个表里面的所有单词都不会对他进行分词操作,比如the这个单词,由于他不具有具体的涵义,因此将它视为stopword,innoDB里面有一个默认的stopword表,里面存储了36个单词,用户可以自行添加。
使用
给某一列增加全文索引:
alter table 表名 add fulltext index 索引名('列名');或者:
CREATE FULLTEXT INDEX 索引名 ON '表名'('列名')使用全文索引查询:
SELECT * FROM `表名` WHERE MATCH(`列名`) AGAINST('查询的单词')删除全文索引:
alter table 表名 drop index 全文索引名;2种模式
全文检索有2种模式:natural language mode + boolean mode。
natural language mode下面还有一个扩展查询:with query expension,就不细说了。
【1】natural language mode:是默认的模式,就是查询带有指定word的文档。
比如:
SELECT * FROM table WHERE MATCH(body) AGAINST (‘cong’ IN NATURAL LANGUAGE MODE);也可以省略后面的模式:
SELECT * FROM table WHERE MATCH(body) AGAINST (‘cong’);如果有多个查询结果的话,会根据相关性进行降序排序,计算相关性的依据是:
word是否在文档中出现;在文档中出现的次数;word在索引列里面的数量;多少个文档包含这个word。
此外,查询的结果还需要经过两层过滤:1、这个word是否在stopword表里面;2、查询的word的字符长度是否在某个区间内。这个区间的两端由2个参数设置,默认长度为[3,84],也就是最小字符长度为3,最大字符长度84。
【2】boolean mode:这个模式可以使用一些修饰符来修饰查询的字符串,不同的修饰符有特殊的含义:
+:表示必须存在这个单词
-:表示必须没有这个单词
没有修饰符:表示这个单词可以存在,也可以不存在,但是存在的话会增加相关性
*:表示包含以这个单词开头的单词,比如lik*,可以是like,lik,likes
@distance:表示查询的多个单词之间的距离,是否在distance个字节之内。
>:出现该单词时相关性增加
<:出现该单词是相关性减小
举一些例子:
SELECT * FROM table WHERE MATCH(body) AGAINST (‘+cong -min IN BOOLEAN MODE);表示返回有cong没有min的文档。
SELECT * FROM table WHERE MATCH(body) AGAINST (' "cong min "@30 'IN BOOLEAN MODE);表示字符串cong和min之间的距离需要在30字节以内。返回符合条件的文档。