经典英文论文笔记————深度学习(Deep Forest)周志华

摘要

个人译文:
目前的深度学习模型大多数基于神经网络,例如:可以用反向传播算法来训练的参数化的可微分的多层非线性模型。在这篇文章中,我们探索了基于决策树这种不可微分的模型构建深度模型的方案。本文讨论了深度神经网络背后的秘密,尤其是将深度神经网络与基层神经网络和决策树和提升算法等传统机器学习技术对比之后,我们推测深度神经网络的成功归功于三个方面:第一、层对层的处理过程;第二、模型内部的特征转移;第三、充足的模型复杂度。一方面,我们的推测或许会对深度学习领域的理解提供帮助;另一方面,为了印证我们的推测,我们提出了一个包含以上三大特征的深度森林算法。经过实验证明,这种算法的性能表现对于超参数的设置更具有鲁棒性。在很多不同领域和数据集的案例中,我们发现这种算法使用默认的参数就能实现良好的性能。这个研究打开了不需要梯度计算就可以建立深度学习模型领域的大门,而且展示了不需要反向传播算法就能构建深度学习模型的可能性。
引言

引言第一段介绍了DNN(深度神经网络)的概述。
转折————但是DNN有很多缺点————-开始罗列缺点:



个人总结——DNN的缺点:
- 超参数过多、训练设计很有技巧性、模型内部有太多的影响因素分析起来困难。
- 需要大量的带有标签的训练数据集(成本过高)
- 训练开始之前就已经固定好了模型,这倒是有的问题不需要如此复杂的模型,浪费了计算力。
- 神经网络是一个黑盒,我们目前无法知道为什么在一些问题上,神经网络的训练结果不如随机森林算法和XGboost。

引出矛盾点——————我们为了提高精确率,一定要把模型设计的更加深入,但是目前的算法都是基于梯度的算法。

提出了三个问题:
1.探索更加深入的模型一定要用微分的方法吗?
2.不用反向传播算法可不可行?
3.在一些XBboost和RF算法表现更优异的问题上,我们如何应用深度学习算法取胜?

解释2017年那片文章的成果与这篇文章的关联性。

简明介绍了文章各个部分在做什么?
一、集成学习
第一段概述了弱分类器与强分类器的集成关系
第二段写出了数学表达,多样性如何描述
第三段写了实际应用中的四种解决方法
- bagging的策略(采样)
- 划分特征子空间
- 设计不同的初始化学习参数
- 对于不同分类器使用不同的输出表达方式如ECOC
二、深度学习的关键
论证了为什么层对层的处理是深度学习的关键,这一发现个给GCforest提供了思路。
同时对比发现,模型的复杂度也很重要。
三、gcForest算法
1.级联结构


翻译图片描述:
级联森林的结构示意。假设每一层级联包括两个完全随机森林和两个不完全随机森林,假设有三个类别可以分类;因此每个森林将会输出3维度的向量。然后这些向量与输入的特征向量级联起来。
解释完全随机森林与不完全随机森林:

在每个节点随机分配特征,然后不断生长直到叶子节点,这种树称为完全随机树。
n个完全随机树组成了完全随机森林。
输入了d个特征,随机挑选出根号d个特征作为候选特征,然后利用基于Gini系数的分裂算法生成了不完全随机树。n个不完全随机树组成了不完全随机森林。
其中n是Gcforest算法的一个超参数。
举个例子:

不同叶子节点的形状(三角形、圆形、正方形)表示不同的类别。红色的线表示路径。

每棵树统计一下叶子节点中三种类别所占据的百分比,汇总到森林里面,这样每个森林就可以给出一个这样的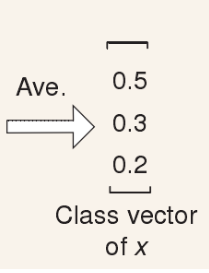 评估结果。
评估结果。
这个三维的评估结果与其他的森林评估结果级联起来作为增强后的特征向量,再送入到下一层网络。
通过k折交叉验证来确定级联的层数。这一点比DNN更好。
多粒度扫描

受CNN和RNN的启发,用相同的提取特征手段。
超参数(与CNN对比):