1.SVM支持向量机的设计出发点

又要借用一下周教授华人区《机器学习》的配图,SVM的设计初衷是,在类与类之间找到一个超平面,这个超平面根据关键的支持向量来获得最好的类间距离,以使分类器的泛化性能达到最好,相比于神经网络,SVM设计有着严谨的数学推导支撑和较好的泛化性能,这是它令许多理论派着迷的地方。
2.SVM的相关公式摘录与理解
超平面公式
该公式代表教科书在引用一个线性超平面做分类器教学,法向量为w,偏移为b,然后希望通过该平面分隔两类数据后,特征间隔达到最大,泛化性能达到最佳。支持向量机本质上是一个分类器功能,但是因为其博大精深就像一个系统一样,所以称为Machine。
任意点到超平面距离公式
参考这位仁兄的推导过程:https://blog.csdn.net/yutao03081/article/details/76652943
设数据点为在超平面上的投影点为
,所以有
由于向量与法向量w平行,所以有
Part I.
上式中,w与向量作点乘,cos 0°=1,所以直接等于拆分相乘,w的长度就是w的二范数
Part II.
另一个等式(在超平面上,所以等于-b):
联立上面两式就有
约束公式
上式是整个支持向量机的约束型,意思是对于任意样本点,最大化支持向量间隔r = 2/||w||,即最小化w式,二范数要开根不太舒服,所以再加一次平方计算,特别地,当不等式等号成立时,该点为支持向量(当为支持向量点时有,所以两边支持向量的距离为r = 2/||w||,这是一种化简计算的假设 )。
拉格朗日乘子法及函数(原创)
在数学界,要解上面的在约束条件下的最优化值,一般采用拉格朗日乘子法,如果对数学没有探究精神的可以忽略这一段,但我是带着问题想去理解拉格朗日乘子法的。问题就是,1-为什么乘子法要把约束式加起来,2-拉格朗日乘子的物理意义是什么呢?
问题1的定性回答:把约束式加到目标优化项,能够化规划问题为凸函数的极值点求解问题,在三维下还能看图看出最优点位置,但是在高维约束下,譬如i = 1,2,...,100,肉眼无法再理解如何寻求极值点,所以需要纯粹的公式计算偏导数等于零来求解,就像现在只需要你求解类似公式的某个极值点一样,不等式s.t.消除了。
问题2:把约束式乘上了系数,那究竟代表了什么意义?这里我思考到凌晨三点举了一个实例做研究。
现在需要求解
的最小值,约束条件是
,这个问题可以用拉格朗日乘子法求解,
在(x,y) = (0,0)时,输出为0,首先我们应该注意到当变量有2个时,整个空间可以看做三维的,
。现在我们构造拉格朗日函数:
注意到约束式x+y-3在(x,y)坐标系中是一条直线,所以优化问题可以表述为,在x+y-3这条分割线的一侧的所有数值里面,找出使得
的时候,就很容易理解了等于z = kx的形式,所以
其实就是平面x+y-3的斜率。
下面计算偏微分方程等于零的方程组解:
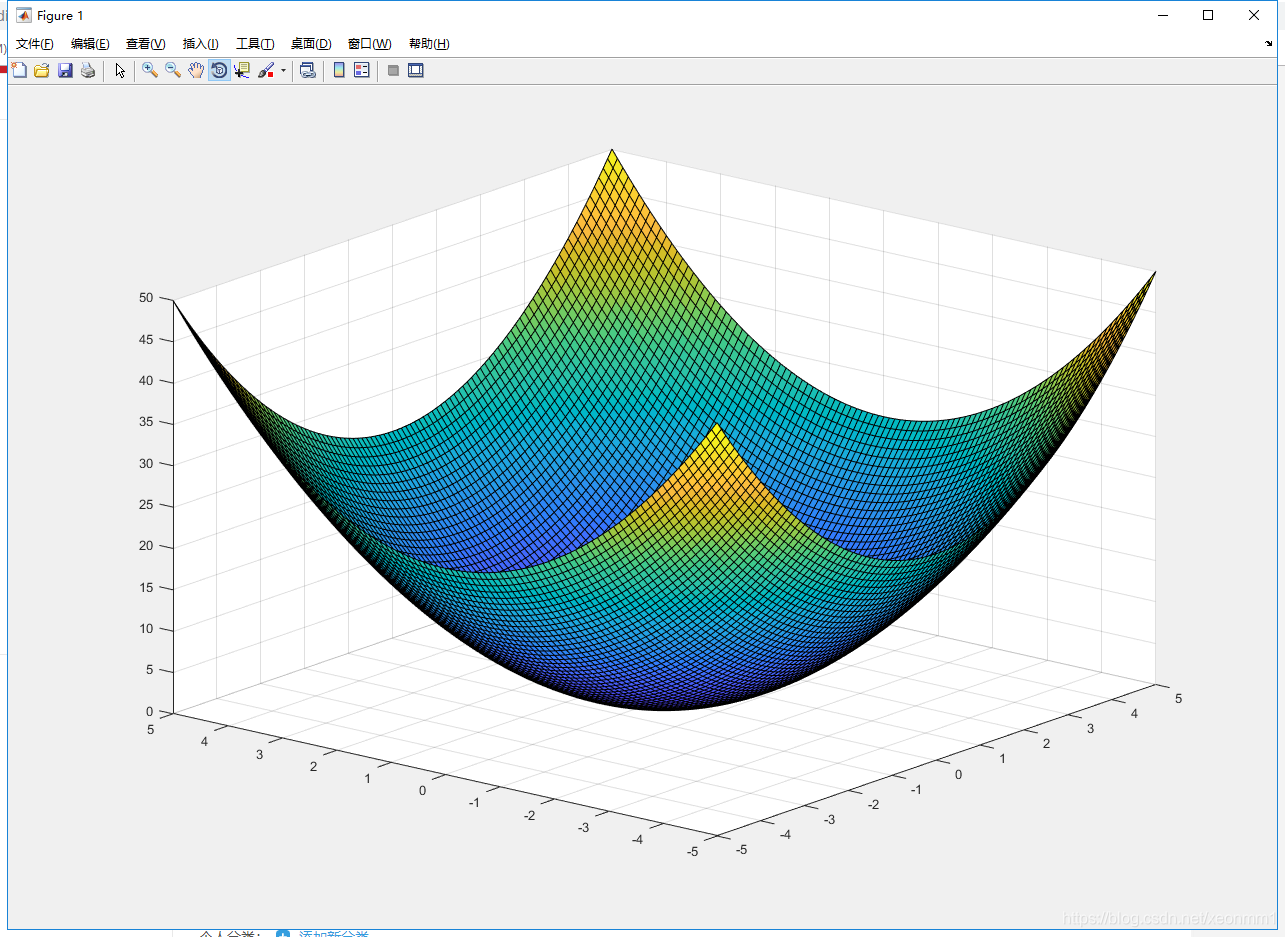
三条方程联合解出,
画出
的三维图:
可以观察到,整个拉格朗日乘子法就是为了求出约束项与目标优化公式的相切超平面,相切点就是符合约束项下的极值,所以实质上整条公式的物理意义就是升维求解,添加多余系数进行偏微分求极值。

对偶问题
理解完了拉格朗日乘子法后,接下来就是求解SVM基本型的对偶问题,问题的拉格朗日函数可写为:
周志华教授可能对对偶问题已经很熟悉,《机器学习》书中的推导实在跳得太快让我看得一头雾水,所以借助一下大神SVM三层境界的理解:https://blog.csdn.net/v_july_v/article/details/7624837
首先,对于原函数,我们希望基于拉格朗日乘子来看,是需要最大化函数值的,因为如果约束式不成立,
这一部分就会无穷大,这是在优化中不希望看到的,如果约束式成立,那么我们就会希望这个函数足够大,证明约束项的值足够“紧致”,因为项是减出来小于0的,如果整个和式越接近0,代表约束效果靠近最优,所以对偶问题的一边是
在a条件下约束最大值后,回到原来的问题就是在w,b条件下使得w项最小,所以又有
将求最大最小的过程互换一下,就是传说中的对偶操作,上式可以等效为
KKT条件
参照这位仁兄的文章理解:https://blog.csdn.net/u014675538/article/details/77509342
优化问题分为三种:
1.纯粹的目标项寻找极值点,min or max f(x)
2.(1)+ 附加等式约束,h(x) = 0
3.(1)+ 附加等式或不等式约束,g(x) ≥ 0
SVM问题属于第三种问题,如果要时对偶条件的等号成立,即d* = p*,其必须要满足KKT条件:
对于L函数,KKT条件为:
1.
2.
3.
所以从KKT条件就不难理解《机器学习》公式组(6.13):
,拉格朗日乘子条件
,原约束式条件
,KKT条件
所以必有 或
也就是说如果数据点不是支持向量,则必有,若是则满足KKT条件,所以支持向量机的模型训练完成后仅仅与支持向量有关。
对拉格朗日函数进行求偏导获得模型
(不再详细展开,若要深入探讨,则看三层境界大神的推导,这里copy《机器学习》)
令 对w和b求偏导为0可得
代回函数式消去w和b,有:
最后可以解得模型式