文章目录
All-to-All广播和归约
- All-to-All广播 : 所有进程同时发起一个广播, 每个进程向所有其它进程发送m个字
- All-to-All归约 : 广播的逆操作

- All-to-All 广播, 每个节点既发送也接收
- int MPI_Allgather (void* sendbuf, int sendcount, MPI_Datatype sendtype, void* recvbuf, int recvcount, MPI_Datatype recvtype, MPI_Comm comm)
- 归约并散发
- int MPI_Reduce_scatter(void* sendbuf, void* recvbuf, int* recvcounts, MPI_Datatype datatype, MPI_Op op, MPI_Comm comm)
- 归约后在执行一次散发操作
- 快速算法 : 利用all-to-all广播方法 , 每个步骤不是将消息组合, 而是进行运算.
算法思想
- 简单方法 : p个节点各执行一个one-to-all广播
- 性能差, 可能时间是一个one-to-all广播的p倍
- 更有效地利用链路 : p个all-to-all广播同时进行, 一个链路上同时传输的消息合并为最大消息
- 线性阵列和环
- 保证每个节点总有数据传输给邻居 – 链路总保持忙
- 第一步 : 每个进程 -> 某个邻居进程
- 第二步 : 每个进程将刚收到的数据转发到下一个进程
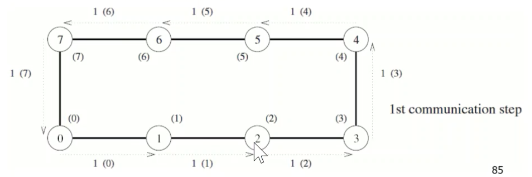
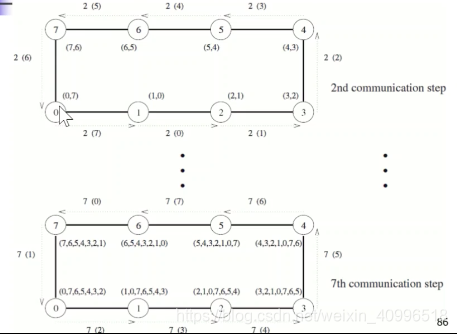
- 环all-to-all归约
- 初始, 每个进程都有p个消息
- 每个消息会与其它p-1个进程的各一个消息进行计算, 最终保存在某个进程
All归约 和 前缀和
All归约
- all-to-one归约 + one-to-all广播, 完成后, 每个进程都有相同的归约结果
- 与all-to-all归约不同 – p个all-to-all归约, 每个进程得到不同归约的结果
- 应用 : 同步操作实现
前缀和
-
操作之前, 进程pk保存数nk, 完成后前缀和操作后, 保存求和(i=0,k)ni
-
前缀积也类似, 实际上就是一个归约操作, 只是归约的数有一定范围, 只归约pk进程之前的数
-
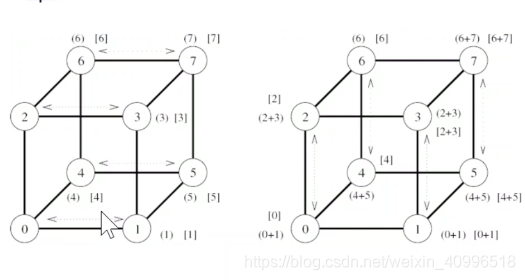
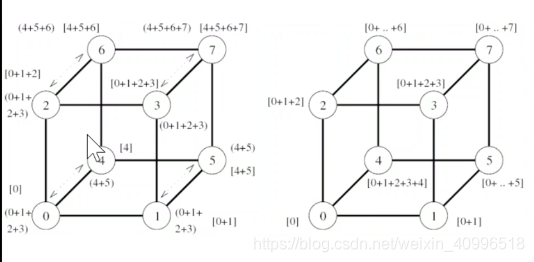
利用all-to-all广播实现前缀和
- 每个步骤进行加法, 而不是组合消息
- 两个缓冲
- result – 本节点最终结果, 只累加编号小于自己的节点发送来的数据
- 传输缓冲, 累加所有收到的数据
-
int MPI_Allreduce(…) All归约
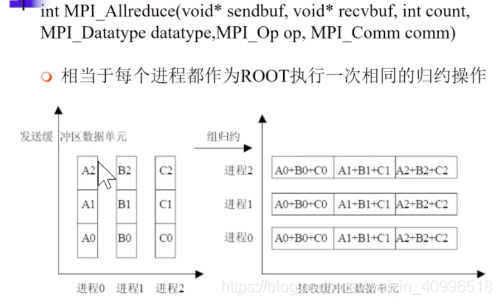
-
int MPI_Scan(…) 前缀和 (一种特殊的归约)
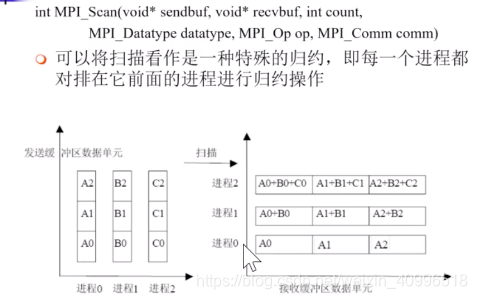
前缀和算法图示
用户自定义归约操作



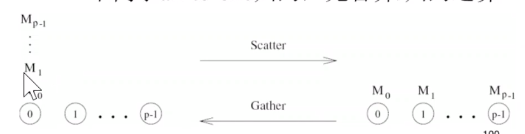
Scatter 和 Gather
- scatter : 源节点向其它每个节点发送不同数据, one-to-all个体化通信. 与one-to-all广播(发送相同数据)不同
- 对应操作 : gather, concatenation, 目的节点从其它每个节点接收不同数据, 不同于all-to-one归约, 无合并/归约运算

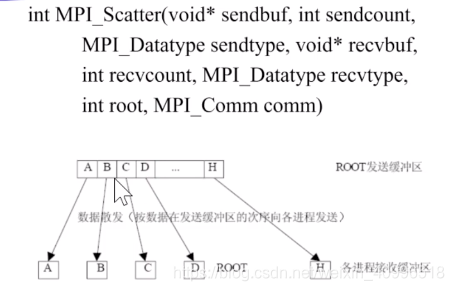

scatter实现算法
- one-to-all广播相同模式, 但消息大小不同 – 折半法
- 第一步 : 源节点将p个消息的一般 -> 邻居
- 第二步 : 两个节点将各自消息的一般 -> 邻居
- 消息用目的节点编号加以标记
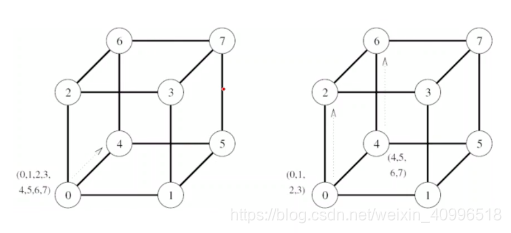
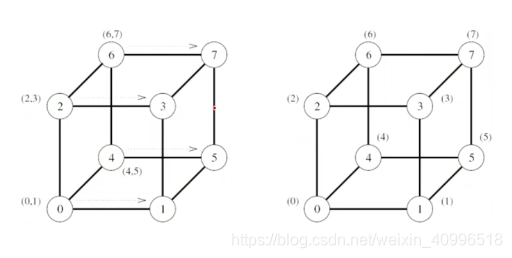
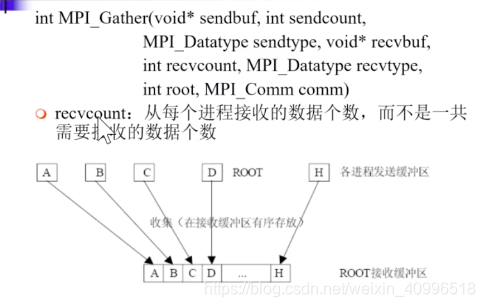
gather实现算法

扫描二维码关注公众号,回复:
11373332 查看本文章

all-to-all个体化通信


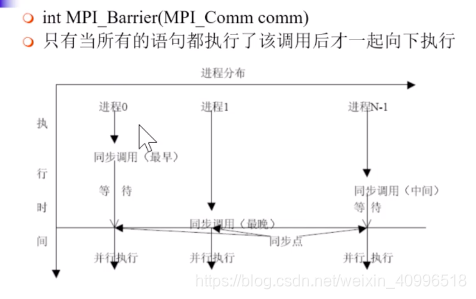
Barrier
非阻塞通信
-
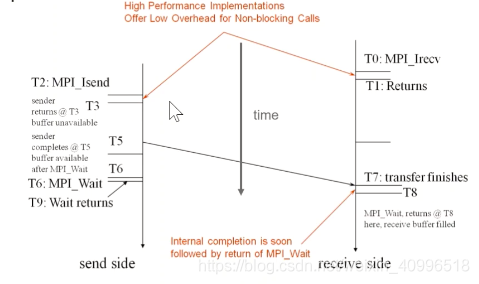
基本含义 : 调用返回 ≠ 通信完成 (异步)
-
作用 : 计算和通信的重叠
-
形式 : 非阻塞发送 和 非阻塞接收
-
MPI_Wait : 如果执行完毕, 则返回结果. 如果没有, 则继续阻塞
-
非阻塞通信会造成一些错误

-
实现非阻塞通信的难点
- 系统层面
- 硬件支持通信在后台完成, 不需要CPU参与
- 有相应的编程接口
- 算法层面
- 要保证与通信重叠的计算无依赖关系
- 很多时候要重构算法
- 系统层面
发送, 接收, 查询的接口调用
- 标准发送
- int MPI_Isend(void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request* request)
- request : 非阻塞通信对象, 用于查询
- 接收
- int MPI_Irecv(void* buf, int count ,MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Request* request)
- 查询
- int MPI_Wait(MPI_Request* request, MPI_Status* status)
- 等待完成并释放该对象, 返回信息在status中
- 若为发送擦欧哦, 则发送完成后, 发送缓冲区可以重用
- 若为接收操作, 则数据已经接收到, 放在接收缓冲区中
- 查询多个1
- int MPI_Waitany(int count, MPI_Request* array_of_requests, int* index,MPI_Status* status)
- count : 非阻塞通信对象的个数
- array_of_requests : 非阻塞通信完成对象数组
- index : 完成对象对应的句柄索引, 任何一个对象完成了, 就会把句柄索引存入其中.
- status : 返回状态
- 任何一个对象完成就返回
- int MPI_Waitany(int count, MPI_Request* array_of_requests, int* index,MPI_Status* status)
- 查询多个2
- int MPI_Waitall(int count, MPI_Request* array_of_requests, MPI_Status* array_of_statuses)
- count : 非阻塞通信对象的个数
- array_of_requests : 非阻塞通信完成对象数组
- array_of_statuses : 状态数组
- 所有对象均完成才返回
- int MPI_Waitall(int count, MPI_Request* array_of_requests, MPI_Status* array_of_statuses)
- 查询多个3
- int MPI_Waitsome(int incount, MPI_Request* array_of_request, int* outcount, int* array_of_indices, MPI_Status* array_of_statuses)
- incount : 非阻塞通信对象的个数
- array_of_request : 非阻塞通信对象数组
- outcount : 已完成对象的数目
- array_of_indices : 已完成对象的下标数组
- array_of_statuses : 已完成对象的状态数组
- 只要有不为0的对象完成就返回
- int MPI_Waitsome(int incount, MPI_Request* array_of_request, int* outcount, int* array_of_indices, MPI_Status* array_of_statuses)
- 检测
- 单个
- int MPI_Test(MPI_Request* request, int* flag, MPI_Status* status)
- flag == true : 表示指定通信操作已完成
- flag == false : 表示指定通信操作未完成
- 多个
- 与wait相对应, 只是增加了flag属性
- MPI_Testsome 没有flag参数, 因为有outcount 输出完成的个数, 如果为0, 说明没有完成, 大于0说明有完成的.
- 单个
- int MPI_Wait(MPI_Request* request, MPI_Status* status)
非阻塞通信对象
- 识别各种通信操作, 判断相应的非阻塞操作是否完成
- 释放
- 确认一个非阻塞通信操作完成时, 可直接对该对象所占用的资源, 而不是通过调用非阻塞通信完成操作来间接的释放
- int MPI_Request_free(MPI_Request* request)
- 如果与该非阻塞通信对象相联系的通信还没有完成, 则该对象的资源不会立即释放
非阻塞通信的取消
- int MPI_Cancel(MPI_Request* request)
- 若取消操作调用时相应的非阻塞通信已经开始则它会正常完成
- 也必须调用非阻塞通信的完成操作或查询对象的释放操作来释放查询对象
- int MPI_Test_cancelled(MPI_Status statu, int* flag)
- 如果 flag = true 则表明该通信已经被成功取消
重复非阻塞通信
- 对于会被重复执行的通信操作, MPI对其进行优化以降低不必要的通信开销
- 通信初始化 : MPI_SEND_INIT
- 启动通信 : MPI_START
- 激活通信对象
- 完成通信 : MPI_WAIT
- 这一步只是将通信状态置为不活跃
- 释放查询对象 : MPI_REQUEST_RFREE
- 必须显示地调用释放
- MPI_SEND_INIT, MPI_RECV_INIT与非阻塞发送接收接口形式类似, 只是不真正启动消息通信
- int MPI_Start(MPI_Request* request)
- int MPI_Startall(int count, MPI_Request* array_of_requests)
非阻塞通信解决Jacobi迭代

利用重复模式解决Jacobi迭代
