文章目录
1. 机器学习策略
如何改善模型的性能
- 收集更多数据
- 训练集多样性(如,识别猫,收集各种姿势的猫,以及反例)
- 训练的时间更长一些
- 尝试不同的优化算法(如 Adam优化)
- 规模 更大 / 更小 的神经网络
- 尝试 DropOut 正则化
- 尝试添加 L2 正则化
- 新的网络结构(修改激活函数,隐藏单元数目)
你可以去尝试,但是万一花了半年时间,最后发现是错误的?那就哭吧!
需要判断哪些是有效的,哪些是可以放心舍弃的。
2. 正交化 Orthogonalization
各个调整的变量之间最好没有耦合关系

定位出模型的性能瓶颈在哪个环节,利用对应的方法去改善
early stopping,就是一个不那么正交化的方法
过早停止,影响训练集准确率,同时它又可以改善在开发集的准确率
它同时影响两件事情,尽量用其他的正交化控制方法
3. 单一数字评估指标
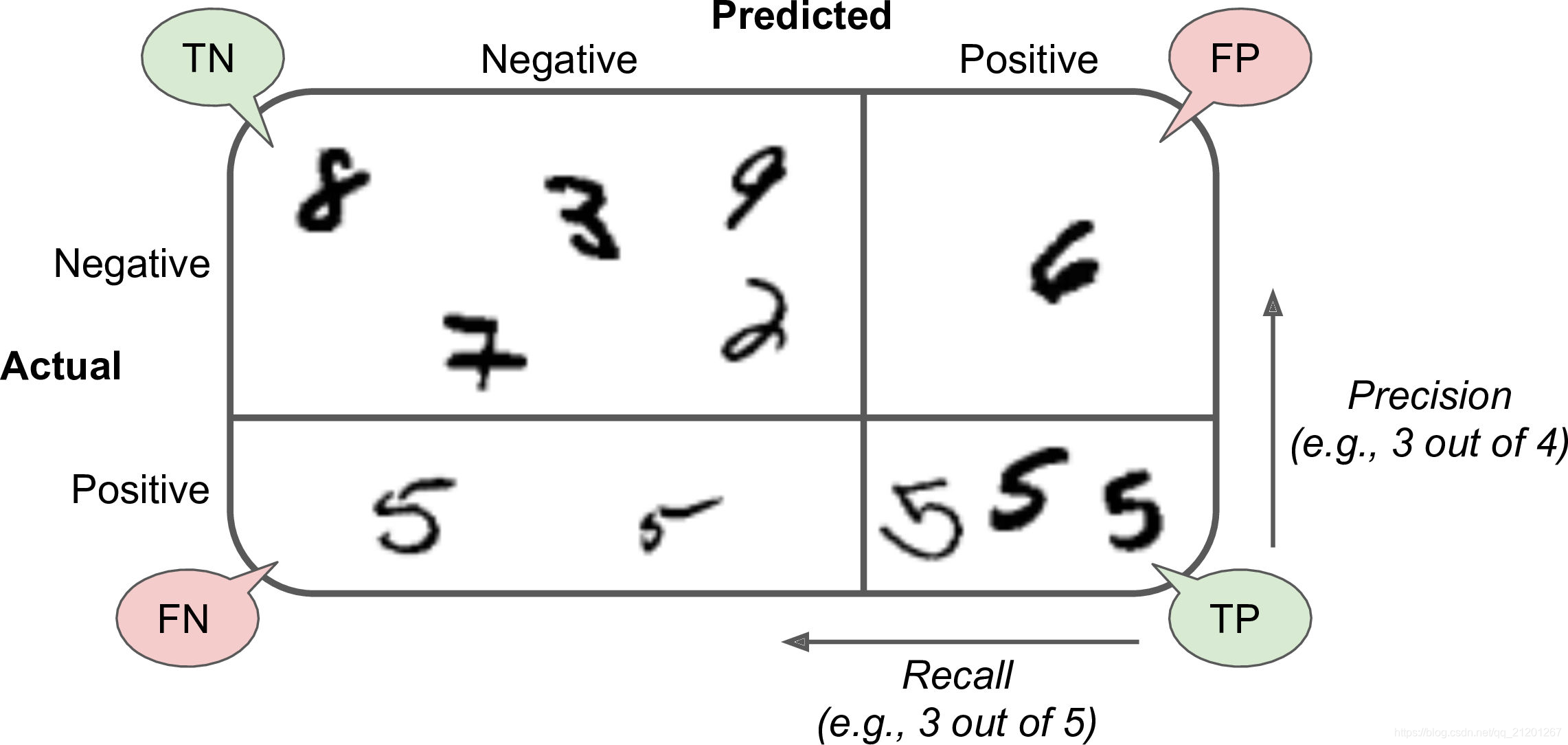

- 准确率、召回率、F1值(前两者的平均)
F 1 = 2 1 precision + 1 recall = 2 ∗ precison ∗ recall precison + recall = T P T P + F N + F P 2 F 1=\frac{2}{\frac{1}{\text {precision}}+\frac{1}{\text {recall}}}=2 * \frac{\text {precison } * \text {recall}}{\text {precison }+\text {recall}}=\frac{T P}{T P+\frac{F N+F P}{2}} F1=precision1+recall12=2∗precison +recallprecison ∗recall=TP+2FN+FPTP

有一个单实数评估指标可以提高你的效率 或 做出决策的效率
4. 满足和优化指标

考虑 N 个指标,有时候选择其中一个做为优化指标是合理的。
尽量优化那个指标,然后剩下 N-1 个指标都是满足指标,意味着只要它们达到一定阈值,你不再关心指标在阈值内的大小
5. 训练/开发/测试集划分

举例:前4个区域的数据作为开发集,后4个作为测试集
- 非常不好,他们很可能来自不同的分布
- 应该随机打乱所有的数据,重新划分
6. 开发集和测试集的大小


7. 什么时候该改变开发/测试集和指标

更改测试指标:
误 差 : 1 ∑ w ( i ) ∑ i = 1 m d e v w ( i ) L { ( y ^ ( i ) ≠ y ( i ) ) } 误差: \frac{1}{\sum w^{(i)}} \sum_{i=1}^{m_{d e v}} w^{(i)} \mathcal{L}\left\{\left(\hat{y}^{(i)} \neq y^{(i)}\right) \bigg\}\right. 误差:∑w(i)1i=1∑mdevw(i)L{
(y^(i)=y(i))}
w ( i ) = { 1 if x ( i ) 是非色情图片 10 if x ( i ) 是色情图片 w^{(i)}=\left\{\begin{array}{cl}1 & \text { if } x^{(i)} \text { 是非色情图片 } \\ 10 & \text { if } x^{(i)} \text { 是色情图片}\end{array}\right. w(i)={ 110 if x(i) 是非色情图片 if x(i) 是色情图片
以上方法,你必须自己过一遍数据,把色情图片标记出来
在比如:你的开发/测试集都是很清晰的专业图片,而应用最终上线是针对不专业的图片(模糊,角度不好等)
那么就要更改开发/测试集,加入不专业图片作为训练数据
8. 人类的表现水准
把机器学习的水平和人类的水平相比较是很自然的。我们希望机器比人做的更好

对于人类擅长的任务,只要机器学习算法比人类差,就可以让人帮你标记数据,就有更多的数据可以喂给学习算法,改进算法
9. 可避免偏差

10. 理解人的表现


11. 超过人的表现

情况B:超过 0.5% 的门槛(比最好的医生的误差还低),要进一步优化你的机器学习问题就没有明确的选项和前进的方向了
12. 改善你的模型的表现
总结:
以上的方法就是一种正交化的改进思路。

- 训练集误差 与 贝叶斯估计误差 之间的差距:可避免偏差
- 训练集误差 与 开发集误差 之间的差距:方差
改进偏差:
- 更大规模的模型
- 训练更久、迭代次数更多
- 更好的优化算法(Momentum、RMSprop、Adam)
- 更好的新的神经网络结构
- 更好的超参数
- 改变激活函数、网络层数、隐藏单元数
- 其他模型(循环NN,卷积NN)
改进方差:
- 收集更多的数据去训练
- 正则化(L2正则、dropout正则、数据增强)
- 更好的新的神经网络结构
- 更好的超参数
测试题作业
参考博文链接
我的CSDN博客地址 https://michael.blog.csdn.net/
长按或扫码关注我的公众号(Michael阿明),一起加油、一起学习进步!
