误差分析
在训练过程中,如何进行误差分析以提高准确度呢?
仍旧以猫图片的检测为例,选择被错误分类为猫的图片进行分析。通过制作一张表格,将分类错误的图片进行归类,我们找出各种原因使得分类错误的概率,导致分类错误率高的原因就是我们下一步应该解决的问题。例如统计结果如下图所示的话,就应该主要解决大型猫科动物和模糊图片导致分类错误的问题。
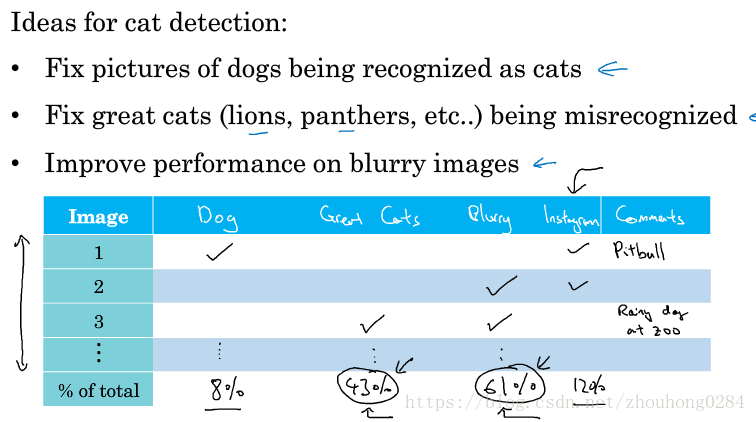
以上讲的都是分类错误的情况,还有一种情况是人工标记label错误,当训练集中有错误时:如果是随机错误而不是系统错误,那么对深度学习的模型影响是很小的,我们可以不作处理;当测试集中有错误时:我们可以在误差分析中加上一栏(标记错误),然后统计标记错误造成的误差。

当标记错误只占分类错误的一小部分的时候,或许不做处理也是ok的;但是当标记错误占分类错误的比例较大时,我们应该去修正标记错误,此时标记错误已经影响到我们评估模型了。
当需要去修正标记错误的样本时要注意以下几点:
1.如果要进行修正的话,要同时对训练和测试集做相同的处理,因为训练测试集应该来自同一个分布;
2.检查分类出错的样本的同时也应该检查分类对的样本,否则可能出现偏差大的情况;(成本高)
3.有时候只需要修正测试数据集,此时造成的训练集与测试集分布的轻微不同是可以接受的。
构建初始的系统然后进行迭代!使用方差偏差分析、误差分析来提高初始模型的性能。
当划分traning/dev/test set遇到困难
假设我们收集到的猫图片有200000张来自内部数据,只有10000张来自实际用户,那怎么划分呢?
要注意的是dev/test set的作用就是为了设定一个目标,因此这个目标和最后的使用场景应该是最接近的,因此来自实际用户的照片应该被分到dev/test set中,否则训练出来的模型实际使用效果就不好。
但这个会导致训练集和测试集的分布不同,这时候如果训练误差和测试误差的差别较大的话,我们无法判别是数据分布不同的原因还是模型存在方差偏差的原因,这时采用的方法是在训练集中分出一部分作为traning-dev set来衡量模型是否存在方差偏差问题。
这是我们有的误差有:
bayes error
traning error
training-dev set
dev set
前两者之间衡量的是偏差问题,其次两个之间衡量的是方差问题。再其次衡量的是样本集分布不均匀的问题。
如果发现了样本分布不同的问题,此时可以采用以下几个方法来适当的改进结果:
1.对出错的测试样本进行误差分析,尽量收集能够改进这方面的样本;
2.人工合成与测试集相似的训练集,但这个有一个可能是导致学习算法过度拟合人工加入的元素。
任务迁移
什么时候使用任务迁移呢?这里我们认为是从任务A迁移到任务B:
1.当两项任务具有同样的输入时;
2.当任务A的训练样本多于任务B时;
3.从任务A中学习到的低层次的特征对B有帮助时。
例如,我们有10000张图片用于图片识别猫,有100张图片用于X射线分析,那么由于两者都是图片输入,且前者比后者数量上大得多,而且猫图片分析的底层特征,比如说线条等对B有帮助,那么我们就可以使用任务A的训练出的模型的底层参数训练任务B,此时只需要修改任务B最后一两层的参数即可。
多任务学习
多任务学习在实际中应用比较少,典型的一个例子是物体检测。同时检测多个物体可能比单独检测一个物体的效果要好。
要注意:多任务学习的输出不是softmax的损失函数,而是多个logistic损失函数的累加。因为一个输入样本可以由多个标签而不是一个标签。
比如说在一张图片中检测是否有行人,车辆,指示牌。我们可以训练三个单独的神经网络,也可以使用多任务学习来训练一个较庞大的神经网络。
什么时候多任务学习是有意义的呢?
1.训练其他任务得到的底层特征可以帮助用来训练这个任务;
2.训练各个任务的数据集大小差不多;
3.(硬件上)能够训练一个较为庞大的神经网络。对于多任务学习来说,需要训练的神经网络显然比单个模型要大。
end-to-end deep learning
实例:语音识别。
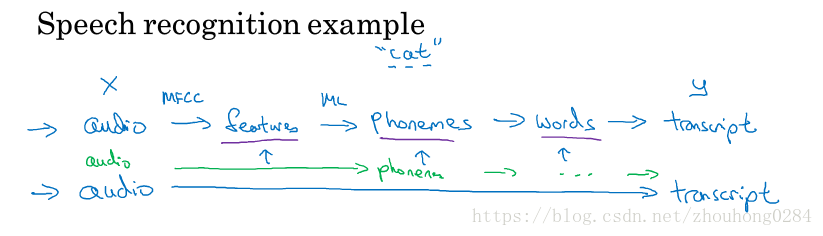
以前我们需要流水线工作训练每个组块,现在可能输入语音可以直接得到结果,这就是端到端的深度学习。
一般来说,端到端的学习要求训练样本的数据要很大。因此,它不一定是全能的。比如说在人脸识别中,要一下子输入含有人脸的图片,输出是否为公司的人员这种对应的训练数据是很少的,因此我们可以把它划分为两步:首先在一张图片中学习如何框出人脸,然后学习对放大的人脸进行判断是否与数据库中的人脸匹配。相比来说,后面这两步都有比较大的训练集。
