当需要对网络进行调整的时候,你可以有很多不同的方向,但是怎么选择一个方向呢?有些方向可能对你的网络没有任何作用
这就是机器学习策略
1. 正交化:对一个功能的调整应该尽量不影响到其它功能
互成90度,每个功能由一个单独的装置控制,通过对各装置调整以实现对一个综合效果的实现
比如想要让车有90的速度和60的角度,那么通过两个单独的按钮分别控制这两个要素来实现(而不是用一个按钮同时控制)
1.2 正交化与机器学习

2. 单一数字评估指标(single number evaluation metric)
当你有多个模型时,如果有多项评估指标,则很难一下子找出哪个模型是比较好的。所以一般采用一个dev set 和 一个评估指标
例:对猫的识别
有两个指标:precision查准率(识别成猫的中有多少真的是猫),recall查全率(有多少猫被识别出来),那可以采用调和平均数(F1 score = 1 / (1/p + 1/r))来作为评估指标,而不是用两个
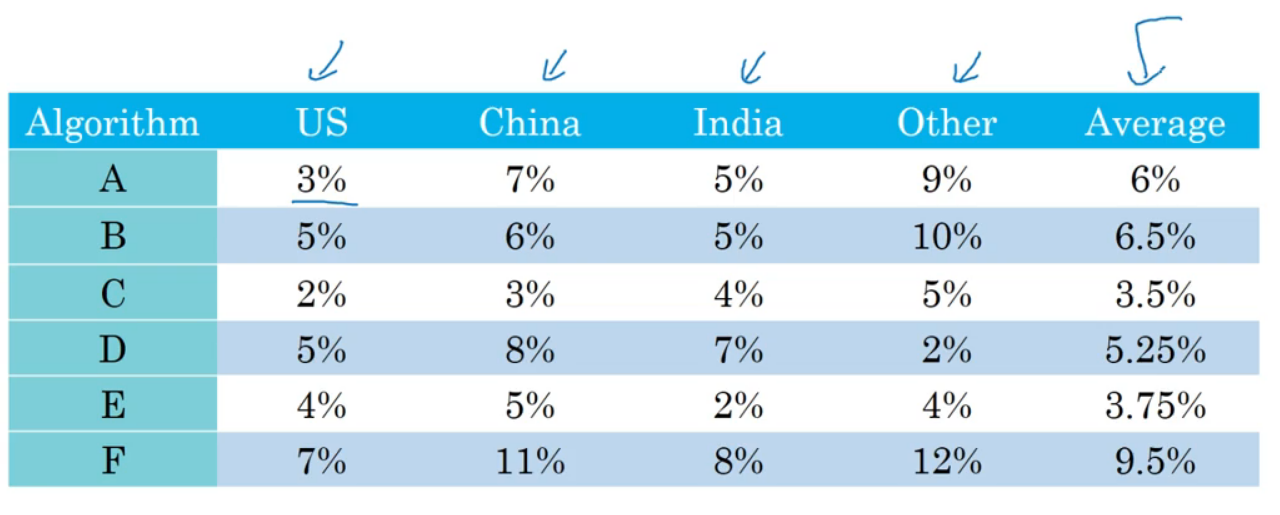
例:下面这个是更多大一点的,就更难找出哪个是最好的
3. 优化指标和满足指标
如果不方便把所有指标合并成单一值,那么可以变成两个,一个是优化指标(尽量做到更好),一个是满足指标(只要符合一定要求即可)
一般地,有N个指标,可以把一个当成优化,其它当成满足
例:唤醒设备的语音识别,比如hi,siri等
那要评估的指标有说出相应词唤醒的成功率(优化指标),以及没有真的说话时被错误唤醒的次数(满足指标)
4. 怎么选择dev/test数据集
要来自同一个分布!dev其实是设定了一个目标,如果test和dev分布不同,那么就会让后来的目标与原来的目标有偏差,结果并不好
例:用中等收入的zip code作为dev数据集评估他们是否有还款能力,以便决定是否可以放款。最后却用低收入区域的zip code作为test进行测试,这将导致结果不正确,你还需要重新再训练
5. train和dev的大小
现在数据量很大,可以采用98%/1%/1%,1%给dev/test其实就已经足够了。有时人们会不设置test,而是直接在dev上进行迭代评估,如果dev足够大,不会过拟合,这种方案也是可以的
6. 什么时候应该改变dev/test或metric
例:一个对猫进行分类的分类器,两个model,一个错误率为3%,另一个为5%,可是3%的可能会把黄色图片当成猫,而这是不能被允许的。这里可以修改一个metric,增加权重,当出现这种情况时得到更大的处罚值
为了能使用这种错误率计算公式,你就需要先人工先进行评估

设定一个评价metric,和如何达到好的结果两个应该分开考虑
例:在dev/test上结果很好,如识别图片(dev/test是高清的),但是用户的图片是比较模糊的,所以在实际中运用结果并不理想,这时应该修改dev/test
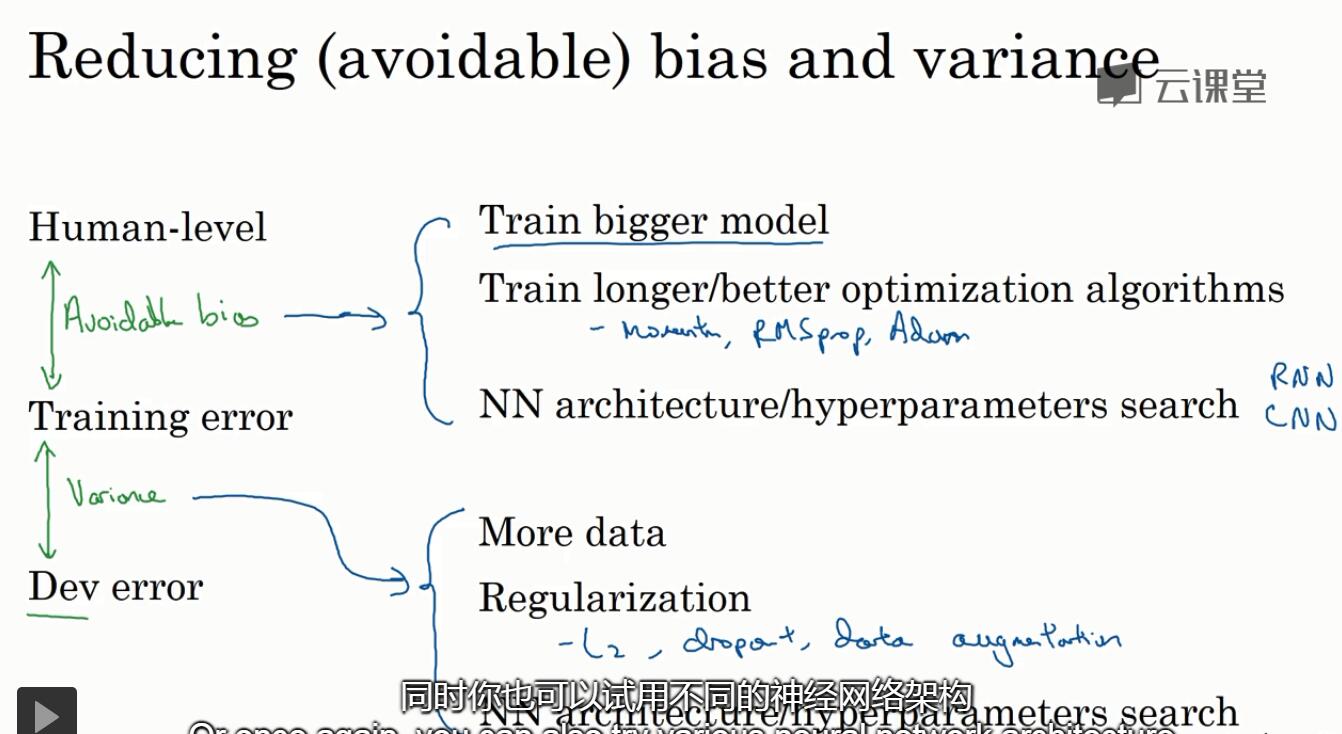
7. 可避免偏差avoiable bias
人类的错误率(用来估计贝叶斯错误)和train上错误率的差值:可避免偏差
train上和dev上错误率差值:方差
根据偏差大还是方差大来决定应该调整的方向
8. human-level performance 人类对一件事的判断错误率
不同的群体对一件事的错误率是不同的,而最优的那个一般才是用来估计贝叶斯错误
9. 超越人类?
如果给够多的数据、结构化的数据,非感观的评判,那么机器可能会比人类做得好。比如广告点击、运输时间等
目前在感观上的某些领域机器也会做得很好,比如语音识别。这种情况下,以人类水平的错误率估计的贝叶斯错误率可能会比train的错误要高