笔记目录(部分笔者省略)
Unsupervised Domain-Specific Deblurring via Disentangled Representations
arXiv:1903.01594v2 [cs.CV] 5 Aug 2019
通过解缠表示的无监督领域特定图像去模糊
注:限于作者水平,本笔记难免存在不妥之处,欢迎批评指正

文章的创新和优势所在:
内容编码器和模糊编码器将模糊图像的内容和模糊特征区分开,实现了高质量的图像去模糊;
对模糊编码器添加 KL 散度损失以阻止模糊特征对内容信息进行编码;
为了保留原始图像的内容结构,在框架中添加了模糊图像构造和循环一致性损失,同时添加的感知损失有助于模糊图像去除不切实际的伪像。
模糊编码器主要的作用是用来捕获模糊图像的模糊特征,如何去保证这个模糊编码器是真的提取到模糊图像的模糊特征?
采用了迂回的思路,清晰的图像是不含模糊信息的,清晰的图像通过结合模糊编码器模糊特征去生成出模糊图像,模糊编码器是在对清晰图像做模糊化处理,模糊化的前提是模糊编码器确实提取到了图像的模糊特征,所以说由清晰图像生成模糊图像也保证了模糊编码器是对图像的模糊信息进行编码的作用。
文章为了保证模糊图像的内容编码器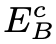 是对模糊图像的内容进行编码,文章将清晰图像内容编码器
是对模糊图像的内容进行编码,文章将清晰图像内容编码器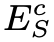 和模糊图像内容编码器
和模糊图像内容编码器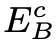 强制执行最后一层共享权重,以指导
强制执行最后一层共享权重,以指导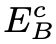 学习如何从模糊图像中有效地提取内容信息。
学习如何从模糊图像中有效地提取内容信息。
由模糊图像去模糊到清晰图像的过程中,将模糊图像内容编码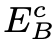 和模糊编码
和模糊编码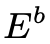 送入清晰图像生成器
送入清晰图像生成器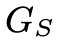 重构得到去模糊的清晰图像,清晰图像到模糊图像是为了优化模糊编码
重构得到去模糊的清晰图像,清晰图像到模糊图像是为了优化模糊编码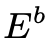 和模糊图像的内容编码
和模糊图像的内容编码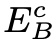 的作用。
的作用。

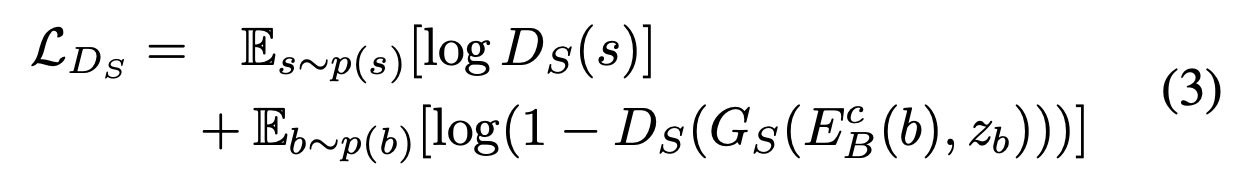



感知损失中使用模糊图像 b 而不是锐利图像作为参考图像有两个主要原因。首先,假设 b 的内容信息可以由预训练的 CNN 提取。其次,由于 s 和 b 未配对,因此在 s 和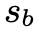 之间应用感知损失将迫使
之间应用感知损失将迫使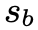 对 s 中的无关内容信息进行编码。值得一提的是,
对 s 中的无关内容信息进行编码。值得一提的是,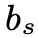 和 s 上没有添加感知损失。这是因为在训练期间没有在
和 s 上没有添加感知损失。这是因为在训练期间没有在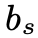 

中发现明显的伪像。




PSNR是“Peak Signal to Noise Ratio”的缩写,即峰值信噪比,是一种评价图像的客观标准
SSIM(structural similarity index),结构相似性,是一种衡量两幅图像相似度的指标



文章提出了一种无监督的领域特定单图像去模糊方法。通过解开模糊图像中的内容和模糊特征,并添加 KL 散度损失以阻止模糊特征对内容信息进行编码。为了保留原始图像的内容结构,在框架中添加了模糊分支和循环一致性损失,同时添加的感知损失有助于模糊图像去除不切实际的伪像。每个组件的消融研究显示了不同模块的有效性。
文章的创新之处正是内容编码器和模糊编码器的设计和应用,尝试将内容和模糊信息分离,这对图像到图像的工作具有一定的指导意义。