DeBERTa:具有分离注意力的解码增强型 BERT
摘要
预训练神经语言模型的最新进展显着提高了许多自然语言处理 (NLP) 任务的性能。
在本文中,我们提出了一种新的模型架构 DeBERTa(Decoding-enhanced BERT with disentangled attention),它使用两种新技术改进了 BERT 和 RoBERTa 模型。第一个是分离的注意力机制,其中每个单词分别使用两个对其内容和位置进行编码的向量表示,单词之间的注意力权重分别使用其内容和相对位置的分离矩阵来计算。其次,使用增强的掩码解码器将绝对位置合并到解码层中,以预测模型预训练中的掩码标记。此外,一种新的虚拟对抗训练方法用于微调以提高模型的泛化能力。
我们表明,这些技术显着提高了模型预训练的效率以及自然语言理解 (NLU) 和自然语言生成 (NLG) 下游任务的性能。与 RoBERTa-Large 相比,在一半训练数据上训练的 DeBERTa 模型在广泛的 NLP 任务上始终表现更好,在 SQuAD v2.0 上的 MNLI 上实现了 +0.9% 的改进(90.2% 对 91.1%) +2.3%(88.4% 对 90.7%),RACE 增长 +3.6%(83.2% 对 86.8%)。值得注意的是,我们通过训练一个更大的版本来扩展 DeBERTa,该版本由 48 个变换层和 15 亿个参数组成。显着的性能提升使得单个 DeBERTa 模型在宏观平均得分(89.9 对 89.8)方面首次超过了 SuperGLUE 基准(Wang 等人,2019a)上的人类表现,并且集成 DeBERTa 模型位于 SuperGLUE 之上截至 2021 年 1 月 6 日的排行榜,以可观的优势超过了人类基线(90.3 对 89.8)。预训练的 DeBERTa 模型和源代码发布在:https://github.com/microsoft/DeBERTa1。
介绍
Transformer 已成为神经语言建模最有效的神经网络架构。与按顺序处理文本的循环神经网络 (RNN) 不同,Transformers 应用自注意力来并行计算输入文本中的每个单词的注意力权重,以衡量每个单词对另一个单词的影响,因此在处理方面比 RNN 允许更多的并行化大规模模型训练(Vaswani et al., 2017)。自 2018 年以来,我们看到了一组大规模的基于 Transformer 的预训练语言模型 (PLM) 的兴起,例如 GPT (Radford et al., 2019; Brown et al., 2020)、BERT (Devlin et al., 2020) al., 2019), RoBERTa (Liu et al., 2019c), XLNet (Yang et al., 2019), UniLM (Dong et al., 2019), ELECTRA (Clark et al., 2020), T5 (Raffel et al., al., 2020)、ALUM (Liu et al., 2020)、StructBERT (Wang et al., 2019c) 和 ERINE (Sun et al., 2019)。这些 PLM 已使用特定于任务的标签进行了微调,并在许多下游自然语言处理 (NLP) 任务中创造了最新的技术水平(Liu 等人,2019b;Minaee 等人,2020;Jiang 等人,2020; He et al., 2019a;b; Shen et al., 2020)。
在本文中,我们提出了一种新的基于 Transformer 的神经语言模型 DeBERTa(Decodingenhanced BERT with disentangled attention),它使用两种新技术改进了以前最先进的 PLM:一种分离的注意力机制和一个增强的掩码解码器。
Disentangled attention(分散注意力) 。与输入层中的每个单词使用其单词(内容)嵌入和位置嵌入之和的向量来表示的BERT不同,DeBERTa中的每个单词使用分别对其内容和位置进行编码的两个向量来表示,并且使用分别基于单词的内容和相对位置的解缠结矩阵来计算单词之间的注意力权重。 这是由于观察到单词对的注意力权重不仅取决于它们的内容,还取决于它们的相对位置。例如,“deep”和“learning”这两个词相邻出现时,它们之间的依赖性要比出现在不同的句子中时强得多。
Enhanced mask decoder(增强的掩码解码器)。与 BERT 一样,DeBERTa 使用掩码语言建模 (MLM) 进行了预训练。 MLM 是一项填空任务,其中教导模型使用掩码标记周围的单词来预测掩码单词应该是什么。 DeBERTa 将上下文词的内容和位置信息用于 MLM。解缠注意机制已经考虑了上下文词的内容和相对位置,但没有考虑这些词的绝对位置,这在许多情况下对预测至关重要。考虑句子“a new store opening beside the new mall”,斜体字“store”和“mall”被屏蔽以进行预测。虽然这两个词的局部上下文相似,但它们在句子中扮演不同的句法角色。 (这里,例如,句子的主语是“store”而不是“mall”。)这些句法上的细微差别在很大程度上取决于单词在句子中的绝对位置,因此重要的是要考虑一个词在语言建模过程中的绝对位置。 DeBERTa 在 softmax 层之前结合了绝对词位置嵌入,在该层中,模型根据词内容和位置的聚合上下文嵌入对掩码词进行解码。
此外,我们还提出了一种新的虚拟对抗性训练方法,用于微调PLM到下游的NLP任务。该方法有效地提高了模型的泛化能力
我们通过一项全面的实证研究表明,这些技术大大提高了预训练的效率和下游任务的性能。在NLU任务中,与Roberta-Large相比,基于一半训练数据的DeBERTa模型在广泛的NLP任务中表现一致更好,MNLI提高了+0.9%(90.2%对91.1%),班队v2.0提高了+2.3%(88.4%对90.7%),种族提高了+3.6%(83.2%对86.8%)。在NLG任务中,DeBERTa将Wikitext-103数据集上的困惑从21.6降低到19.5。我们通过预先训练一个更大的模型来进一步扩大DeBERTa,该模型由48个变压器层和15亿个参数组成。单个1.5B参数的DeBERTa模型在Superglue基准(Wang等人,2019a)上大大超过了具有110亿个参数的T5,高出0.6%(89.3%对89.9%),并首次超过人类基线(89.9vs.89.8)。截至2021年1月6日,DeBERTa合唱团模特位居Superglue排行榜榜首,以相当大的优势超过人类基准(90.3对89.8)。

2 背景
2.1 TRANSFORMER
基于Transformer的语言模型由堆叠的Transformer块组成(Vaswani等人,2017)。每个块包含一个多头自关注层,其后是一个完全连接的位置前馈网络。标准的自我注意机制缺乏一种自然的方式来编码单词位置信息。因此,现有方法向嵌入的每个输入词添加位置偏差,使得每个输入词由其值取决于其内容和位置的矢量来表示。位置偏差可以使用绝对位置嵌入(Vaswani等人,2017;Radford等人,2019;Devlin等人,2019)或相对位置嵌入(Huang等人,2018;Yang等人,2019)来实现。研究表明,相对位置表征对于自然语言理解和生成任务更有效(Dai等人,2019年;Shaw等人,2018年)。与现有的注意解缠机制不同的是,我们使用两个独立的向量来表示每个输入词,这两个向量分别表示词的内容和位置,而词之间的注意力权重则分别使用解缠矩阵来计算。
2.2 MASKED LANGUAGE MODEL(屏蔽语言模型)
大规模基于 Transformer 的 PLM 通常在大量文本上进行预训练,以使用称为掩蔽语言模型 (MLM) 的自我监督目标来学习上下文词表示 (Devlin et al., 2019)。具体来说,给定一个序列 X = {xi},我们通过随机屏蔽 15% 的标记将其破坏为 X,然后训练一个由 θ 参数化的语言模型,通过预测以 X 为条件的屏蔽标记〜x 来重建 X
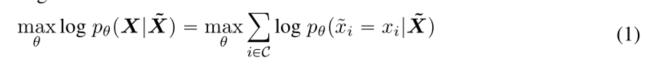
这里 C 是序列中被屏蔽标记的索引集。 BERT 的作者建议保持 10% 的掩码标记不变,另外 10% 替换为随机选择的标记,其余的替换为 [MASK] 标记。
3 THE DEBERTA ARCHITECTURE
3.1 DISENTANGLED ATTENTION: A TWO-VECTOR APPROACH TO CONTENT AND POSITION EMBEDDING(解开注意力:内容和位置嵌入的双向量方法)
对于序列中位置i处的标记,我们使用两个向量 { H i } \{H_i\} { Hi}和 { P i ∣ j } \{P_{i|j}\} { Pi∣j}来表示它,这两个向量分别表示其内容和与位置j处的标记的相对位置。令牌i和j之间的交叉注意分数的计算可以分解为以下四个组成部分
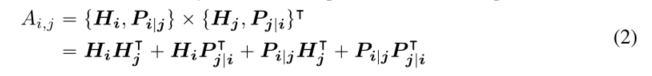
也就是说,词对的注意力权重可以通过使用其内容和位置上的去纠缠矩阵作为内容对内容、内容对位置、位置对内容和位置对位置的分离矩阵来计算为四个注意力分数之和。
现有的相对位置编码方法在计算注意权重时使用单独的嵌入矩阵来计算相对位置偏差(Shaw等人,2018年;Huang等人,2018年)。这相当于只使用公式2中的内容到内容和内容位置项来计算注意力权重。我们认为位置到内容项也很重要,因为词对的注意力权重不仅取决于它们的内容,而且取决于它们的相对位置,这只能使用内容到位置项和位置到内容项来完全建模。由于我们使用相对位置嵌入,位置到位置项不提供太多附加信息,并且在我们的实现中从公式2中删除。
以单头注意为例,标准的自我注意操作(Vaswani等人,2017)可表述为:
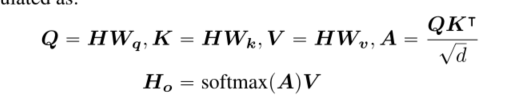

其中,H P RNˆd表示输入隐藏向量,HO P RNˆd表示自我注意的输出,Wq,Wk,WV P Rdˆd表示投影矩阵,A P RNˆN表示注意矩阵,N表示输入序列的长度,以及d表示隐藏状态的维度。
表示k为最大相对距离,δpi,jq P r0,2kq为令牌i到令牌j的相对距离,其定义为: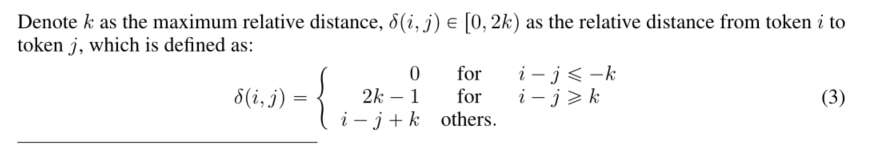
我们可以将具有相对位置偏差的未纠缠的自我注意表示为等式4,其中Qc、Kc和Vc分别是使用投影矩阵Wq、c、wk、c、Wv、c和c P Rdˆd生成的投影内容向量,P P R2kˆd表示在所有层之间共享的相对位置嵌入向量(即,在前向传播期间保持固定),以及Qr和KRare分别使用投影矩阵Wq、r、wk、r P Rdˆd生成的投影相对位置向量。
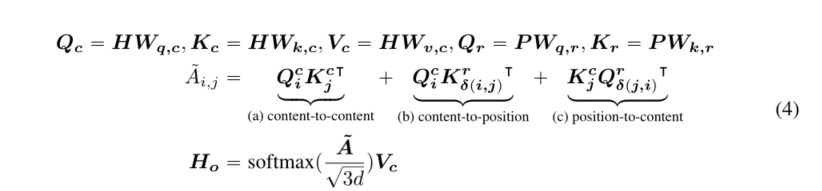
在这里插入图片描述
结论
本文提出了一种新的模型架构 DeBERTa(Decoding-enhanced BERT with disentangled attention),它使用两种新技术改进了 BERT 和 RoBERTa 模型。
第一个是分离的注意力机制,其中每个单词分别使用两个对其内容和位置进行编码的向量表示,单词之间的注意力权重分别使用其内容和相对位置的分离矩阵来计算。第二个是增强的掩码解码器,它在解码层中结合绝对位置来预测模型预训练中的掩码标记。
此外,一种新的虚拟对抗训练方法用于微调,以提高模型对下游任务的泛化能力。我们通过全面的实证研究表明,这些技术显着提高了模型预训练的效率和下游任务的性能。具有 15 亿个参数的 DeBERTa 模型在宏观平均得分方面首次超越了 SuperGLUE 基准测试中的人类表现。 DeBERTa 在 SuperGLUE 上超越人类的表现标志着迈向通用 AI 的重要里程碑。尽管在 SuperGLUE 上取得了可喜的成果,但该模型绝不会达到 NLU 的人类智能水平。人类非常擅长利用从不同任务中学到的知识来解决新任务,而无需或很少有特定任务的演示。这被称为组合泛化,即泛化到熟悉成分(子任务或基本解决问题的技能)的新组合(新任务)的能力。展望未来,值得探索如何使 DeBERTa 以更明确的方式结合组合结构,这可以允许将类似于人类所做的自然语言的神经和符号计算结合起来。