文章目录
一、裁剪、压缩、累乘
1、裁剪
- 概念:指的是削掉波峰或波谷这类型的,将调用数组中小于min的元素设置为min,大于max的元素设置为max
- 用法:ndarray.clip(min=最小值, max=最大值)
2、压缩
- 概念:返回调用数组中满足给定条件的元素
- 用法:ndarray.compress(条件)
3、累乘
- 结果累乘:返回调用数组中各元素的乘积,是累乘结果
ndarray.prod() - 过程累乘:返回调用数组中个元素计算累乘的过程数组,是累乘过程
ndarray.cumprod()
4、练习代码
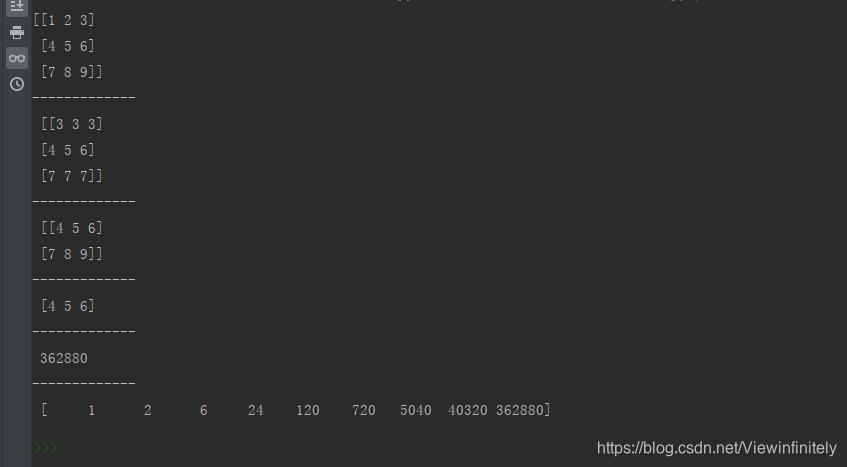
import numpy as np
a = np.arange(1, 10).reshape(3, 3)
print(a)
# 裁剪
b = a.clip(min=3, max=7)
print('-------------\n', b)
# 压缩
c = a.compress(a.ravel() > 3).reshape(-1, 3)
# 压缩只能处理一维数组,因此需要ravel扁平化一下,在reshape变为任意行3列的二维数组
print('-------------\n', c)
# 因为条件两边都是布尔型数组,不是单单的布尔值,不能用and
# 当有多个条件时,需要用 & 符号做与运算,并且在两边加上小括号()
d = a.compress((3 < a.ravel()) & (a.ravel() < 7))
print('-------------\n', d)
# 累乘结果
e = a.prod()
print('-------------\n', e)
# 累乘过程
f = a.cumprod()
print('-------------\n', f)
二、样本相关性曲线
1、样本相关性系数与相关性矩阵
-
样本:
a = [a1, a2, …, an]
b = [b1, b2, …, bn] -
均值:
ave(a) = (a1 + a2 + … + an)/n
ave(b) = (b1 + b2 +… + bn)/n -
离差:
dev(a) = [a1, a2, …, an] - ave(a)
dev(b) = [b1, b2, …, bn] - ave(b) -
方差:
var(a) = ave(dev(a)dev(a))
var(b) = ave(dev(b)dev(b)) -
标准差:
std(a) = sqrt(var(a))
std(b) = sqrt(var(b)) -
协方差:反映协同效应
cov(a,b) = ave(dev(a)dev(b))
cov(b,a) = ave(dev(b)dev(a)) -
样本相关性系数:
反映相关性程度,[-1, 1]之间的一个数,正负表示了相关性的方向,绝对值表示相关性的强弱,0表示不相关。
-
样本相关性矩阵
cov(a,b)/std(a)std(b))
cov(b,a)/std(b)std(a))
2、用numpy计算相关性矩阵
- numpy.corrcoef(a, b)
a,b参数分别对应两条曲线的当天的日收益(收益理想差分-每天的收盘价)
3、样本相关性案例
import datetime as dt
import numpy as np
import matplotlib.pylab as mp
import matplotlib.dates as md
def dmy2ymd(dmy):
dmy = str(dmy, encoding='utf-8') # 转码dmy日期
date = dt.datetime.strptime(dmy, '%d-%m-%Y').date() # 获取时间对象
ymd = date.strftime('%Y-%m-%d')
return ymd
dates, beer_closing_prices = np.loadtxt(
'0=数据源/beer_price2.csv', delimiter=',',
usecols=(0, 4), unpack=True,
dtype=np.dtype('M8[D], f8'),
converters={0: dmy2ymd}
)
__, apple_closing_prices = np.loadtxt(
'0=数据源/apple_price.csv', delimiter=',',
usecols=(0, 4), unpack=True,
dtype=np.dtype('M8[D], f8'),
converters={0: dmy2ymd}
)
# 用理想差分(后一天减去前一天的值)求日收益,再除每天的收盘价
beer_returns = np.diff(beer_closing_prices)/beer_closing_prices[:-1]
apple_returns = np.diff(apple_closing_prices)/apple_closing_prices[:-1]
# 算样本平均值、离差、方差和标准差
ave_a = np.mean(beer_returns) # 均值
dev_a = beer_returns - ave_a # 离差
var_a = np.mean(dev_a * dev_a) # 方差
std_a = np.sqrt(var_a) # 标准差
ave_b = np.mean(apple_returns)
dev_b = apple_returns - ave_b
var_b = np.mean(dev_b * dev_b)
std_b = np.sqrt(var_b)
# 算协方差
cov_ab = np.mean(dev_a * dev_b)
cov_ba = np.mean(dev_b * dev_a)
# 相关性矩阵
covs = np.array([
[var_a, cov_ab],
[cov_ba, var_b]
])
stds = np.array([
[std_a * std_a, std_a * std_b],
[std_b * std_a, std_b * std_b]
])
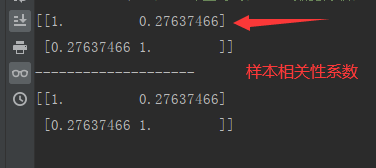
corr = covs / stds
print(corr, end='\n--------------------\n') # 打印相关性矩阵,左斜对角线是相关性系数,即相关度;右斜对角线都是1
# 用numpy计算相关性矩阵
corr2 = np.corrcoef(beer_returns, apple_returns)
print(corr2)
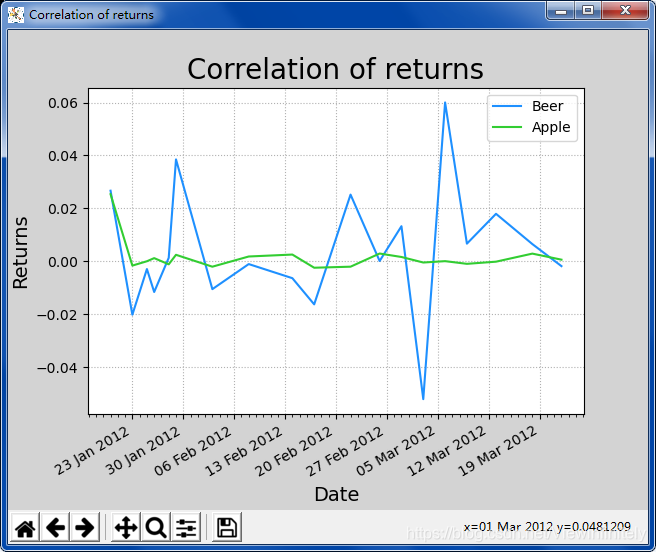
# 曲线图基础设置
mp.figure('Correlation of returns', facecolor='lightgray')
mp.title('Correlation of returns', fontsize=20)
mp.xlabel('Date', fontsize=14)
mp.ylabel('Returns', fontsize=14)
# 主刻度设置为以周一为起始的星期格式
ax = mp.gca() # 获取刻度线(坐标轴)
ax.xaxis.set_major_locator(
md.WeekdayLocator(byweekday=md.MO)
)
# 次刻度设置为以天为单位
ax.xaxis.set_minor_locator(
md.DayLocator()
)
# 主刻度的格式化
ax.xaxis.set_major_formatter(
md.DateFormatter('%d %b %Y')
)
mp.tick_params(labelsize=10) # 字体
mp.grid(linestyle=':') # 网格线
# 绘制曲线
dates = dates.astype(md.datetime.datetime) # 将日期标准化成numpy的日期
mp.plot(dates[:-1], beer_returns, c='dodgerblue', label='Beer')
mp.plot(dates[:-1], apple_returns, c='limegreen', label='Apple')
mp.legend() # 显示图例
mp.gcf().autofmt_xdate() # 设置格式展示的自动化调整
mp.show() # 显示图像
4、案例效果