以下是学习恋上数据结构与算法的记录,本篇主要内容是图
◼图(Graph)
●图由顶点(vertex)和边(edge)组成,通常表示为G = (V, E)
✓G表示一个图,V是顶点集,E是边集
✓顶点集V有穷且非空
✓任意两个顶点之间都可以用边来表示它们之间的关系,边集E可以是空的

●图有2种常见的实现方案
✓邻接矩阵(Adjacency Matrix)有权图
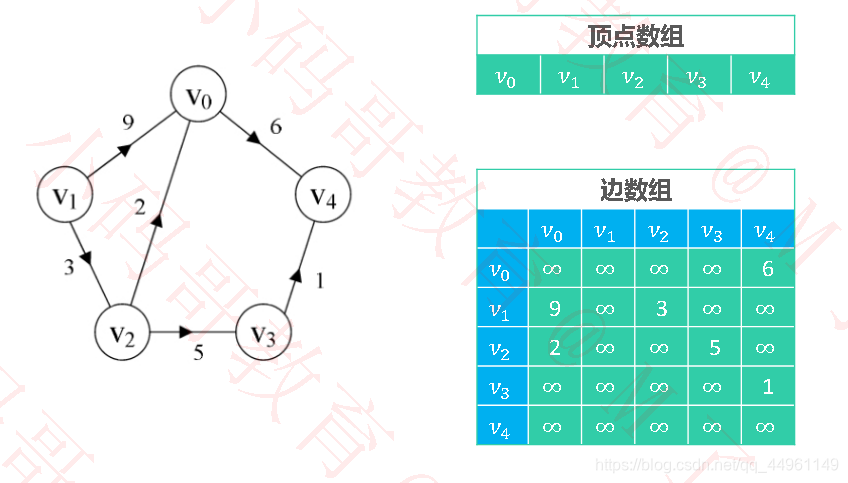
✓邻接表(Adjacency List)有权图

图的基础接口
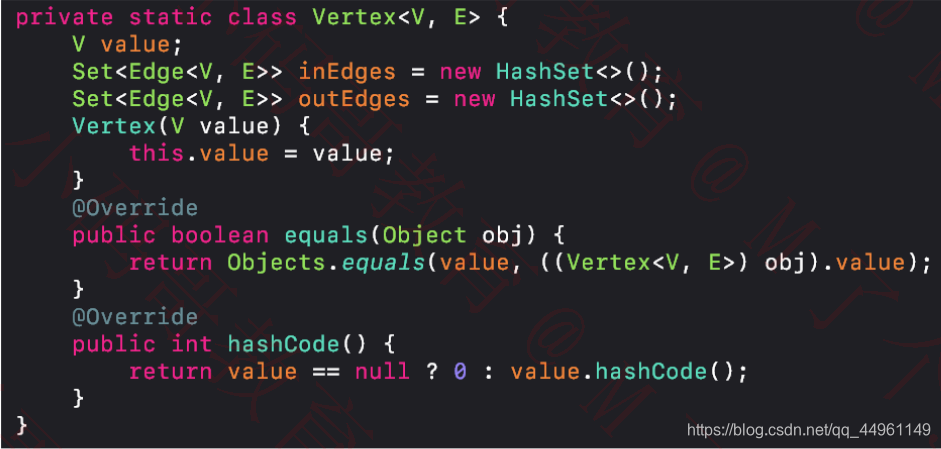
 顶点的定义
顶点的定义
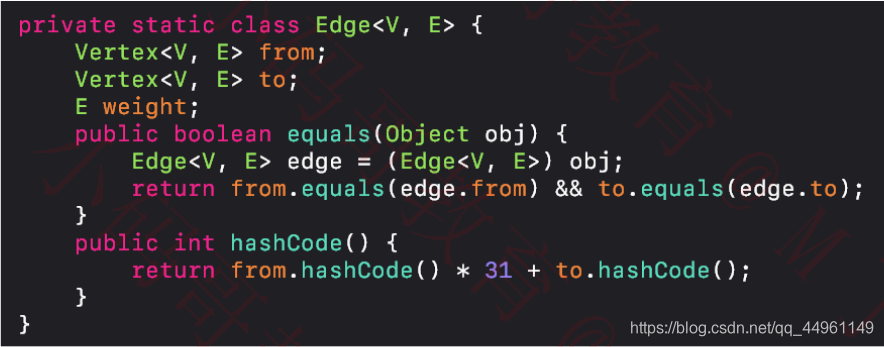
边的定义
其接口基本实现Java代码如下
public class ListGraph<V, E> extends Graph<V, E> {
private static class Vertex<V, E> {
V value;
Set<Edge<V, E>> inEdges = new HashSet<>();
Set<Edge<V, E>> outEdges = new HashSet<>();
public Vertex(V value) {
this.value = value;
}
@Override
public boolean equals(Object obj) {
return Objects.equals(value, ((Vertex<V, E>) obj).value);
}
@Override
public int hashCode() {
return value == null ? 0 : value.hashCode();
}
@Override
public String toString() {
return value == null ? "null" : value.toString();
}
}
private static class Edge<V, E> {
Vertex<V, E> from;
Vertex<V, E> to;
E weight;
Edge(Vertex<V, E> from, Vertex<V, E> to) {
this.from = from;
this.to = to;
}
EdgeInfo<V, E> info() {
return new EdgeInfo<>(from.value, to.value, weight);
}
@Override
public boolean equals(Object obj) {
Edge<V, E> edge = (Edge<V, E>) obj;
return Objects.equals(from, edge.from) && Objects.equals(to, edge.to);
}
@Override
public int hashCode() {
return from.hashCode() * 31 + to.hashCode();
}
@Override
public String toString() {
return "Edge [from=" + from + ", to=" + to + ", weight=" + weight + "]";
}
}
private Map<V, Vertex<V, E>> vertices = new HashMap<>();
private Set<Edge<V, E>> edges = new HashSet<>();
private Comparator<Edge<V, E>> edgeComparator = (Edge<V, E> e1, Edge<V, E> e2) -> {
return weightManager.compare(e1.weight, e2.weight);
};
@Override
public int edgesSize() {
return edges.size();
}
@Override
public int verticesSize() {
return vertices.size();
}
@Override
public void addVertex(V v) {
if(vertices.containsKey(v)) return;
vertices.put(v, new Vertex<>(v));
}
@Override
public void addEdge(V from, V to) {
addEdge(from, to, null);
}
//添加边
public void addEdge(V from, V to, E weight) {
//from节点
Vertex<V, E> fromVertex = vertices.get(from);
//如果没有from,就创建一个节点
if (fromVertex == null) {
fromVertex = new Vertex<>(from);
vertices.put(from, fromVertex);
}
//to节点
Vertex<V, E> toVertex = vertices.get(to);
if (toVertex == null) {
toVertex = new Vertex<>(to);
vertices.put(to, toVertex);
}
//创建对应边
Edge<V, E> edge = new Edge<>(fromVertex, toVertex);
edge.weight = weight;
//edge.weight = weight;
//如果之前存在这个边,就删除再添加,进行覆盖操作
if(fromVertex.outEdges.remove(edge)) {//如果能remove,就代表存在该边
toVertex.inEdges.remove(edge);
edges.remove(edge);
}
//from的outedge添加
fromVertex.outEdges.add(edge);
//to的inedge添加
toVertex.inEdges.add(edge);
//edges添加
edges.add(edge);
}
@Override
public void removeVertex(V v) {
Vertex<V, E> vertex = vertices.remove(v);//删除该顶点
if(vertex==null) return;
//维护该顶点有关的边
//若需要边遍历边删除,Java最好使用迭代器
//顶点outEdges的删除维护
for(Iterator<Edge<V, E>> iterator = vertex.outEdges.iterator();iterator.hasNext();) {
Edge<V, E> edge = iterator.next();
edge.to.inEdges.remove(edge);
//将当前遍历到的元素edge从集合vertex.outEdges中删掉
iterator.remove();
edges.remove(edge);
}
for (Iterator<Edge<V, E>> iterator = vertex.inEdges.iterator(); iterator.hasNext();) {
Edge<V, E> edge = iterator.next();
edge.from.outEdges.remove(edge);
// 将当前遍历到的元素edge从集合vertex.inEdges中删掉
iterator.remove();
edges.remove(edge);
}
}
@Override
public void removeEdge(V from, V to) {
Vertex<V, E> fromVertex = vertices.get(from);
if(fromVertex==null) return;
Vertex<V, E> toVertex = vertices.get(to);
if(toVertex==null) return;
Edge<V, E> edge = new Edge<>(fromVertex, toVertex);
if(fromVertex.outEdges.remove(edge)) {
toVertex.inEdges.remove(edge);
edges.remove(edge);
}
}
图的遍历
从图中某一顶点出发访问图中其余顶点,且每一个顶点仅被访问一次
广度优先搜索(Breadth First Search)
之前所学的二叉树层序遍历就是一种广度优先搜索
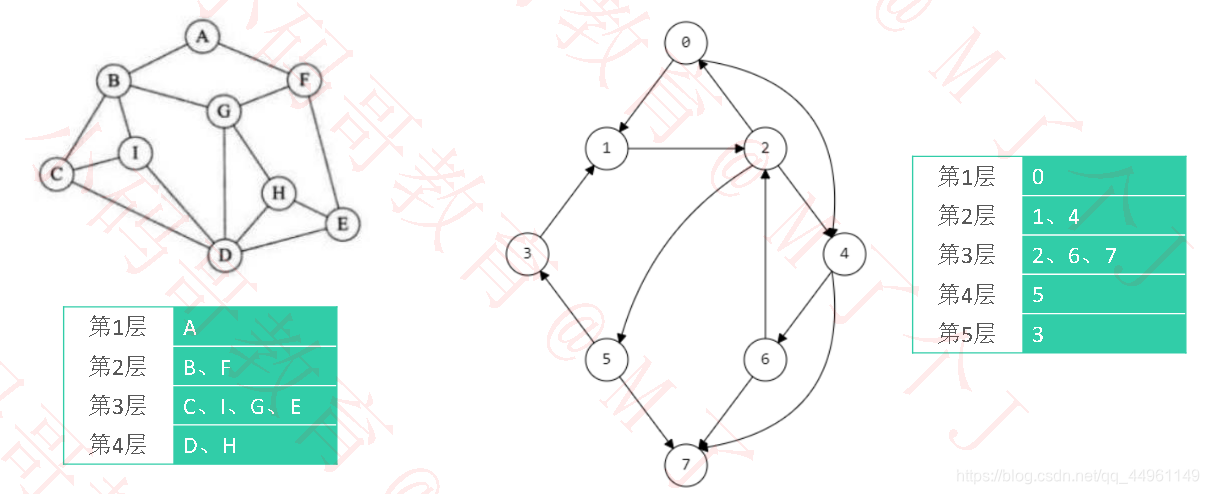 从A顶点出发,沿出边所能到达的顶点B、F为第二层
从A顶点出发,沿出边所能到达的顶点B、F为第二层
从第二层B、F所到达顶点有C、I、G、E为第三层
最后从第三层能到达的顶点则是D、H第四层
广度优先搜索顺序则从第一层到最后一层

代码实现
public void bfs(V begin, VertexVisitor<V> visitor) {
if(visitor==null) return;
Vertex<V, E> beginVertex = vertices.get(begin);//开始顶点
if(beginVertex ==null) return;
Set<Vertex<V, E>> visitedVertexs = new HashSet<>();//存储遍历过的变量
Queue<Vertex<V, E>> queue = new LinkedList<>();
queue.offer(beginVertex);
visitedVertexs.add(beginVertex);
while(!queue.isEmpty()) {
Vertex<V, E> vertex = queue.poll();
if(visitor.visit(vertex.value)) return;
for(Edge<V, E> edge:vertex.outEdges) {
if(visitedVertexs.contains(edge.to)) continue;//判断是否已经遍历过
queue.offer(edge.to);
visitedVertexs.add(edge.to);
}
}
}
深度优先搜索(Depth First Search)
之前所学的二叉树前序遍历就是一种深度优先搜索
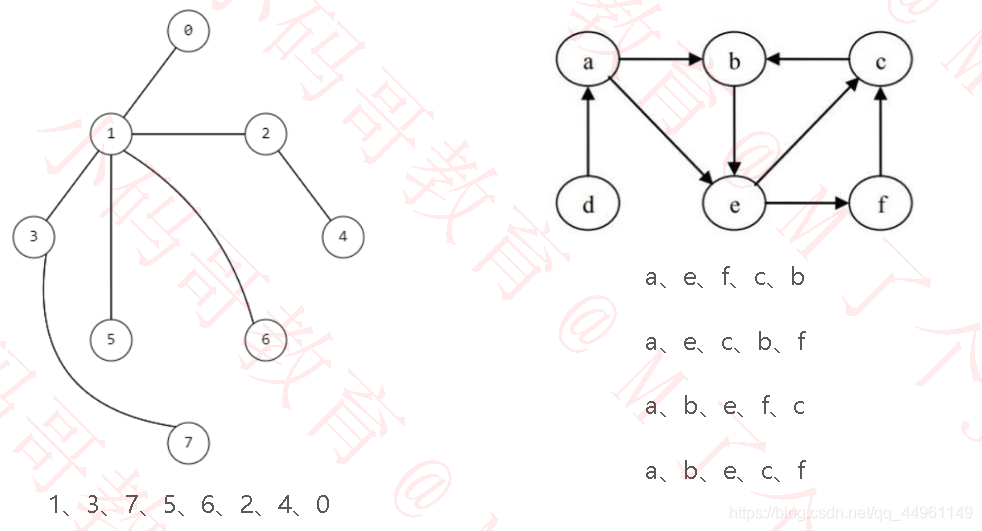
从顶点开始,选一边不断深入搜索,直到无顶点,则回溯到上一顶点再进行搜索。如由1开始,先选3顶点这条边,不断深入搜索到底,最后顶点7无法继续,则回退到上一顶点3,继续进行搜索,发现也无法继续搜索,则继续回退到顶点1,选其他的边,进行搜索。
递归实现
public void dfs2(V begin) {
Vertex<V, E> beginVertex = vertices.get(begin);
if (beginVertex == null) return;
dfs2(beginVertex, new HashSet<>());
}
private void dfs2(Vertex<V, E> vertex, Set<Vertex<V, E>> visitedVertices) {
System.out.println(vertex.value);
visitedVertices.add(vertex);
for (Edge<V, E> edge : vertex.outEdges) {
if (visitedVertices.contains(edge.to)) continue;
dfs2(edge.to, visitedVertices);
}
}
深度优先搜索–非递归实现
public void dfs(V begin, VertexVisitor<V> visitor) {
if(visitor==null) return;
Vertex<V, E> beginVertex = vertices.get(begin);
if(beginVertex == null) return;
Set<Vertex<V, E>> visitedVertices = new HashSet<>();
Stack<Vertex<V, E>> stack = new Stack<>();
// 先访问起点
stack.push(beginVertex);
visitedVertices.add(beginVertex);
if(visitor.visit(begin)) return;
while(!stack.isEmpty()) {
Vertex<V, E> vertex = stack.pop();
for(Edge<V, E> edge:vertex.outEdges) {
if (visitedVertices.contains(edge.to)) continue;
stack.push(edge.from);
stack.push(edge.to);
visitedVertices.add(edge.to);
if (visitor.visit(edge.to.value)) return;
break;
}
}
}
AOV网(Activity On Vertex Network)
一项大的工程常被分为多个小的子工程
✓子工程之间可能存在一定的先后顺序,即某些子工程必须在其他的一些子工程完成后才能开始
在现代化管理中,人们常用有向图来描述和分析一项工程的计划和实施过程,子工程被称为活动(Activity)
✓以顶点表示活动、有向边表示活动之间的先后关系,这样的图简称为AOV 网
●标准的AOV网必须是一个有向无环图(Directed Acyclic Graph,简称DAG)
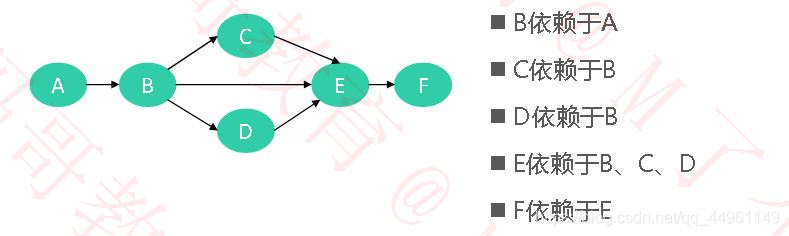
拓扑排序(Topological Sort)
●将AOV 网中所有活动排成一个序列,使得每个活动的前驱活动都排在该活动的前面
比如上图的拓扑排序结果是:A、B、C、D、E、F 或者A、B、D、C、E、F (结果并不一定是唯一的)
拓扑排序–思路
可以使用卡恩算法(Kahn于1962年提出)完成拓扑排序
●假设L 是存放拓扑排序结果的列表
①把所有入度为0 的顶点放入L 中,然后把这些顶点从图中去掉
②重复操作①,直到找不到入度为0 的顶点
如果此时L 中的元素个数和顶点总数相同,说明拓扑排序完成
如果此时L 中的元素个数少于顶点总数,说明原图中存在环,无法进行拓扑排序

public List<V> topologicalSort() {
List<V> list = new ArrayList<>();//存储返回结果
Queue<Vertex<V, E>> queue = new LinkedList<>();//存储排序顶点
Map<Vertex<V, E>, Integer> ins = new HashMap<>();//存储顶点的入度
// 初始化(将度为0的节点都放入队列)
vertices.forEach((V v, Vertex<V, E> vertex) ->{
int in = vertex.inEdges.size();
if(in==0) {
queue.offer(vertex);
}else {
ins.put(vertex, in);
}
});
while(!queue.isEmpty()) {
Vertex<V, E> vertex = queue.poll();
// 放入返回结果中
list.add(vertex.value);
for(Edge<V, E> edge : vertex.outEdges) {
int toln = ins.get(edge.to) - 1;
if(toln ==0) {
queue.offer(edge.to);
}else {
ins.put(edge.to, toln);
}
}
}
return list;
}
生成树(Spanning Tree)
也称为支撑树,连通图的极小连通子图,它含有图中全部的n 个顶点,恰好只有n –1 条边

最小生成树(Minimum Spanning Tree)
也称为最小权重生成树(Minimum Weight Spanning Tree)、最小支撑树是所有生成树中,总权值最小的那棵
适用于有权的连通图(无向)
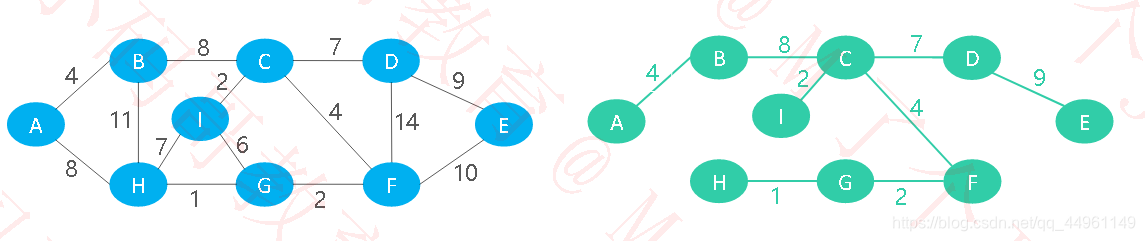
求最小生成树的2个经典算法
✓Prim(普里姆算法)
✓Kruskal(克鲁斯克尔算法)
切分定理
切分(Cut):把图中的节点分为两部分,称为一个切分
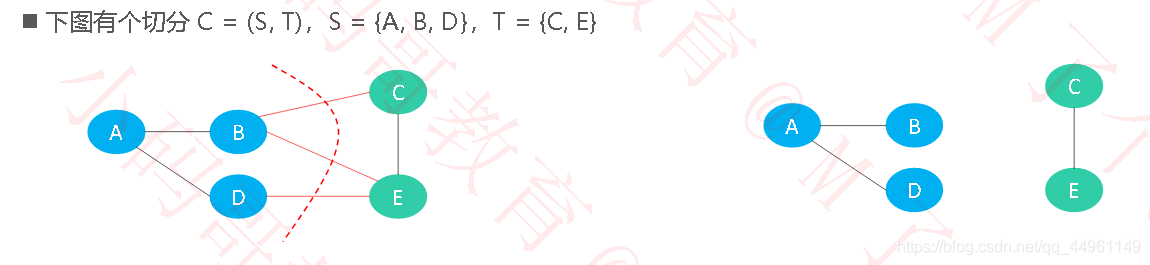
横切边(Crossing Edge):如果一个边的两个顶点,分别属于切分的两部分,这个边称为横切边,比如上图的边BC、BE、DE 就是横切边
●切分定理:给定任意切分,横切边中权值最小的边必然属于最小生成树
Prim算法–执行过程
●假设G = (V,E) 是有权的连通图(无向),A 是G 中最小生成树的边集
●算法从S = { u0}(u0∈ V),A = { } 开始,重复执行下述操作,直到S = V 为止
✓找到切分C =(S,V –S) 的最小横切边(u0,v0) 并入集合A,同时将v0并入集合S
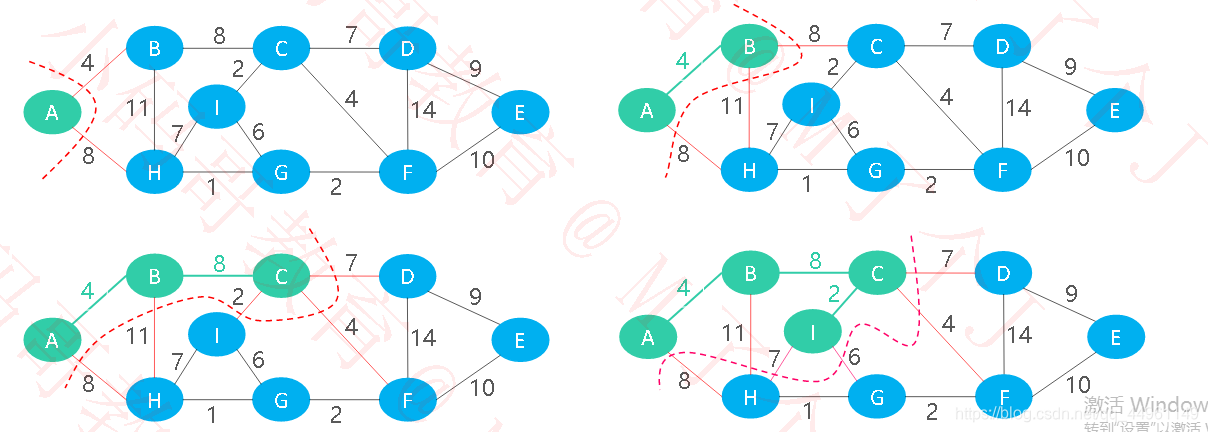
Prim算法实现

private Set<EdgeInfo<V, E>> prim() {
Iterator<Vertex<V, E>> it = vertices.values().iterator();
if (!it.hasNext()) return null;
Vertex<V, E> vertex = it.next();
Set<EdgeInfo<V, E>> edgeInfos = new HashSet<>();
Set<Vertex<V, E>> addedVertices = new HashSet<>();
addedVertices.add(vertex);
MinHeap<Edge<V, E>> heap = new MinHeap<>(vertex.outEdges, edgeComparator);
int verticesSize = vertices.size();
while (!heap.isEmpty() && addedVertices.size() < verticesSize) {
Edge<V, E> edge = heap.remove();
if (addedVertices.contains(edge.to)) continue;
edgeInfos.add(edge.info());
addedVertices.add(edge.to);
heap.addAll(edge.to.outEdges);
}
return edgeInfos;
}
Kruskal算法–执行过程
●按照边的权重顺序**(从小到大)**将边加入生成树中,直到生成树中含有V –1 条边为止(V 是顶点数量)
✓若加入该边会与生成树形成环,则不加入该边
✓从第3条边开始,可能会与生成树形成环

Kruskal算法–实现
private Set<EdgeInfo<V, E>> kruskal() {
int edgeSize = vertices.size()-1;//n-1
if(edgeSize == -1) return null;
Set<EdgeInfo<V, E>> edgeInfos = new HashSet<>();
MinHeap<Edge<V, E>> heap = new MinHeap<ListGraph.Edge<V,E>>(edges, edgeComparator);
UnionFind<Vertex<V, E>> uf= new UnionFind<>();
vertices.forEach((V v,Vertex<V,E> vertex) ->{
uf.makeSet(vertex);//初始化
});
while(!heap.isEmpty() && edgeInfos.size()< edgeSize) {
Edge<V, E> edge = heap.remove();
if(uf.isSame(edge.from, edge.to)) continue;
edgeInfos.add(edge.info());
uf.union(edge.from, edge.to);
}
return edgeInfos;
}
最短路径(Shortest Path)
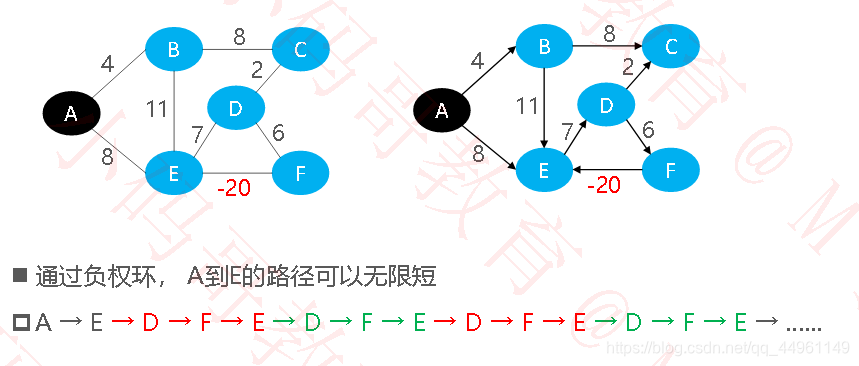
最短路径是指两顶点之间权值之和最小的路径(有向图、无向图均适用,不能有负权环)
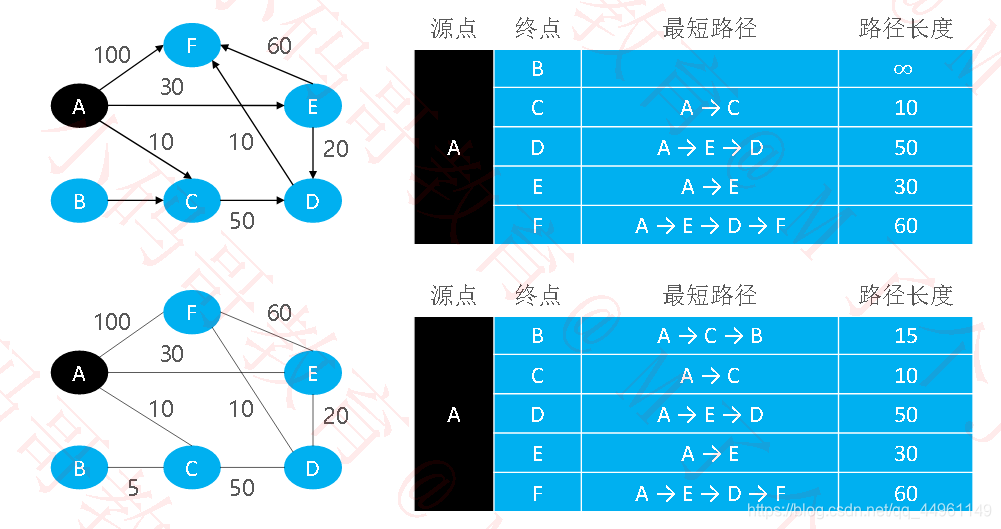
最短路径–负权边
有负权边,但没有负权环时,存在最短路径
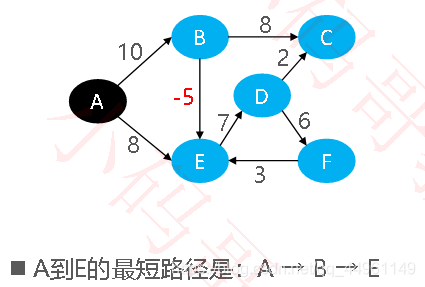
最短路径–负权环
有负权环时,不存在最短路径
求解最短路径的3个经典算法
●单源最短路径算法
✓Dijkstra(迪杰斯特拉算法)
✓Bellman-Ford(贝尔曼-福特算法)
●多源最短路径算法
✓Floyd(弗洛伊德算法)
Dijkstra –等价思考
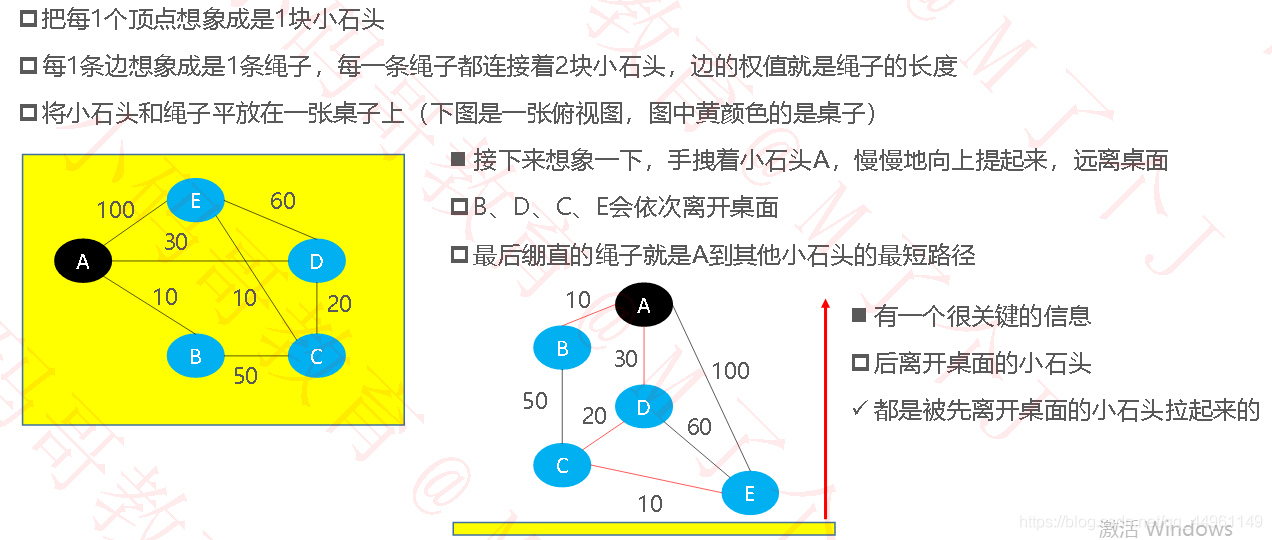
Dijkstra –执行过程
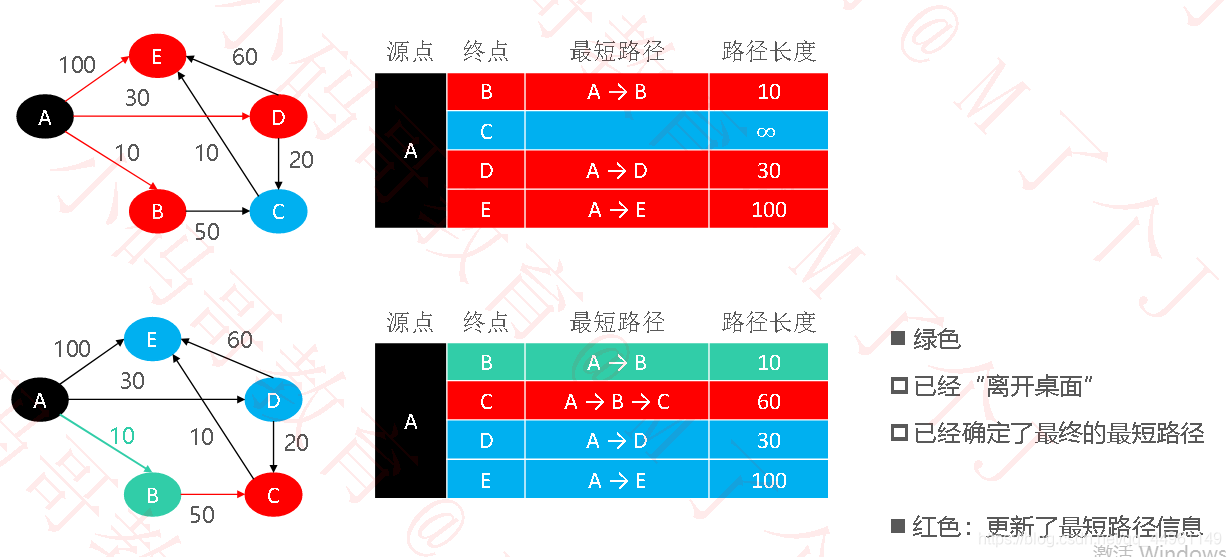
private Map<V, PathInfo<V, E>> dijkstra(V begin) {
Vertex<V, E> beginVertex = vertices.get(begin);
if(beginVertex ==null) return null;
Map<V, PathInfo<V, E>> selectedPaths = new HashMap<>();
Map<Vertex<V, E>, PathInfo<V, E>> paths = new HashMap<>();
paths.put(beginVertex, new PathInfo<>(weightManager.zero()));
// 初始化paths
// for (Edge<V, E> edge : beginVertex.outEdges) {
// PathInfo<V, E> path = new PathInfo<>();
// path.weight = edge.weight;
// path.edgeInfos.add(edge.info());
// paths.put(edge.to, path);
// }
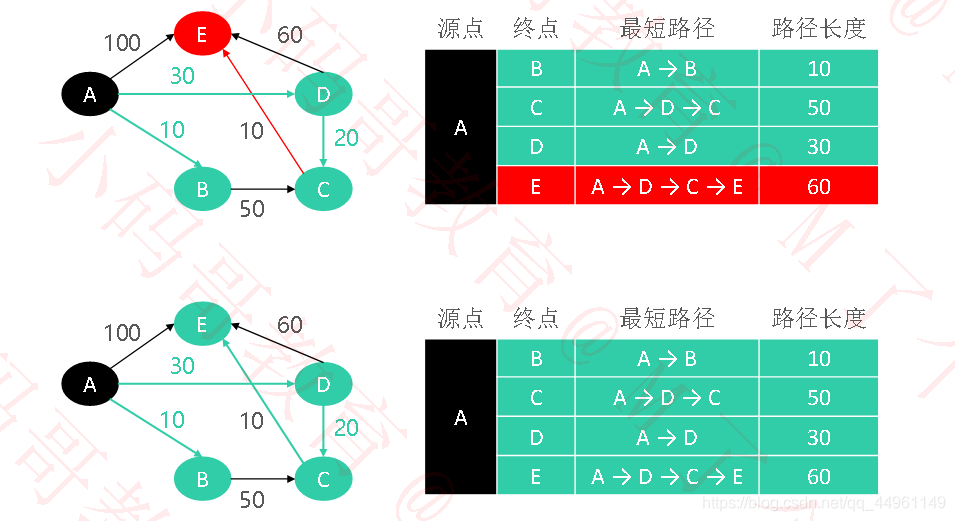
while(!paths.isEmpty()) {
Entry<Vertex<V, E>, PathInfo<V, E>> minEntry = getMinPath(paths);
// minVertex离开桌面
Vertex<V, E> minVertex = minEntry.getKey();
PathInfo<V, E> minPath = minEntry.getValue();
selectedPaths.put(minVertex.value, minPath);
paths.remove(minVertex);
// 对它的minVertex的outEdges进行松弛操作
for(Edge<V, E> edge : minVertex.outEdges) {
// 如果edge.to已经离开桌面,就没必要进行松弛操作
if (selectedPaths.containsKey(edge.to.value)) continue;
relaxForDijkstra(edge, minPath, paths);
}
}
selectedPaths.remove(begin);
return selectedPaths;
}
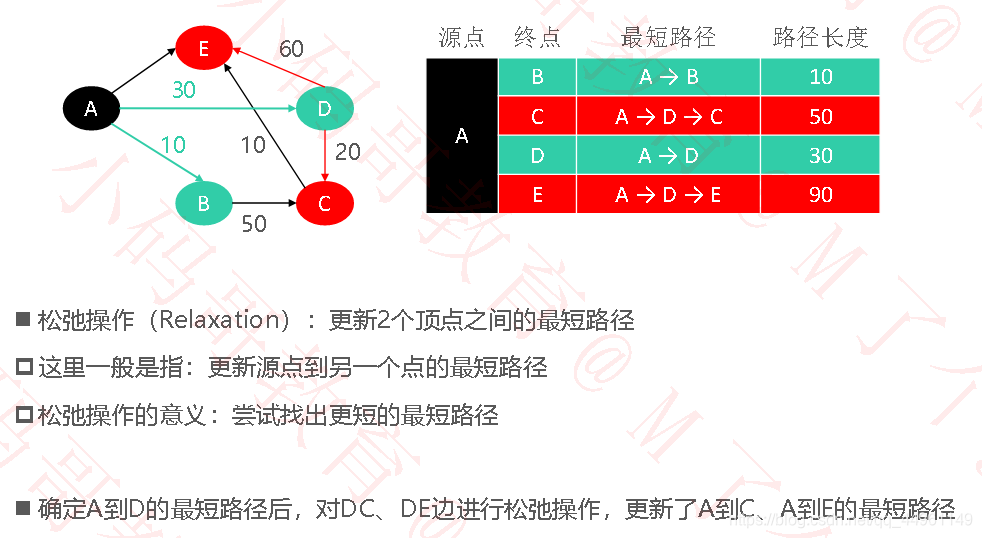
/**
* 松弛
* @param edge 需要进行松弛的边
* @param fromPath edge的from的最短路径信息
* @param paths 存放着其他点(对于dijkstra来说,就是还没有离开桌面的点)的最短路径信息
*/
private void relaxForDijkstra(Edge<V, E> edge, PathInfo<V, E> fromPath, Map<Vertex<V, E>, PathInfo<V, E>> paths) {
// 新的可选择的最短路径:beginVertex到edge.from的最短路径 + edge.weight
E newWeight = weightManager.add(fromPath.weight, edge.weight);
// 以前的最短路径:beginVertex到edge.to的最短路径
PathInfo<V, E> oldPath = paths.get(edge.to);
if(oldPath!=null && weightManager.compare(newWeight, oldPath.weight)>=0) return;
if(oldPath == null) {
oldPath = new PathInfo<>();
paths.put(edge.to, oldPath);
}else {
oldPath.edgeInfos.clear();
}
oldPath.weight = newWeight;
oldPath.edgeInfos.addAll(fromPath.edgeInfos);
oldPath.edgeInfos.add(edge.info());
}
/**
* 从paths中挑一个最小的路径出来
* @param paths
* @return
*/
private Entry<Vertex<V, E>, PathInfo<V, E>> getMinPath(Map<Vertex<V, E>, PathInfo<V, E>> paths) {
Iterator<Entry<Vertex<V, E>,PathInfo<V, E>>> iterator = paths.entrySet().iterator();
Entry<Vertex<V, E>, PathInfo<V, E>> minEntry = iterator.next();
while(iterator.hasNext()) {
Entry<Vertex<V, E>, PathInfo<V, E>> entry = iterator.next();
if (weightManager.compare(entry.getValue().weight, minEntry.getValue().weight) < 0) {
minEntry = entry;
}
}
return minEntry;
}
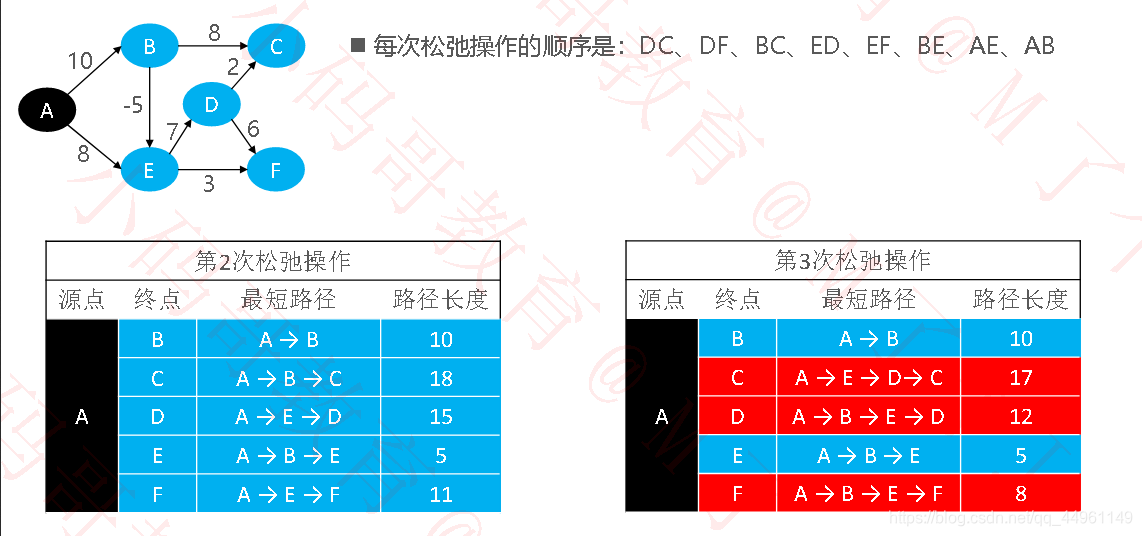
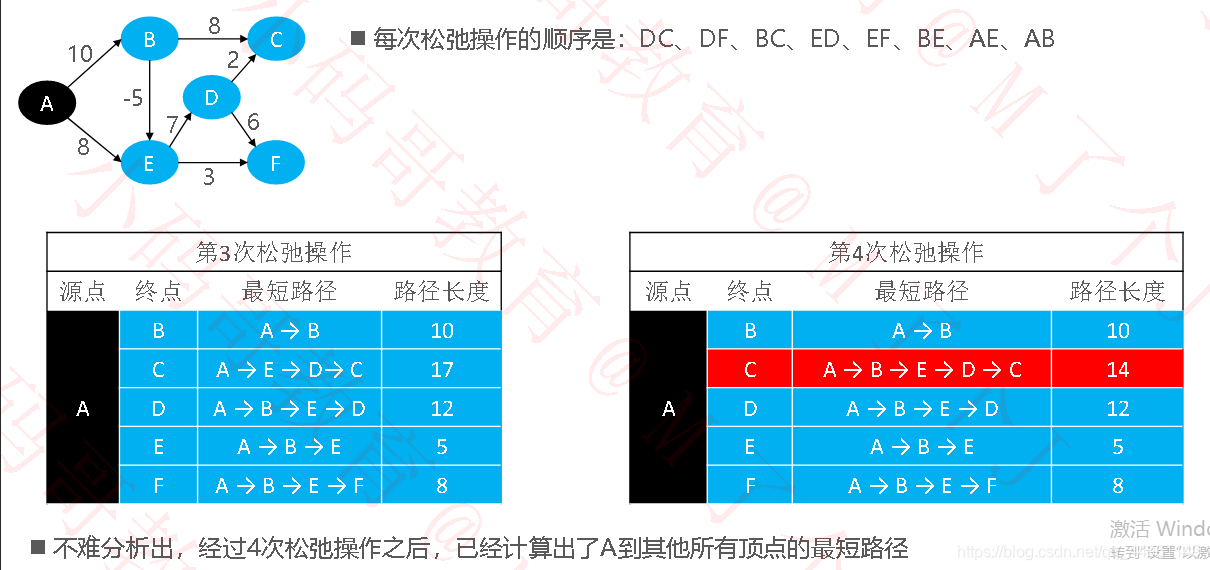
Bellman-Ford
Bellman-Ford 也属于单源最短路径算法,支持负权边,还能检测出是否有负权环
●算法原理:对所有的边进行V –1 次松弛操作(V 是节点数量),得到所有可能的最短路径
时间复杂度:OEV,E 是边数量,V 是节点数量

private Map<V, PathInfo<V, E>> bellmanFord(V begin) {
Vertex<V, E> beginVertex = vertices.get(begin);
if(beginVertex ==null) return null;
Map<V, PathInfo<V, E>> selectedPaths = new HashMap<>();
selectedPaths.put(begin, new PathInfo<>(weightManager.zero()));
int count = vertices.size()-1;
for(int i =0;i<count;i++) {//V-1次
for(Edge<V, E> edge : edges) {
PathInfo<V, E> fromPath = selectedPaths.get(edge.from.value);
if (fromPath == null) continue;
relax(edge, fromPath, selectedPaths);
}
}
for (Edge<V, E> edge : edges) {
PathInfo<V, E> fromPath = selectedPaths.get(edge.from.value);
if (fromPath == null) continue;
if (relax(edge, fromPath, selectedPaths)) {
System.out.println("有负权环");
return null;
}
}
selectedPaths.remove(begin);
return selectedPaths;
}
/**
* 松弛
* @param edge 需要进行松弛的边
* @param fromPath edge的from的最短路径信息
* @param paths 存放着其他点(对于dijkstra来说,就是还没有离开桌面的点)的最短路径信息
*/
private boolean relax(Edge<V, E> edge, PathInfo<V, E> fromPath, Map<V, PathInfo<V, E>> paths) {
// 新的可选择的最短路径:beginVertex到edge.from的最短路径 + edge.weight
E newWeight = weightManager.add(fromPath.weight, edge.weight);
// 以前的最短路径:beginVertex到edge.to的最短路径
PathInfo<V, E> oldPath = paths.get(edge.to.value);
if(oldPath != null && weightManager.compare(newWeight, oldPath.weight) >=0) return false;
if(oldPath == null) {
oldPath = new PathInfo<>();
paths.put(edge.to.value, oldPath);
}else {
oldPath.edgeInfos.clear();
}
oldPath.weight = newWeight;
oldPath.edgeInfos.addAll(fromPath.edgeInfos);
oldPath.edgeInfos.add(edge.info());
return true;
}
Floyd
Floyd 属于多源最短路径算法,能够求出任意2个顶点之间的最短路径,支持负权边
时间复杂度:O(V3),效率比执行V 次Dijkstra 算法要好(V 是顶点数量)
◼算法原理
●从任意顶点i 到任意顶点j 的最短路径不外乎两种可能
①直接从i 到j
②从i 经过若干个顶点到j
●假设dist(i,j) 为顶点i 到顶点j 的最短路径的距离
●对于每一个顶点k,检查dist(i,k) + dist(k,j)<dist(i,j) 是否成立
✓如果成立,证明从i 到k 再到j 的路径比i 直接到j 的路径短
,设置dist(i,j) = dist(i,k) + dist(k,j)
✓当我们遍历完所有结点k,dist(i,j) 中记录的便是i 到j 的最短路径的距离
public Map<V, Map<V, PathInfo<V, E>>> shortestPath() {
Map<V, Map<V, PathInfo<V, E>>> paths = new HashMap<>();
// 初始化
for (Edge<V, E> edge : edges) {
Map<V, PathInfo<V, E>> map = paths.get(edge.from.value);
if (map == null) {
map = new HashMap<>();
paths.put(edge.from.value, map);
}
PathInfo<V, E> pathInfo = new PathInfo<>(edge.weight);
pathInfo.edgeInfos.add(edge.info());
map.put(edge.to.value, pathInfo);
}
vertices.forEach((V v2, Vertex<V, E> vertex2) -> {
vertices.forEach((V v1, Vertex<V, E> vertex1) -> {
vertices.forEach((V v3, Vertex<V, E> vertex3) -> {
if (v1.equals(v2) || v2.equals(v3) || v1.equals(v3)) return;
// v1 -> v2
PathInfo<V, E> path12 = getPathInfo(v1, v2, paths);
if (path12 == null) return;
// v2 -> v3
PathInfo<V, E> path23 = getPathInfo(v2, v3, paths);
if (path23 == null) return;
// v1 -> v3
PathInfo<V, E> path13 = getPathInfo(v1, v3, paths);
E newWeight = weightManager.add(path12.weight, path23.weight);
if (path13 != null && weightManager.compare(newWeight, path13.weight) >= 0) return;
if (path13 == null) {
path13 = new PathInfo<V, E>();
paths.get(v1).put(v3, path13);
} else {
path13.edgeInfos.clear();
}
path13.weight = newWeight;
path13.edgeInfos.addAll(path12.edgeInfos);
path13.edgeInfos.addAll(path23.edgeInfos);
});
});
});
return paths;
}
private PathInfo<V, E> getPathInfo(V from, V to, Map<V, Map<V, PathInfo<V, E>>> paths) {
Map<V, PathInfo<V, E>> map = paths.get(from);
return map == null ? null : map.get(to);
}