文章目录
Refenence:
1. Effective Approaches to Attention-based Neural Machine Translation
Machine Translation, MT
MT is the task of translating a sentence
from one language to a sentence
in another language.
1950s: Early Machine Translation
Machine translation research in early 1950s. Systems were mostly rule-based, using a bilingual dictionary to map Russian words to their English counterparts.
1990s-2010s: Statistical Machine Translation
Core idea is learn a probabilistic model form data, i.e. we want to find best English sentence
, given French sentence
:
Here is a translation model, is a language model.
Learning Alignment for SMT
How to learn translation model
from the parallel corpus?
Break it down further: we actually want to consider:
where is the alignment, i.e. word-level correspondence between French sentence and English sentence .
Alignment is complex
Alignment is the correspondence between particular words in the translated sentence pair:


Learn as a combination of many factors, including:
- Probability of particular words aligning (also depends on position in sent).
- Probability of particular words having particular fertility (number of corresponding words).
Decoding for SMT
Considering the translation model:

We could enumerate every possible and calculate the probability? Too expensive! A simplified idea is use a heuristic search algorithm to search for the best translation, discarding hypotheses that are too low-probability.

|

|
The best SMT systems were extremely complex, such as:
- Lots of feature engineering.
- Like tables of equivalent phrase, etc.
Neural Machine Translation, NMT
Sequence to sequence model:
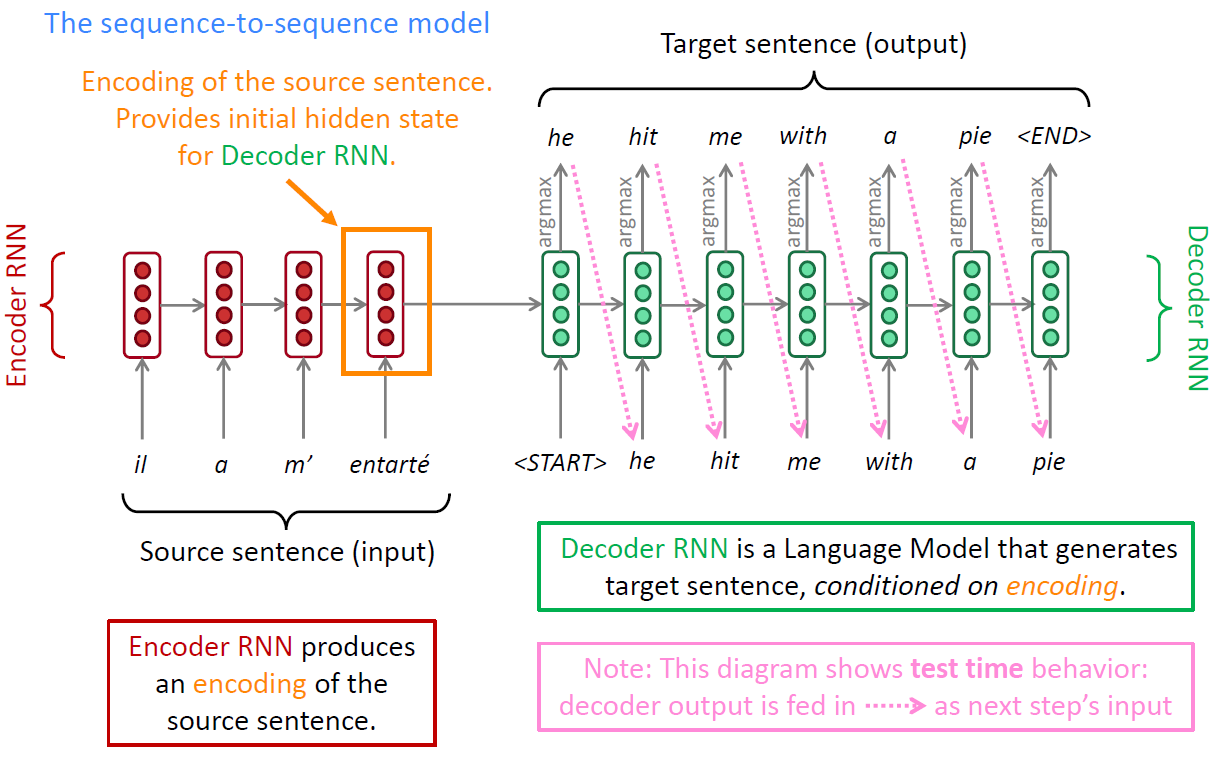 seq2seq translation model seq2seq translation model
|
 training a NMT model training a NMT model
|
NMT Training
The seq2seq model is an example of a Conditional Language Model. Decoder predicts the next word of the target sentence
conditioned on the source sentence
(encoder hidden state).
NMT directly calculates
, NMT is generative model unlike SMT which is discriminative model:
Seq2Seq is optimized as a single system. Backpropagation operates “end-to-end”.
NMT Greedy Decoding
Greedy decoding that takes most probable word on each step of the decoder by taking argmax .
 greedy decoding greedy decoding
|
 prolems with greedy decoding prolems with greedy decoding
|
Beam Search Decoding
Find the optimal target sentence by exhaustive search all possible sequences , complexity, is far too expensive.
The core idea of beam search decoding is on each step of decoder, keep track of the most probable partial translations (which we call hypotheses), k is the beam size around 5 to 10 in practice. Beam search is not guaranteed to find optimal solution, but much more efficient.

Stopping Criterion
In greedy decoding, usually we decode until the model produces a token.
In beam search decoding, different hypotheses may produce token on different timesteps. When a hypothesis produces , that hypothesis is complete. Place is aside and continue exploring other hypotheses via beam search.
Usually we continue beam search until: we reach timestep , or we have at least completed hypotheses ( and is some pre-defined cutoff.).
How to select top one with highest score?
Problem with this evaluation criteria: longer hypotheses have lower scores.
Fix: Normalize by length, use this to select top one instead:
Advantages of NMT
NMT has many advantages compared to SMT: better performance, more fluent, better use of context, better use of phrase similarities, requires much less human engineering effort.
Challenges of NMT
Many difficulties remain: out-of-vocabulary words, domain mismatch between train and test data, maintaining context over longer text.
Attention
Using one encoding vector of the source sentence to decode/translate the target sentence, which needs to capture all information about the source sentence. This is information bottleneck.
Attention core idea: on each step of the decoder, use direct connection to the decoder to focus on a particular part of the source sequence.
Sequence-to-Sequence with Attention
Use attention distribution to take a weighted sum of the encoder hidden states, thus the decoder can decide (by self learning) which states to use to predict next word.
Attention provides some interpretability, we can see what the decoder was focusing on!

|

|
On each step :
-
Use the decoder hidden state (query vector) with each encoder hidden state to compute the attention scores (N timesteps).
-
Take softmax to get the attention distribution .
-
Use to take a weighted sum of the overall encoder hidden states to compute the attention output (global context vector), overall all the source states.
-
Employ a simple concatenation layer to combine the information from both vectors to produce an attentional hidden state.
-
The attention vector is then fed through the softmax layer to produce the predictive distribution:
Implementation with Tensorflow
以下实现仅对于多分类任务,非NMT任务
def attention(inputs, inputs_size, atten_size):
"""
atten_inputs:
(batch_size, max_time, hidden_size)
expression:
u = tanh(w·h+b)
alpha = exp(u^t·v)/sum(exp(u^t·v))
s = sum(alpha·h)
"""
hidden_size = int(inputs.shape[2])
w = tf.Variable(tf.random_normal([hidden_size, atten_size]))
b = tf.Variable(tf.random_normal([atten_size], stddev=0.1))
v = tf.Variable(tf.random_normal([atten_size], stddev=0.1))
# [batch_size, max_times, atten_size]
u = tf.tanh(tf.matmul(inputs, w) + b)
# [batch_size, max_times]
uv = tf.linalg.matvec(u, v) / 2.0
# set the alpha of padding symbol to zero by add negtive infinity number
mask = tf.sequence_mask(inputs_size, max_len=TIME_STEPS, dtype=tf.float32)
uv_mask = uv + tf.float32.min * (1- mask)
alphas = tf.nn.softmax(uv_mask, axis=1)
# [batch_size, max_times]
# alphas = tf.exp(uv) * mask
# alphas = alphas / tf.expand_dims(tf.reduce_sum(alphas, axis=1), -1)
output = tf.reduce_sum(tf.multiply(inputs, tf.extend_dims(alphas, -1)), axis=1)
return alphas, output